
[cs231n] CNN Architectures - AlexNet, VGG, GoogLeNet, ResNet
업데이트:
개요

이번 포스팅에서는 ImageNet challenge에서 발전되어온 CNN 기반 model들이 어떤 아이디어로 개발되었고, 구조는 어떻게 생겼는지에 대한 구조에 대한 내용이다.
ImageNet Challenge
ImageNet은 대규모의 이미지 데이터셋으로 약 1,000만개의 dataset과 1,000개의 label을 갖고 있다(1k). 이러한 데이터셋을 이용해서 image classifier의 성능을 겨루는 대회가 바로 ImageNet Large-Scale Visual Recognition Challenge (ILSVRC)이다.
아래 그림은 대회가 시작된 2010년부터 2017년까지 우승했던 model들을 보여준다. 2017년에는 error rate이 약 2.3%까지 개선되었으며(인간의 error는 약 5.1%), model의 깊이도 조금씩 deep해진 것으로 보인다.
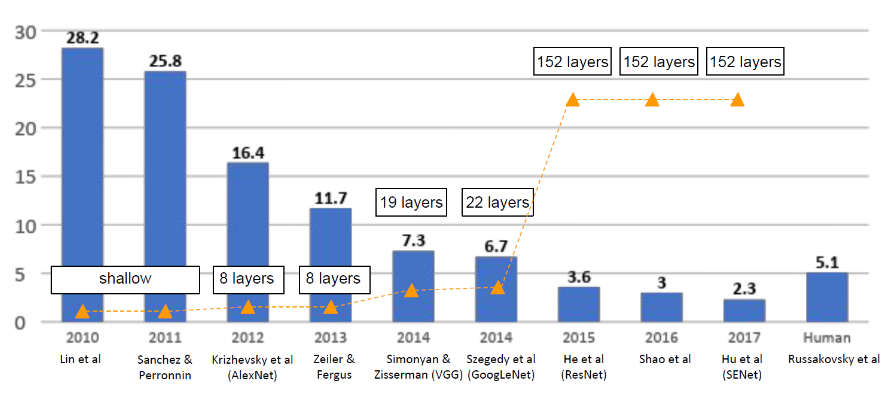
이전에 포스팅했던 CNN에 대한 기초적인 내용을 기반으로 각 model들이 어떤 구조를 갖고 있는지 살펴보자.
AlexNet
AlexNet은 2012년에 처음으로 CNN기반의 Deep neural network를 적용하여, 기존 대비 Error rate을 획기적으로 개선하였다.
Paper는 Krizhevsky et al. (2012) ImageNet Classification with Deep Convolutional Neural Networks이다.
Main Idea
AlexNet은 Convolutional layer를 처음으로 깊게 쌓아 성능을 올렸다는 데에 의미를 두고 있으며, 이후로 CNN을 기반으로한 model들이 계속 연구되는 계기가 된다.
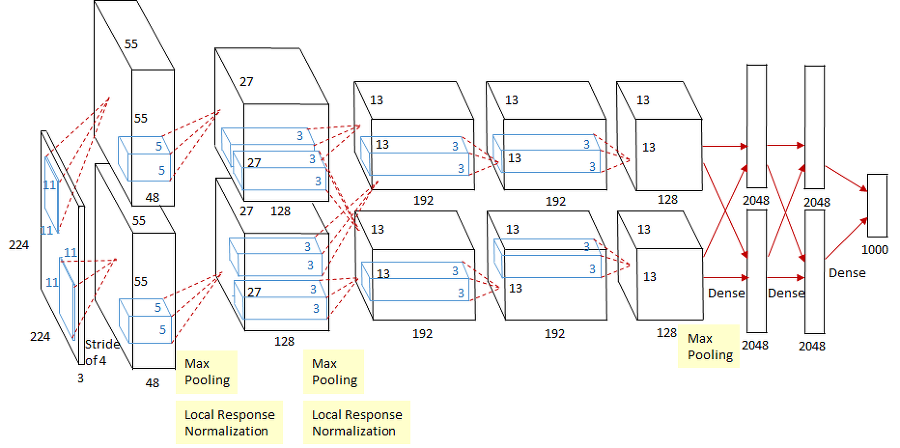
AlexNet의 structure는 8개 layer로 아래와 같이 구성된다.
Layer는 학습가능한 weight이 있는 Layer(Conv, FC)들을 의미한다.
Conv1-Maxpool1-Norm1Conv2-Maxpool2-Norm2Conv3Conv4Conv5Maxpool3FC6FC7FC8
즉, Conv1-Pool-Norm으로 이루어진 2개의 layer와 그냥 Conv 2개, FC(Fully-connected) layer 3개로 이루어져 있다.
아래와 같이 논문에서는 사용된 각 layer의 구체적인 내용과 filter에 대한 parameter들을 제시해 주고 있다.

이를 통해 종합해보면 아래와 같이 input과 output size를 계산해볼 수 있다.
Conv layer의 Filter에 따른 size 계산은 (N-F+2P)/stride + 1로 할 수 있다.
자세한 내용은 이전포스팅을 참고하자.
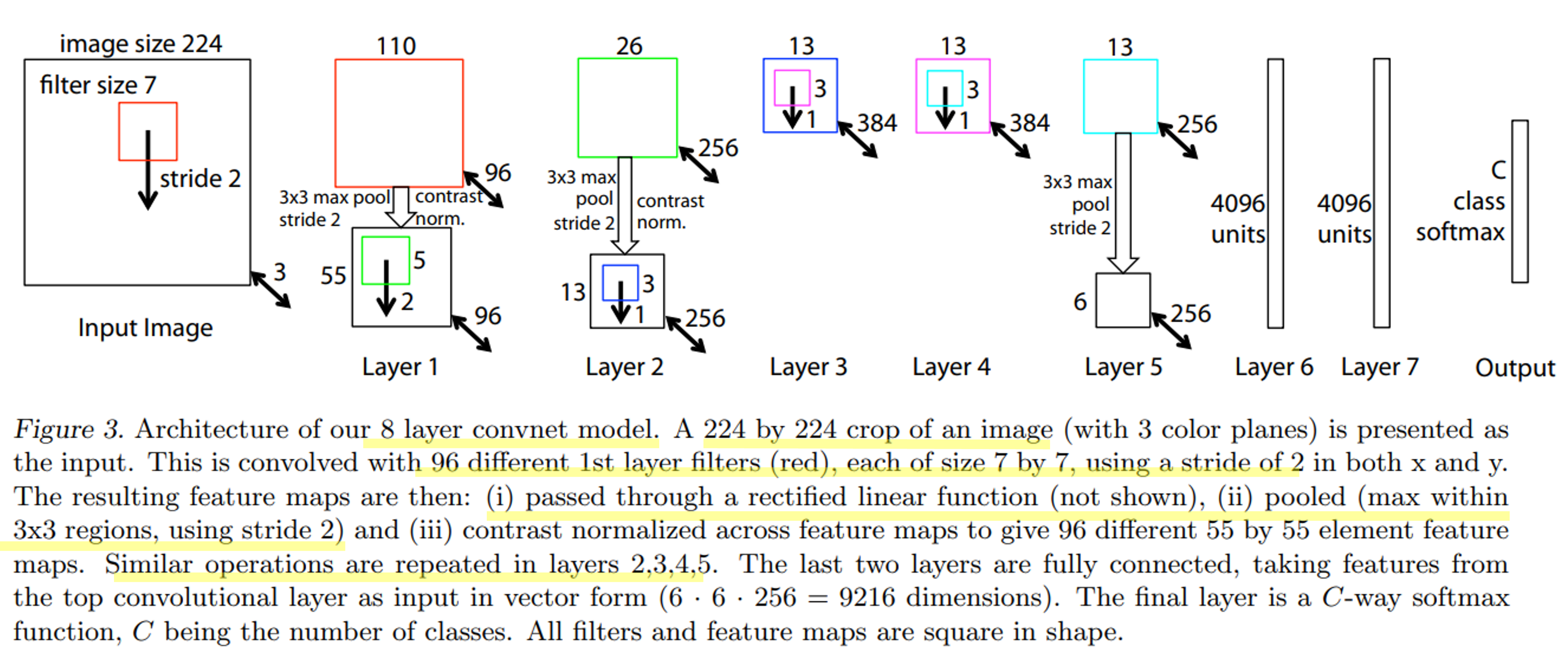
input image는 원래 224x224x3 인데, 논문에 명시된 바와 같이 conv1 layer를 타고나면 55가 나올수 없다. 저자들의 오타라는 얘기도 있고, padding을 1.5로 줬다는 말도 있는데 강의에서는 input image가 227이 였던 것으로 설명한다.
