
[cs231n] CNN (Convolutional Neural Networks)
업데이트:
개요

이번 포스팅은 입력 데이터가 이미지인 경우 효과적으로 학습하기 위한 CNN 아키텍처에 대한 내용이다.
CNN 아키텍처에 사용되는 각각의 개념들에 대해 알아보자.
Convolutional Neural Networks
Background
이전 포스팅에서 다뤘던 MLP들은 모든 input과 output간의 inner product를 통해 weight을 모델링했었다. 이러한 의미에서 fully-connected layer라고 한다. 그러나 이와 같은 방식으로만 layer를 쌓게 되면, 학습이 필요한 weight의 수가 너무 많아지고 과적합으로 이어질 수 있다. 그리고 이미지라는 input의 특성을 더 잘 반영할 수 있는 모델의 필요성을 느끼고 발전하게 된다.
CNN의 주요 가정은 다음과 같이 요약된다.
- Spatial Locality
- image라는 input의 특성 상, 전체가 아닌 local한(주변) 영역을 봐야한다.
- 즉, 사람의 입이 어떻게 생겼는지는, 사진에서 얼굴의 주변 만 관찰하면 되지만 사진 전체의 입력 값에 대한 모델링은 불필요 하다는 의미이다.
- (fully-connected layer는 모든 입력값을 모델링한다.)
- 따라서 CNN의 주요 동작방식인 필터(filter)는 각 pixel의 주변만 관찰한다.
- Positional invariance
- object recognition과 관련되는데, 우리가 찾고자하는 object가 image 내에서 어디에 위치해 있는지와 상관없이 같은 패턴을 가진다.
- (사과는 어느 위치에 있든 사과처럼 생겼을 거다.)
- 따라서 filter를 학습해 놓으면 위치가 달라진 다른 image에도 적용할 수 있다.
*예외 case
X-ray, 증명사진 같은 경우는 어떤 이미지든 규격과 위치 등이 고정되어 있다.
이런 경우에는 Positional invariance에 대한 가정이 필요하진 않다.
*용어정리
- Filter: image의 Feature map을 추출하기 위한 학습 파라미터
- Feature map: input과 Filter간의 dot product 결과로, 추출된 특성을 의미함
- Channel: 3차원 구조에서 높이를 의미 (이미지에선 RGB 색상)
- Stride: filter가 sliding하는 stepsize
Convolutional Layer
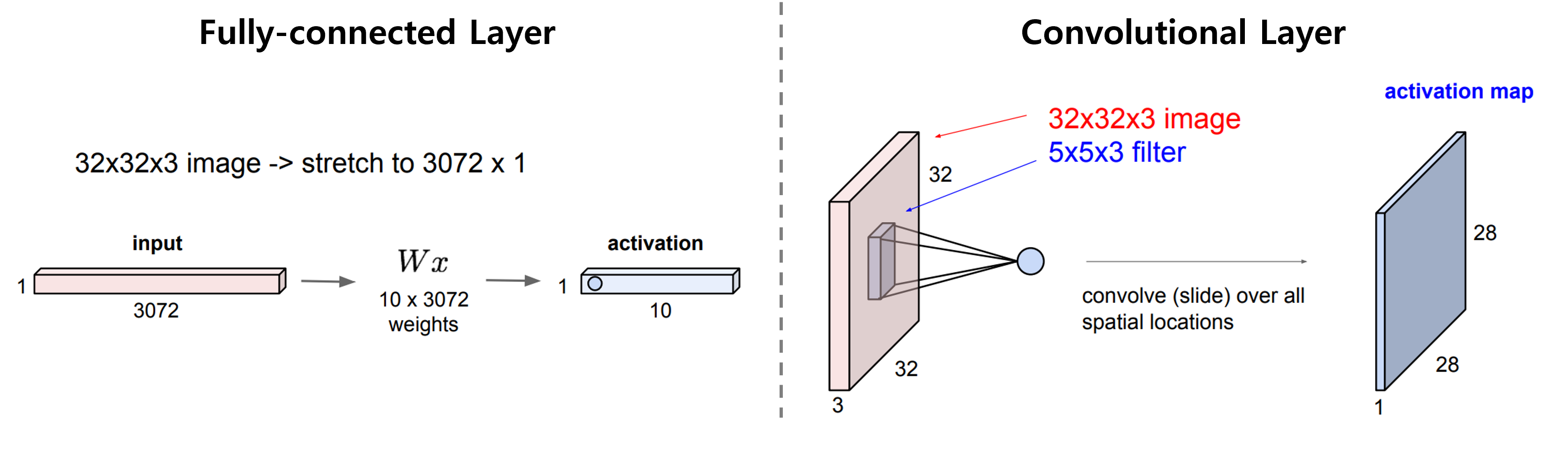
앞에서 언급한 것 처럼 CNN은 패턴을 학습하기 위한 Filter를 이용한다. 아래 그림과 같이 input image를 공간적으로 sliding하면서 filter와 dot product를 통해 feature를 추출한다.
