
[cs231n] Transfer Learning
업데이트:
개요

이번 포스팅은 이미 학습된 모델을 현재 task에 가져와 사용하는 transfer learning에 대한 글이다.
Transfer Learning
매번 처음부터 모델링하는 것은 비효율적
transfer learning은 이미 학습되어 있는 모델(pre-trained model)을 가져와, 우리 task에 맞도록 조정(Fine-tuning)하여 최종 모델을 만드는 방법이다.
이를 통해 적은 데이터셋으로도 성능을 낼 수 있으며, 충분히 필요한 학습시간을 단축시킬 수 있다.
예를 들면, 비행기 이미지를 분류하고 싶은데 가지고 있는 데이터셋이 적다면, 이미 대규모 데이터셋을 기반으로 학습이 되어있는 이미지 분류 모델의 weight를 사용할 수 있다.
이러한 이유로 실무에서는 weight을 초기화한 상태에서 처음부터 learning을 하는 경우는 드물고, 대부분 pre-trained model을 기반으로 fine-tuning을 한다.
이전 포스팅에서도 언급했지만, 아래 그림과 같이 image classifier model의 시각화를 통해 Low, Mid, High level feature map이 도출되는 것을 확인했었다.
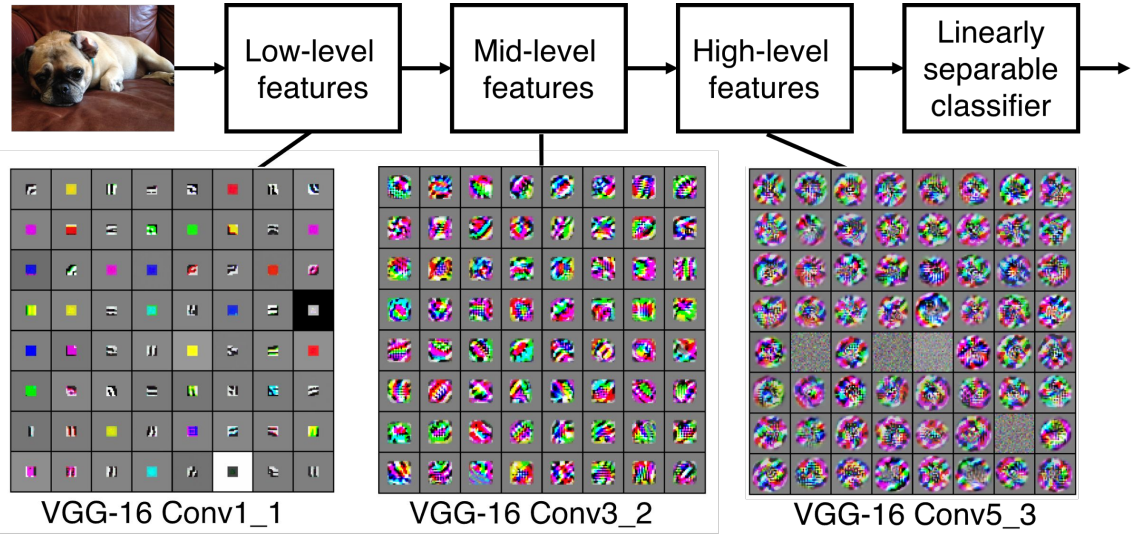
이러한 feature map을 도출 할만한 컴퓨팅 resource나 충분한 dataset이 없다면, 기존에 잘 학습되어 있는 model의 weight을 쓰자는 것이다.
단, 기존 model과 task가 완벽히 같을 수는 없을테니(class가 다르거나), 하단의 일부 layer들만 weight을 초기화하고 학습을 진행한다. 이를 Fine-tuning이라고 한다.
아래 그림과 같이 내가가진 데이터셋에 따라 얼마나 새로 학습 시켜볼지 결정할 수 있다.
![]()
- 첫번째는 Imagenet을 기반으로 학습된 pre-trained model로 1000개의 class를 가지고 있다.