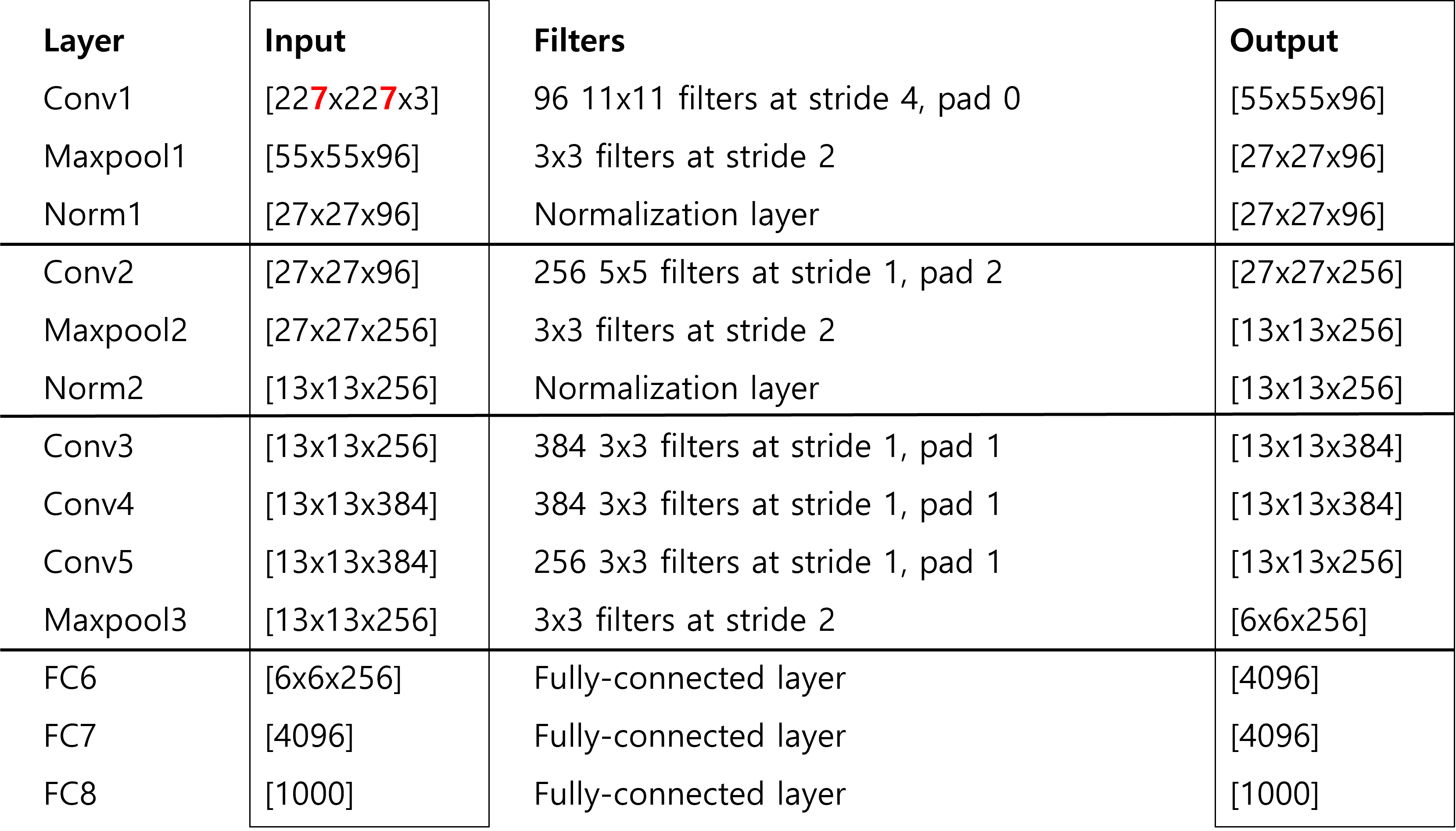
Conv1을 제외하고는 conv layer를 타더라도 output size를 유지하도록 filter를 설정하고, pooling layer에서 size가 줄어들도록 하였다.
간단한 질문들
- Conv1의 parameter 수?
(11x11x3)x96(bias 미포함)
- Maxpool1의 parameter 수?
0(파라미터 없음)
또한 앞의 model structure에 figure를 보면 AlexNet은 2개의 분리된 Network로 이루어진 것을 알 수 있는데, 단지 GPU 메모리를 고려하여 나눠서 학습하였다고 한다.
예를들어 Maxpool1 layer는 위 표와 같이 55x55x96이지만, figure에서는 55x55x48이 2개로 분리되어 있는 것을 알 수 있다.
Details
Alexnet의 structure외에 세부적인 사항과 의의들을 아래와 같이 제시하고 있다.
링크되어 있는 앞서 배운 내용들을 토대로 이해하면 좋을 것 같다.
- first use of ReLU
- used Norm layers (not common anymore)
- heavy data augmentation
- dropout 0.5
- batch size 128
- SGD+Momentum 0.9
- Learning rate 1e-2, reduced by 10 manually when val accuracy plateaus
- L2 weight decay 5e-4
- 7 CNN ensemble: 18.2% -> 15.4%
ZFNet
ZFNet은 다음해인 2013년에 우승한 모델로 AlexNet를 약간 튜닝을 해서 성능을 개선했다고 한다.
Paper는 Zeiler and Fergus (2013) Visualizing and Understanding Convolutional Networks이다.
ZFNet은 아래 그림과 같이 기존 AlexNet의 model structure를 거의 그대로 따라가되, Conv layer의 hyperparameter를 살짝 수정(Filter의 개수나 size 정도)하여 개선했다.