이를 통해 image 차원을 유지하면서 spatial한 특성을 추출할 수 있는 것이다.
Output size는 32x32x3에서 28x28x1로 줄어들었다.
filter의 크기와 움직임에 따라 달라지기 때문에, CNN에서는 이와 같은 input과 output size의 변화에 대한 계산에 익숙해져야한다.
여기서는 “32(input size)-5(filter size)]/1(stride)+1=28”로 계산되었다.
자세한 수식은 아래에서 다시 얘기하도록 하자.
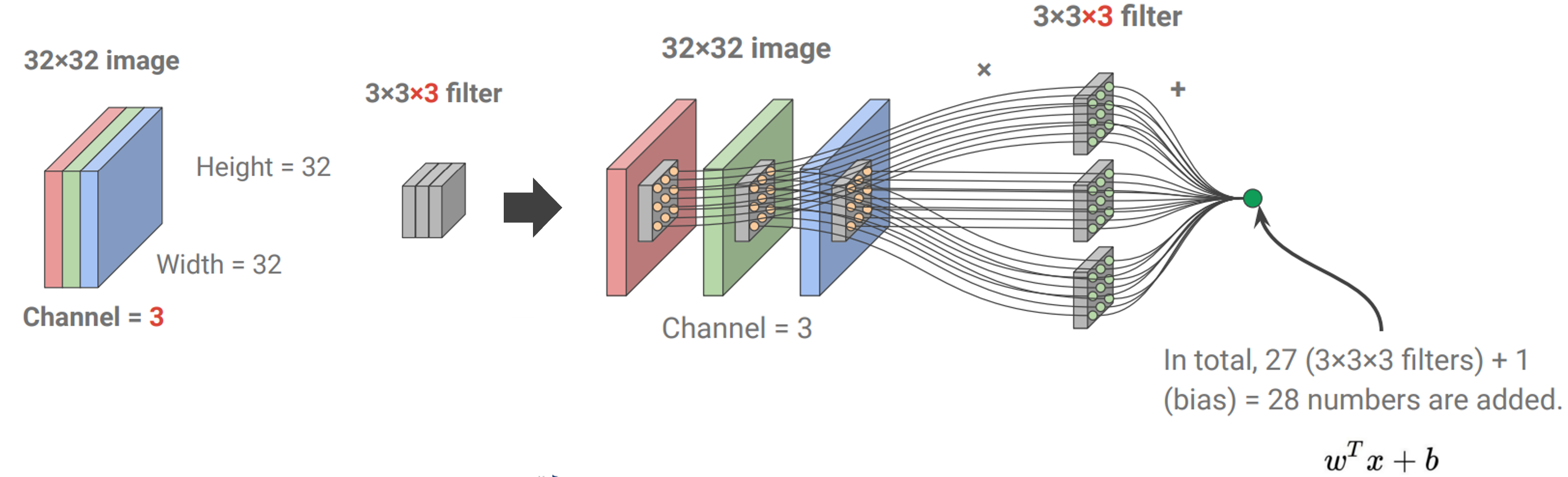
이는 1차원(흑백) 이미지에 대한 dot product이고, 3차원(RGB 컬러)일 때는 아래와 같이 각 channel에 대한 dot product를 수행하면 된다.
parameter의 총 수는 filter size와 bias(+1)로 계산된다.