- 두번째는 우리의 task가 C개의 class로 분류하는 것이라 가정했을때, 마지막 classifier에 해당하는 layer만 맞게 바꾸고 기존 weight들은 고정한채 학습을 진행하는 경우(fine-tuning)이다.
- 세번째는 우리가 가진 데이터셋이 더 많을때, 새로 학습할 layer도 늘려주는 경우 이다.
Fine-tuning을 할 때 learning rate은 낮게 설정하는 것을 권장한다(기존의 1/10 수준).
이미 학습된 model을 사용하기 때문에 어느정도 수렴이 되고있는 상황이라 판단하고 learning rate을 크게주면 optimum을 탈출할 가능성이 있을 것이다.
아래 그림은 가진 데이터셋이 얼마나 큰지?(row부분) pre-trained model의 task와 얼마나 유사한지?(column부분) 에 따른 Tip을 제공한다.
model structure는 output(상단)으로 갈수록 specific하고, input(하단)으로 갈 수록 더 generic한 feature들을 담고 있다고 생각할 수 있다.
![]()
가지고 있는 데이터도 많고 유사한 pre-trained model이 존재한다면 best 지만, 그렇지 않은 경우가 많을 것이다.
앞서 언급한것 처럼 데이터가 많은 상황이라면 tuning할 Layer를 늘려볼 수 있고, 너무 적으면 pre-trained에 의존하여 classifier만 train 할 수 있을 것이다.
가장 worst한 상황에서는.. 여러가지 방법이 있겠지만, linear classifier를 하단이 아니라 중간 중간에도 끼워 넣어보는 방법도 제시하고 있다.
이러한 pre-trained model들은 pytorch나 tensorflow 내에서 불러와 간단하게 사용할 수 있다.
성능이 정말 좋아질까??
이러한 이유로 image classification에서 imageNet을 기반으로 한 transfer learning은 필수적이였다.
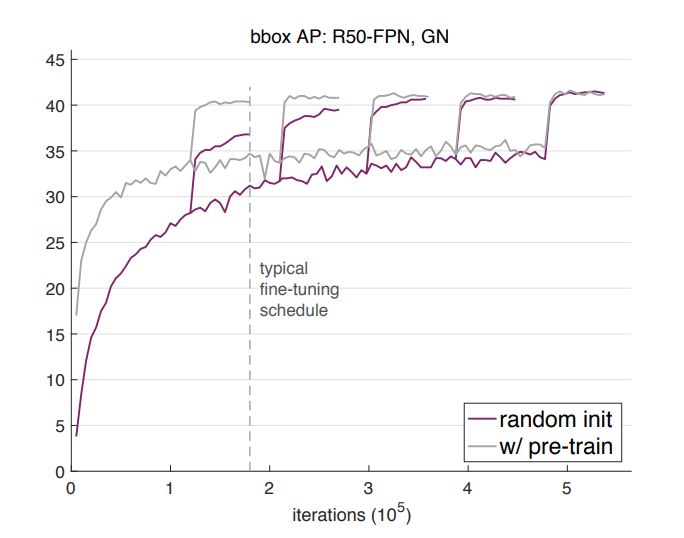
그런데 Facebook에서 2018년에 나온 Rethinking ImageNet Pre-training이라는 논문에서는, weight을 random하게 initialize 하더라도 충분히 많은 학습시간을 거치면 transfer learning과 성능이 같아진다는 결론을 도출하였다.
아래 그림과 같이 기존에는 imageNet의 pre-trained model을 사용하면 성능이 좋아진다는 의견이 많았지만, 정확도의 차이보다는 빠른 수렴을 기대할 수 있는 것으로 이해할 수 있다(빠른 수렴도 매우 중요한 요인).
Reference
이 포스팅은 cs231n 수업(by Prof. Li Fei-Fei at Stanford University)과 Machine Learning for Visual Understanding (by 서울대학교 이준석 교수님) 수업을 듣고 공부하며 작성하였습니다.
https://cs231n.github.io/
http://viplab.snu.ac.kr/viplab/courses/mlvu_2021_2/index.html

댓글남기기