Conv1: (11x11 stride 4)에서 (7x7 stride 2)로 변경Conv3,4,5: filter 수를 384, 384, 256에서 512, 1024, 512로 각각 변경
정확도는 16.4%(AlexNet)에서 11.7%로 개선되었다.
VGG Net
VGG Net은 2014년에 2위를 한 모델로, 더 작은 filter size와 더 deep한 neural network로 진화되는 경향을 보인다.
Paper는 Simonyan and Zisserman (2015) Very Deep Convolutional Networks for Large-scale Image Recognition이다.
Main Idea
VGG Net의 model structure은 아래 그림과 같고, 기존 모델 대비 변화한 2가지 특징이 있다.
layer의 개수에 따라 VGG16과 VGG19라고 명명하고 있다.
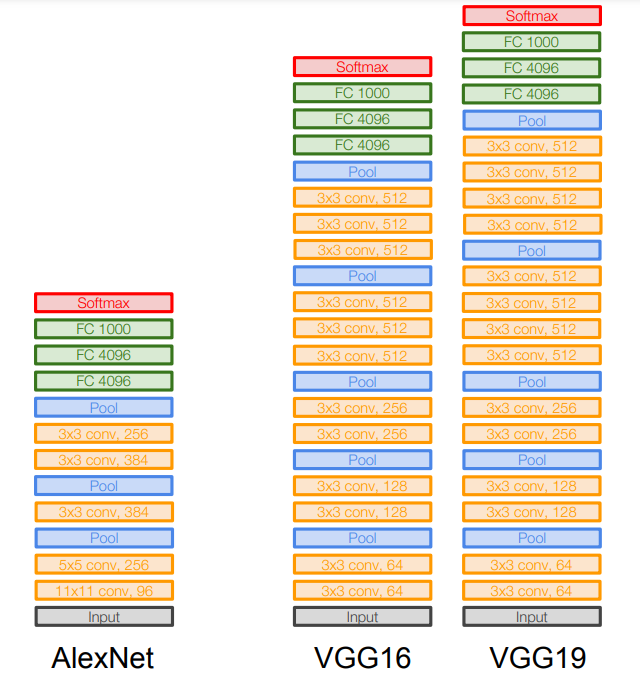
3x3filter만 사용한다.3x3 CONV stride 1, pad 1와2x2 MAX POOL stride 2만 사용
- 더 깊게(Deeper) layer을 쌓는다.
위 2가지 핵심 Idea는 어떤 효과가 있을까??
이는 아래 그림과 같이 CNN에서 Filter의 Receptive field의 효과**를 살린 것이라고 볼 수 있다.
**Receptive field는 Filter가 한번 훑을때 보는 영역으로 영역이 클수록 input image의 많은 특징을 잡아낼 수 있다.
그러나 이를 위해 filter size를 키울수록 FC layer와 같아져 overfitting 및 연산의 효율성이 저하된다.
따라서 Receptive field는 넓게 가져가면서 위와 같은 문제를 막기 위한 방법이 VGG에서 제안되었다.
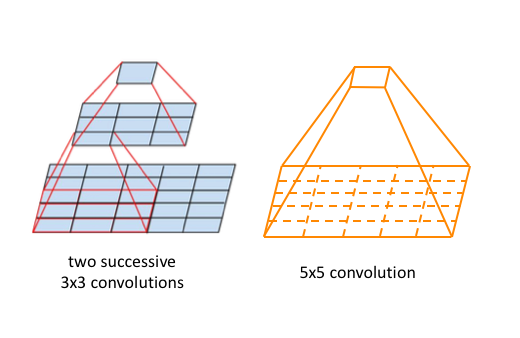
Source: Common architectures in convolutional neural networks
3x3 filter의 conv layer를 2번 쌓는 것은, 1개의 5x5 layer와 같은 효과를 얻을 수 있다(3번 쌓으면 7x7).
일반화하면 3x3 filter를 n개 쌓으면, 1개의 (2n+1)x(2n+1) layer와 같아진다.
그림의 하단부 부터 3x3으로 convolution을 진행한다고 할때, 결국 상단의 cell 하나가 5x5까지의 영역(receptive field)을 볼 수 있게 되는 것이다.
이를통해 receptive field만 같은 효과를 가지는 것 뿐 아니라, 학습해야할 parameter 수도 줄어든다.
이는 filter size가 커짐에 따라 더 큰 차이가 생긴다.
7x7filter 1 layer: $1 \times(7\times7)\times C^2=49C^2$3x3filter 3 layer: $3 \times(3\times3)\times C^2=27C^2$
$C^2$인 이유는 논문에서 위 예시 설명을 위해 input channel과 output channel이 $C$로 동일하다고 가정했기 때문이다.
이전 포스팅에서 parameter 계산은 K(F^2C+1)로 한다고 했었는데(input image에서 넘어가는 것만 설명되었음), 더 정확하게는 K가 output channel의 수, C가 input channel의 수를 의미한다.
이밖에도 layer가 더 deep해짐에 따라 non-linearity가 더 반영되기 때문에, 복잡한 관계를 표현하는데 효과적이게 된다.
VGG Net의 특징을 정리하면 다음과 같다.
3x3conv layer를 깊게 쌓아7x7과 동일한 receptive field 효과를 낸다.- 학습이 필요한 parameter를 줄이는 효과가 있다.
- 동시에 layer가 많아짐에 따라 비선형성을 더 반영할 수 있다.
따라서 VGG의 model structure은 아래 그림과 같이 3x3 conv layer로만 구성된다.

총 Memory는 이미지 당 96MB가 필요하며(forward에만), parameter 수는 138백만(million)개이다.
Memory의 경우 초반에 큰 image를 convolution 해야하기 때문에 앞단의 conv layer에서 제일 많이 잡아먹고, Parameter 수는 FC layer가 가장 많이 차지한다.
Details
VGG Net의 세부적인 사항과 의의는 아래와 같다.
- ILSVRC’14 2nd in classification, 1st in localization
- Similar training procedure as Krizhevsky 2012
- No Local Response Normalisation (LRN)
- AlexNet에서 사용되었던 Layer를 제외
- Use VGG16 or VGG19 (VGG19 only slightly better, more memory)
- Use ensembles for best results
- FC7 features generalize well to other tasks
- 앞의 structure에서 FC7 layer가 다양한 task에도 잘 generalization이 된다고 한다(이미지를 잘 representation 하는 feature).
- Dropout 0.5 for FC6, FC7
- Batch size 256
- SGD + Momentum 0.9
- Initial learning rate 0.01, reduced to 1/10 twice.
- L2 weight decay 5e-4
GoogLeNet
GoogLeNET은 2014년 우승 모델로 VGG Net보다 조금 더 깊은 22 layer를 가지고 있고, inception module을 도입해 structure를 획기적으로 변화시킨다.
Paper는 Szegedy el at. (2014) Going deeper with convolutions이다.
Main Idea
GoogLeNet의 핵심은 아래 그림과 같이 inception module이라고 하는 parallel한 filter를 도입했다는 것이다.
inception module은 전체 network 안에 작은 network(local network topology)를 두고, 다시 concatenate 해서 output으로 내보내는 형태로 구성되어 있다.