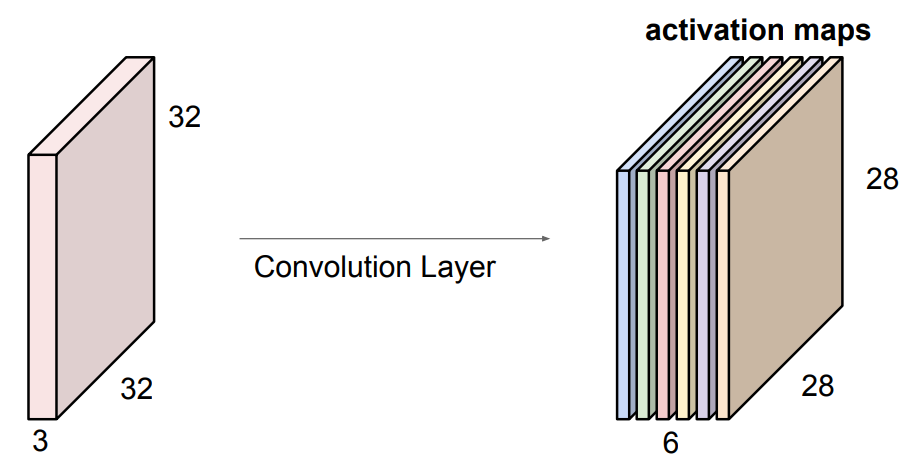
또한 filter의 수를 늘릴 수 있는데, 같은 input에 대해 위와 같은 과정을 여러번 반복하여 output을 쌓게 된다.
아래 그림과 같이 5x5x3 filter 6개를 이용한 conolution layer를 구성하면, Output size는 28x28x6이 된다.
그리고 이때의 parameter의 총 수는 6x(5x3x3+1)가 된다.
이렇게 Convolutinal layer를 겹겹이 쌓게 되었을때, 그 filter들은 어떤 feature들을 학습하고 있을까?
아래 그림은 선행 연구에서 CNN기반 아키텍처인 VGG model이 어떤 image를 학습한 후에, 각 layer들이 갖고 있는 feature map을 시각화한 결과이다.
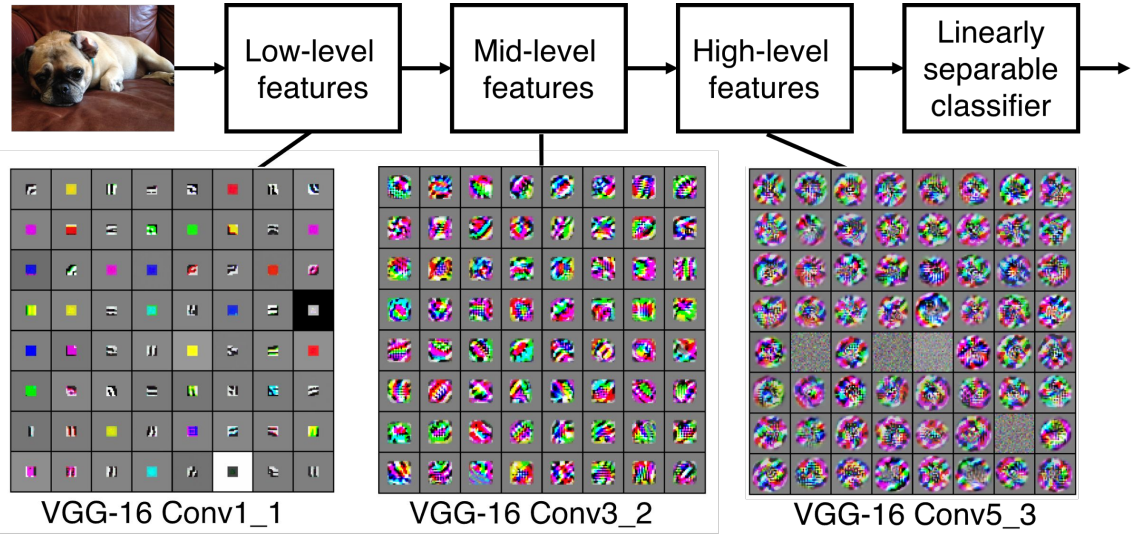
*Source: Zeiler and Fergus 2013
이미지를 학습한 low, mid, high level 에서 각각 다른 feature map들의 패턴을 관찰할 수 있다는 결론을 도출했다.
classifier 바로 직전에 위치한 High-level에서는 class와 직접적으로 관련있는 직관적인 이미지들이 도출된다.
그리고 Mid-level과 Low-level은 각각 앞에 있는 High와 Mid-level의 특징을 잘 구별할 수 있는 feature들을 추출하는 패턴을 보인다.
Nested Convolutional Layers
이제 여러 개의 convolutional layer를 쌓아보자. 그러면 어떤 문제가 생길까??