이는 기존에 하나의 layer로만 deep하게 쌓았던 방식과 다른 구조이다. 특정 level의 layer가 같은 filter size로만 학습해야되는 문제를 개선하고 여러 size의 filter를 가진 block으로 유연하게 학습해보려는 시도라고 할 수 있다.
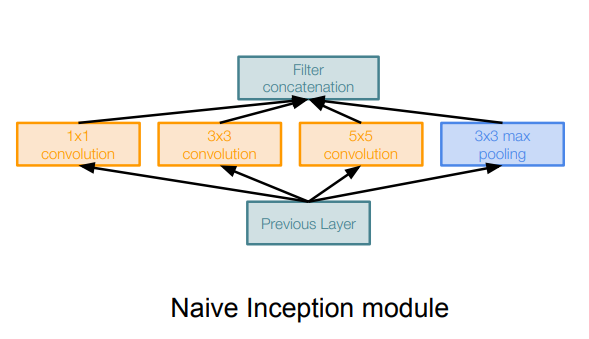
하지만 이런식으로 구성하면, computational complexity 문제가 생긴다.
이대로 convolution을 수행하면 아래와 같다. same size padding으로 size는 유지되고 fiter의 output channel에 따라 중간에 쌓이게 되고, 최종적으로 depth(channel)-wise로 concatenation이 된다.
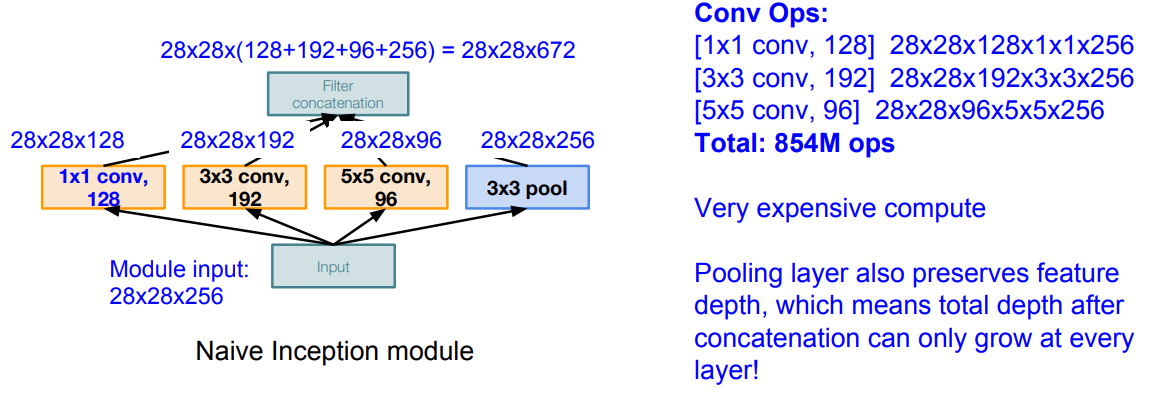
이와 같이 이상태로 layer를 쌓게 되면 parameter 수 뿐 아니라, 연산량(input과 output의 dimension의 곱에 비례) 많아져서 연산이 비효율적인 문제가 생긴다.
따라서 여기에 더해진 idea가 “bottleneck layer” 이다. 이는 CNN 포스팅에서 다루기도 했었는데, 아래와 같이 1x1 conv layer를 이용하면 공간 차원은 유지하면서 channel-wise로 diemension reduction을 할 수 있다.
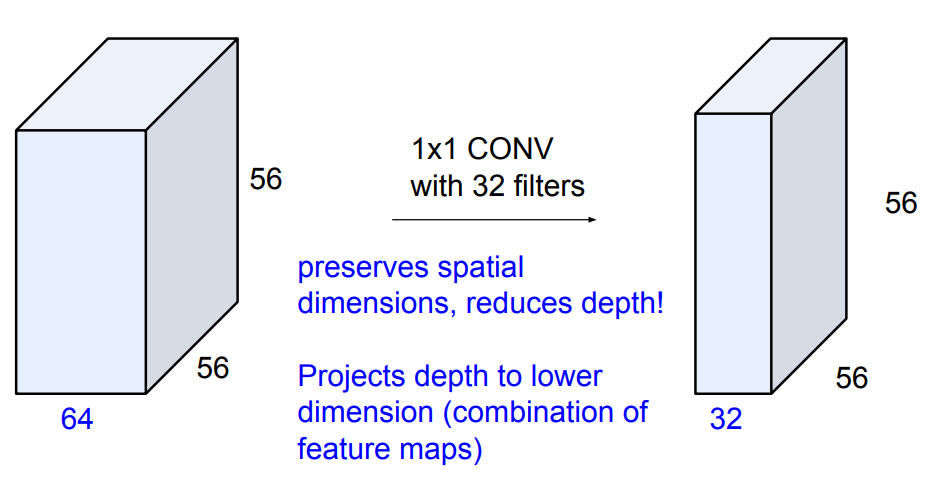
따라서 1x1 conv layer를 기존 module의 중간에 넣어서 차원을 축소하고, 연산량을 개선한다.
이를 통해 최종적으로는 아래와 같이 conv layer에서 발생하는 연산량(operations)을 854M에서 358M으로 줄인다.

이러한 inception module을 깊게 쌓아 올린 것이 바로 GoogLeNet이다. 이 외에도 몇가지 treatment가 있는데, 아래의 full structure을 보면서 하나하나 알아보자.
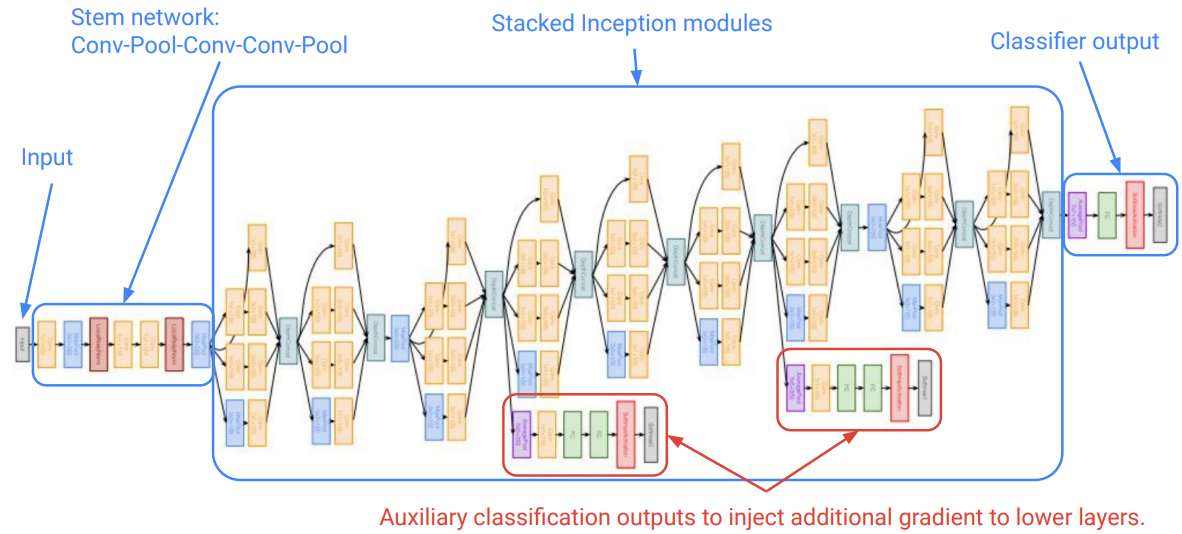
- Stem network
- 초반에는 기존 CNN 기반 model들에서 주로 사용했던 layer들을 이용한다.
Conv-Pool-Conv-Conv-Pool
- Stacked Inception modules
- inception module을 9개를 쌓아 올린다.
- Classifier output
- 기존처럼 FC로 빼지 않고, Average pooling을 이용한다.
- FC가 항상 많은 complexity를 잡아먹었기 때문에 최대한 배제하려고 했다.
- Previous layer(
7x7xC)-AveragePool(1x1xC)-FC(1x1xk)-Softmax
- Auxiliary classifier
- 모델이 deep해짐에 따라 backpropagation을 할 때 gradient가 사라지는 문제를 피하기는 어렵다.
- 따라서 model 중간중간에 classify를 하고 loss를 받아가는 형태로 구성한다.
- (가장 마지막 loss보다는 가중치를 낮게 준다고함)
- AvgPool-
1×1Conv-FC-FC-Softmax
Details
GoogLeNet의 세부적인 사항과 의의는 아래와 같다.
- Winner of ILSVRC (2014): 1st in classification
- 22 layers (9 inception modules × 2 layers + 3 conv in stem network + 1 FC)
- Efficient “Inception” module
- No FC layers
- 12x less params than AlexNet
- 27x less parameters than VGG-16
- Data augmentation: random cropping of images (8% - 100%) + some more advanced approaches
- SGD + Momentum 0.9
- Learning rate reduced by 4% for every 8 epochs.
ResNet
ResNet은 2015년에 우승한 Microsoft의 모델로 152 layer로 구성되어 기존보다 급격하게 깊어진 structure를 가지고 있다.
Paper는 He el at. (2015) Deep Residual Learning for Image Recognition이다.
Main Idea
시간이 지남에 따라 연구자들은 model을 깊게 쌓는 것이 성능이 좋아질 것을 기대하고 있었다. deep해지더라도 일부 layer들은 알아서 가중치가 적어져 이론상으로는 최소한 얕은(shallow) 모델의 성능은 나와야 할 것이다.
그러나 깊게 쌓는다고 항상 성능이 좋아지진 않는다는 것을 알게 된다.
그 이유는 overfitting일 수도 있고 GoogLeNet에서의 이슈처럼 backpropagation을 통해 gradient가 앞단까지 잘 전달이 되지 않을 수 있다(vanishing gradient).
아래 그림은 논문에서 2개의 모델 성능을 비교한 결과이다.
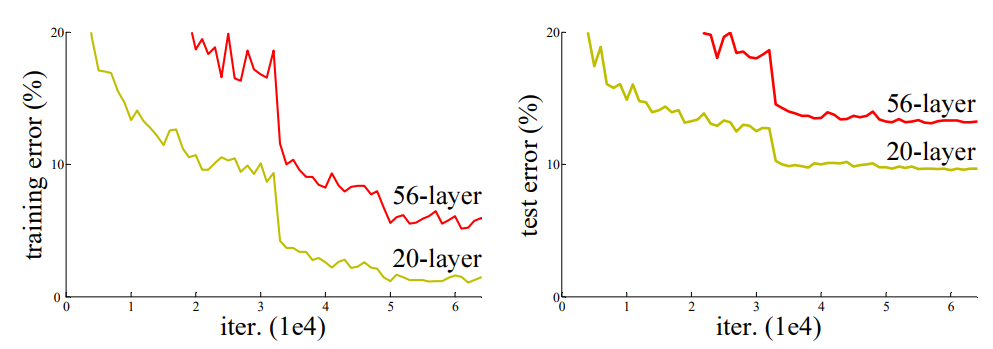
56-layer와 20-layer를 비교했을때, 오히려 더 얕은 모델(20-layer)이 더 성능이 좋은 것을 알 수 있다. 또한 train과 test dataset에서 같은 양상을 보여 overfitting 문제는 아닌 것으로 판단된다.
이에 따라 저자들은 deep한 model일수록 optimize가 어렵다는 가설을 세우고,
불필요하게 deep하다면 skip할 수 있도록 edge가 추가된 residual block을 만든다.
아래 그림과 같이 residual block은 기존 conv layer(F(x))와 input을 그대로 전달하는 identity(x)로 구성되어 있다.
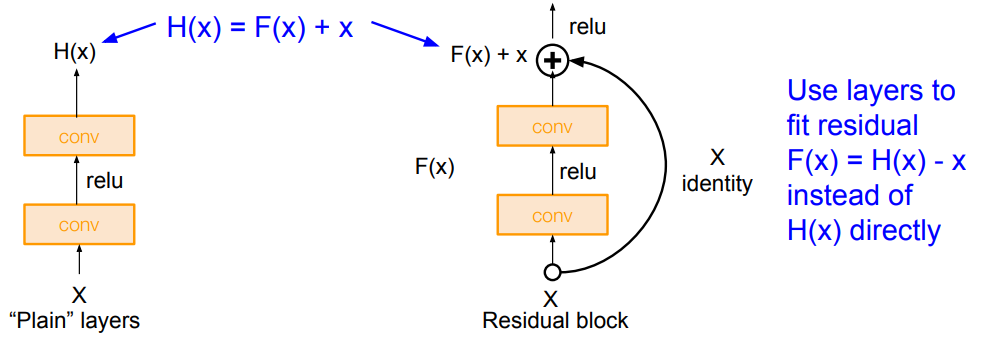
이 개념이 약간은 헷갈리지만, 논문의 내용과 Kanghee Lee님의 블로그에서 댓글로 친절하게 설명해주신 내용으로 이해했다.
기존 CNN 모델은 왼쪽 그림 처럼 x가 input(이전 layer의 output)으로 들어올 때, 이 값이 어떤 함수(H(x))를 통해 매핑되어 target인 y와 같아지도록 학습된다(즉, H(x)-y=0).
반면 ResNet에서는 skip connection을 두어 H(x)=F(x)+x의 형태로 매핑하고, F(x)가 0이 되도록 학습한다.
*F(x)가 0이 되도록 학습하는 이유로 저자는 기존 모델처럼 특정 값인 y보다 0을 목표로 하는 것이 학습이 잘된다고 언급하고 있다.
F(x)를 다시 쓰면 F(x)=H(x)-x가 되고, 이는 output과 input과의 차이 형태로 나타나므로 Residual learning 이라고 부르게 된다.
이러한 구조는 input인 x가 있어서 gradient를 구할때 최소한 1이상을 보장하기 때문에(relu의 gradient는 0 or 1), vanishing problem을 피할 수 있다.
전체 ResNet의 structure와 특징들은 아래와 같다.
- 처음에는 conv layer로 시작
- residual block은 2개의
3x3conv layer로 이루어진다. - 주기적으로 stride 2를 줘서 spatial하게 downsampling하고, filter 수는 2배로 늘린다.
- 마지막은 GoogLeNet과 마찬가지로 Avgpooling을 하고 FC layer 하나로 마무리한다.