- filter와의 dot product를 할때마다 output size가 계속 둘어드는 문제
- input image size가 커질수록(고해상도 이미지) convolution layer의 계산량이 증가하는 문제
이러한 문제를 방지하기 위해 CNN layer에 stride와 padding이라는 parameter 값이 추가된다.
filter가 feature map을 추출하는 방식에 약간의 treatment를 주는 것이다.
앞서도 언급했듯이 stride는 filter가 sliding하는 step size를 의미한다.
따라서 아래 그림과 같이 output size를 계산할 수 있다.
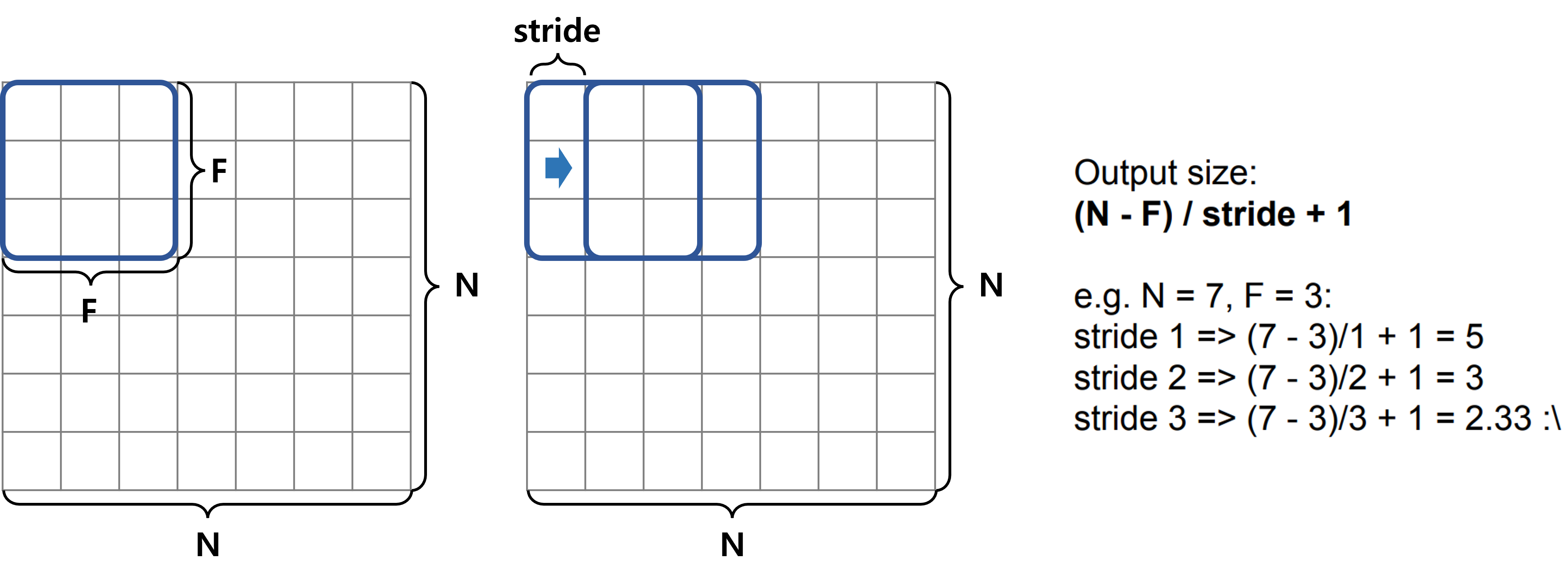
그런데 stride 3과 같은 경우에는 output size가 소수점으로 나오는 문제가 생긴다.
이런 경우를 위해 image 가장자리를 채워주는 padding을 사용한다(주로 zero 값을 사용하여 zero padding이라 부른다).
따라서 아래와 같이 zero padding을 1만큼 해주면 stride 3일 때도 가능하며, output size는 3x3이 된다.