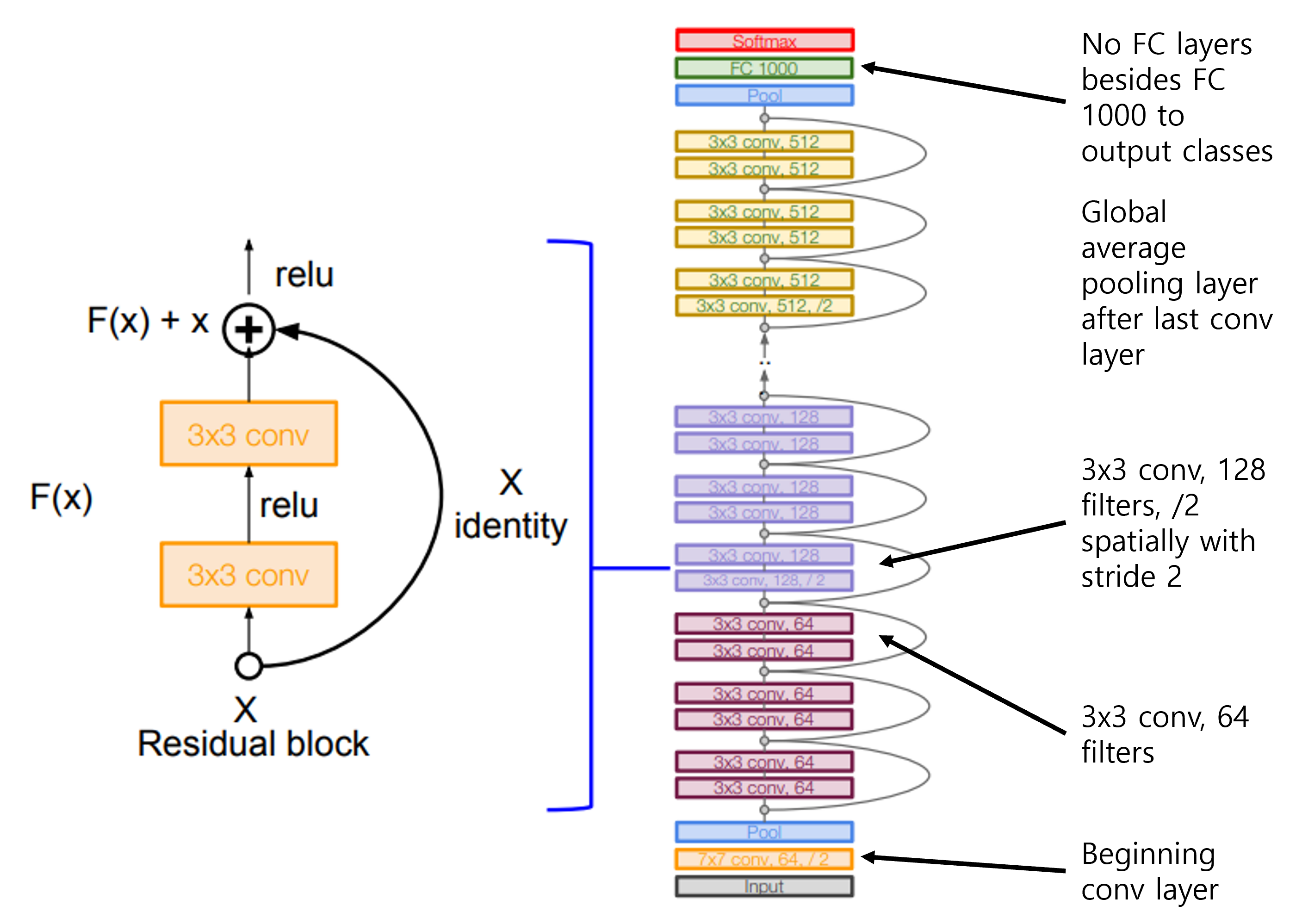
ResNet은 layer 수에 따라(34,50,101,152) ResNet50과 같이 이름이 붙여진다.
그리고 ResNet50 이상부터는 GoogLeNet과 마찬가지로 여기서도 연산 효율성을 더 개선하기 위해, 각 residual block에 bottleneck이 추가된다.
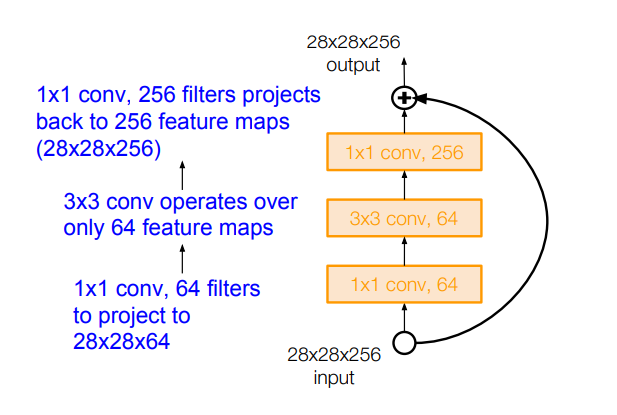
마찬가지로 block 내에 1x1 conv layer를 넣어 차원을 줄여주는 방식이다. 앞단에서는 차원을 줄인 상태로 convolution을 하도록 해주고, 뒷단에서는 input과 output의 차원을 맞춰주기 위해 다시 256으로 늘려준다.
그 이유는 H(x)=F(x)+x에 따라 +연산을 위해서는 차원이 동일해야하기 때문이다.
Details
ResNet의 세부적인 사항과 의의는 아래와 같다.
- Winner of ILSVRC (2015) and COCO (2015)
- First result (3.6%) that is better than human (5.1%)
- Batch Normalization after every CONV layer
- batch norm을 본격적으로 사용하고, dropout을 제외함
- Xavier/2 initialization from He et al.
- SGD + Momentum (0.9)
- Learning rate: 0.1, divided by 10 when validation error plateaus
- Mini-batch size 256
- Weight decay of 1e-5
- No dropout used
ETC.
Inception-v2,3,4
GoogLeNet은 이후로도 기존 모델의 장점들을 하나둘 결합하면서 더 나은 버전이 몇가지 나왔다.
간단하게만 이해하고 넘어가보자.
Inception-v2,v3에 대한 paper는 Szegedy et al. (2016) Rethinking the Inception Architecture for Computer Vision이다.
main idea는 기존 inception module에 VGG Net의 아이디어를 결합한 것이다.
즉, 아래 그림과 같이 module 내의 conv layer를 더 쪼개서 receptive field는 유지하고 parameter 수를 줄인다(Conv Filter Factorization).
여기서 3x3에서 끝나지 않고, 1x3과 3x1로도 쪼갠 것이 특징이다(원리는 동일).
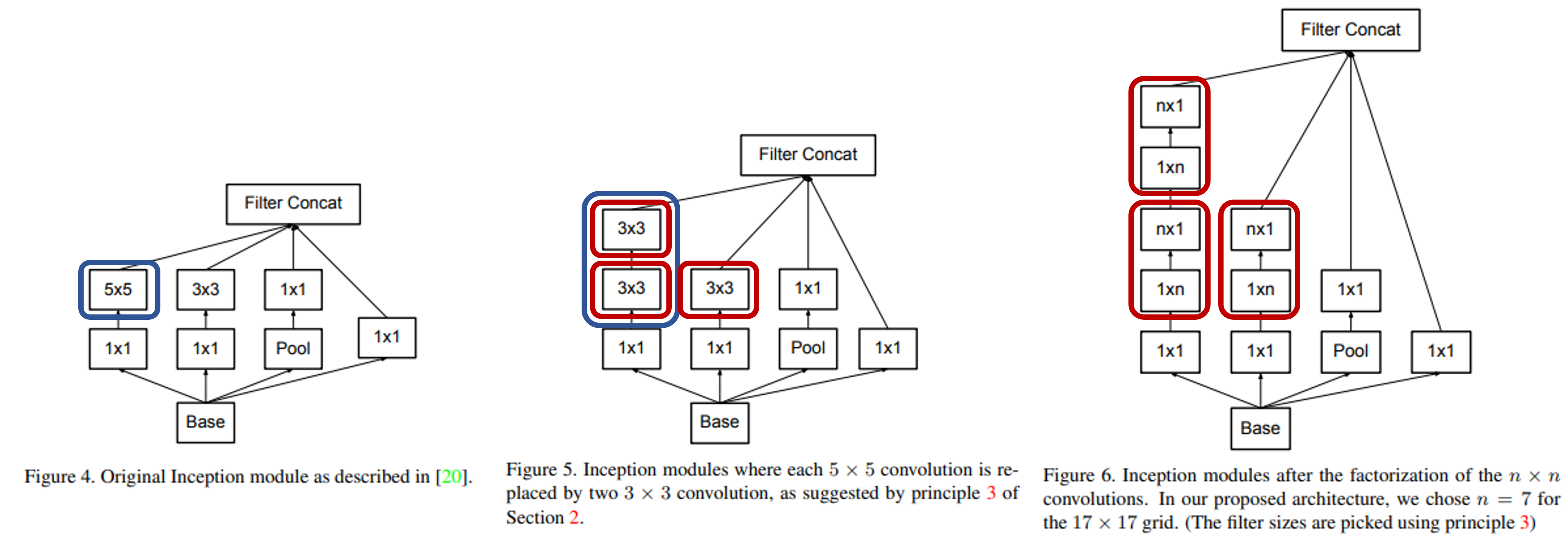
다른 idea는 grid size reduction이 있다.
아래 왼쪽 그림처럼 input으로 35x35x320를 넣고 output으로 17x17x640을 빼는 2가지 대안이 있다고 해보자.
pooling -> inception: pooling을 먼저 함으로써 정보의 손실이 발생한다.inception -> pooling: computational cost가 증가한다.
이러한 두 대안을 절충하고자 module을 약간 조정해 준 것이다.
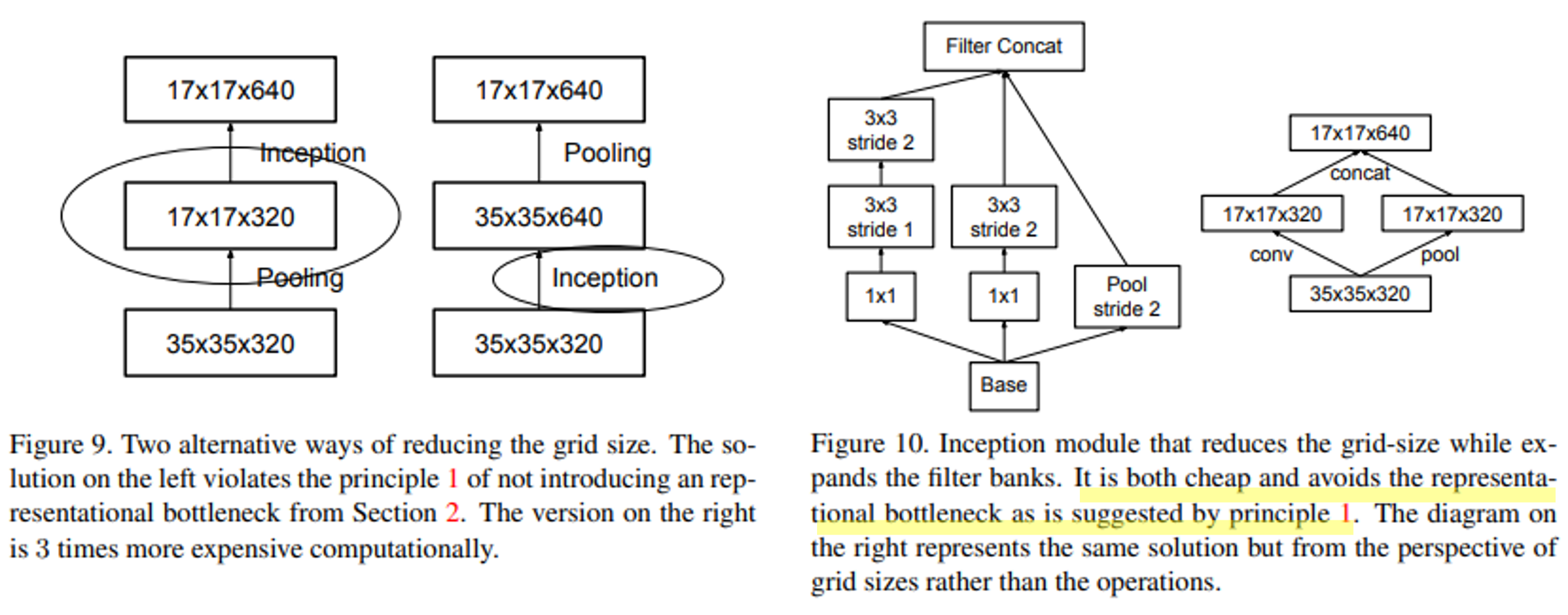
즉, conv layer와 pooling layer를 분리하되, output size는 맞춰주도록 1x1 conv layer를 사용한 것이다.
이를 통해 연산량을 줄이면서 Representational bottleneck을 피할 수 있다고 한다.
*Representational bottleneck은 앞서 언급한 바와 같이 pooling layer를 타면 feature map의 size가 줄어드는(정보량이 줄어드는) 것을 의미한다.
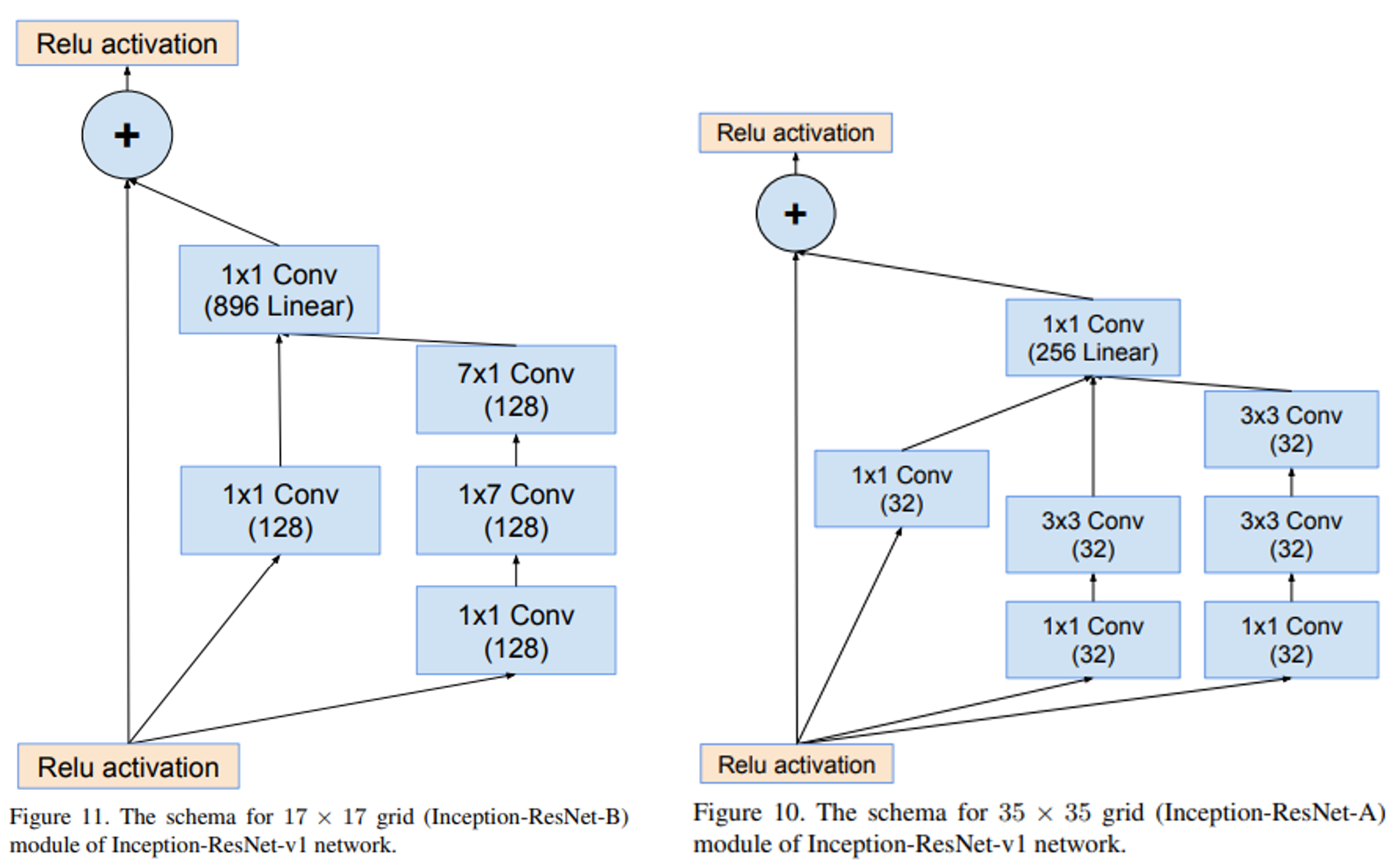
Inception-v4는 더 나아가 ResNet의 Idea(Skip connection)를 결합한 모델이다.
paper는 Szegedy et al. (2016) Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning이다.
정확히는 논문에서 inception-v4에서 ResNet을 결합한 모델로 Inception-ResNet이라고 명명하고 있다.
아래 그림과 같이 inception module과 더불어 skip connection이 추가된 것을 알 수 있다.
Comparing Complexity
지금까지 CNN을 기반으로 다양하게 개선된 모델과 structure들을 살펴봤다.
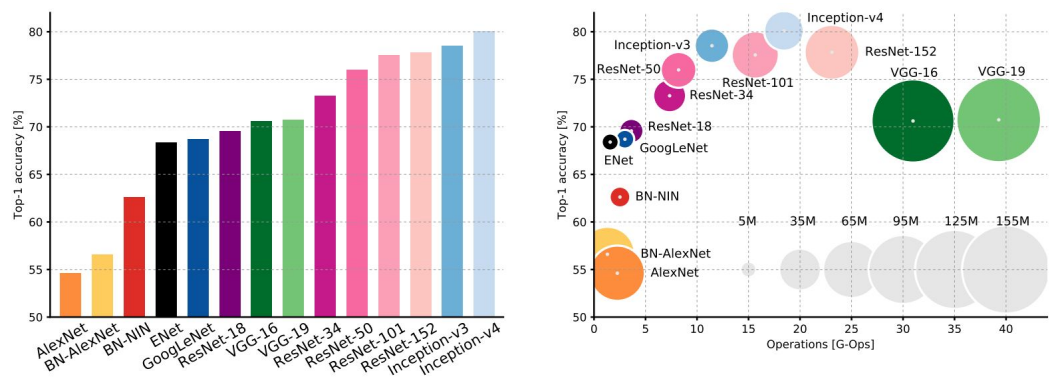
아래 논문에서는 다양한 모델들을 성능(accuracy)과 복잡도(operations, parameters)의 관점에서 비교한 표를 제공한다.
x축은 연산량, y축은 정확도, 원의 크기는 필요한 Memory를 의미한다.
이러한 성능 비교표를 보다 보면 Top-N accuarcy와 같이 표기한 것을 자주 본다.
이는 마지막 softmax classifier의 output으로 도출된 확률 값에서 상위 N개에 정답이 포함되는지를 보는 것이다.
즉, Top-1 accuracy면 가장 높은 1개(결국 예측값)가 맞아야하고, Top-5이면 상위 5개 중에 정답이 포함되면 맞았다고 측정한다.
Source: Canziani el al. (2017) An Analysis of Deep Neural Network Models for Practical Applications
개발된 model들은 당연하게도 시간이 지날수록 정확도는 좋아진다.
그러나 연산 효율성의 측면에서는 다른 양상을 보인다.
- GoogLeNet이 가장 효율적이다.
- VGG는 가장 memory를 많이 차지하고, 연산량이 많다.
- ResNet은 어느정도 효율성도 있고, 정확도도 높게 나타난다.
지금까지는 어떻게든 정확도를 높이려는데 집중했다면, 이후의 추세는 정확도를 유지하는(또는 크게 감소하지 않는) 선에서 효율성을 높이는데 집중하게 된다.
실무에서 실제로 서비스하기 위해서는, 성능이 아무리 좋아도 무거워서 돌아가지 않으면 무용지물이기 때문이다.
더 최근의 몇가지 논문들을 리스트업하고 포스팅은 마무리한다.
- ResNeXt
- Parallel pathways within residual block, similar in spirit to Inception module
- DenseNet
- Each layer is connected to every other layer in feedforward fashion
- MobileNets
- Depth-wise separable convolutions for efficient computing on mobile devices
Reference
이 포스팅은 cs231n 수업(by Prof. Li Fei-Fei at Stanford University)과 Machine Learning for Visual Understanding (by 서울대학교 이준석 교수님) 수업을 듣고 공부하며 작성하였습니다.
https://cs231n.github.io/
http://viplab.snu.ac.kr/viplab/courses/mlvu_2021_2/index.html
https://wikidocs.net/137252
https://ganghee-lee.tistory.com/41
https://hoya012.github.io/blog/deeplearning-classification-guidebook-2/
https://sikaleo.tistory.com/123

댓글남기기