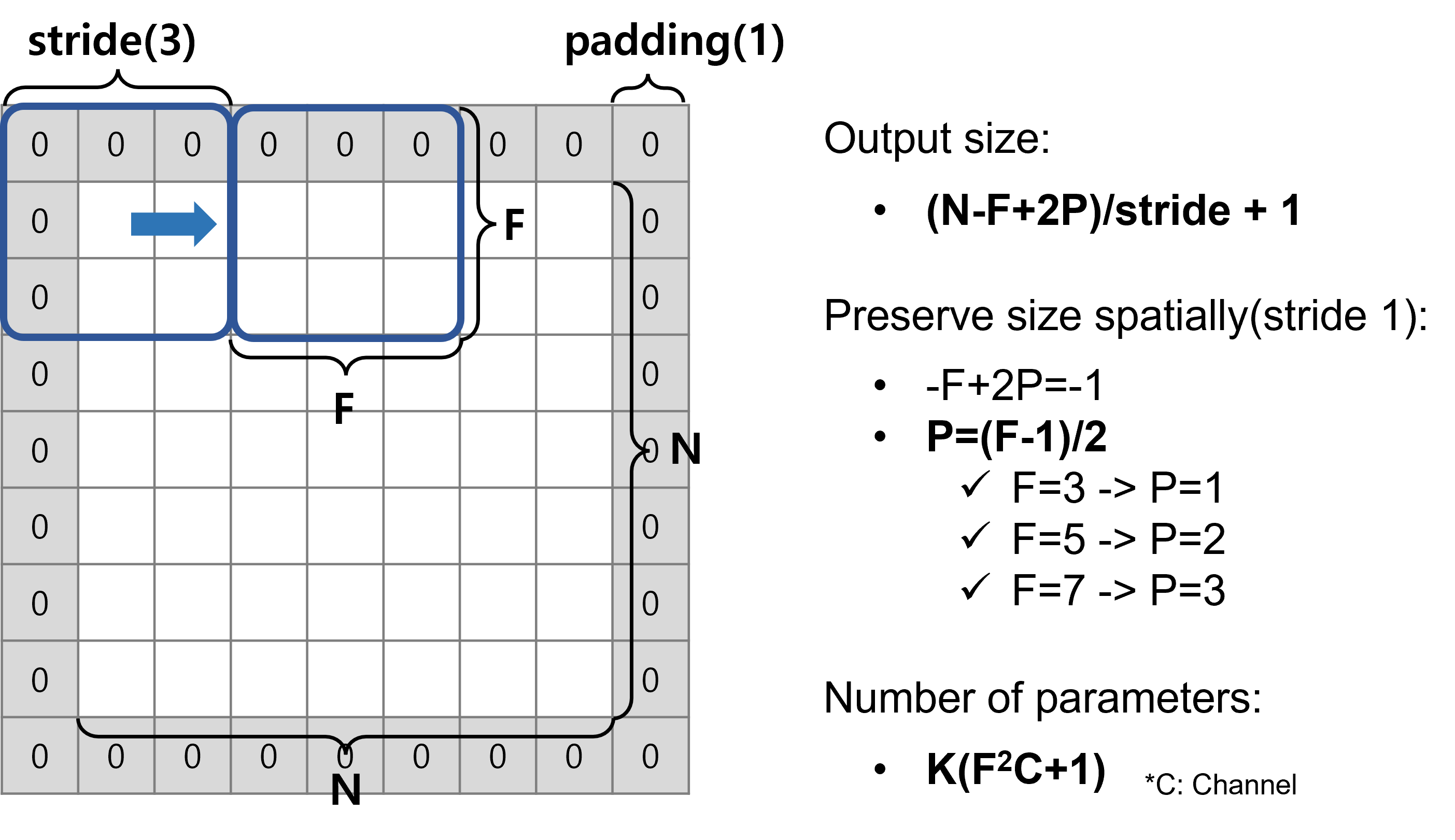
마지막으로 앞서 배운 두가지 treatment를 토대로 최종적인 output size를 계산하는 공식을 잘 기억해두면 편하다.
또한 convolution layer 쌓을수록 이미지 크기가 줄어드는 문제가 있다고 했었다. output size가 줄어들지 않게 하기 위해서는 동일하게 N으로 유지 되도록 Filter size와 Padding을 조정하면 된다.
이제 아래의 몇가지 example에서 output size를 계산하는 연습을 해보자.
- Input:
32x32x3, Filter:10 5x5x3, stride:1, pad:2- Output size:
(32-5+2*2)/1+1=32x32x10 - Paramter 수:
10x(5x5x3+1)=760 - cf) fully connected 일떄?:
(32x32x3)x(32x32x10)=31,457,280
- Output size:
*fully-connected layer는 말그대로 모든 weight이 필요하므로, input과 output 차원의 곱으로 표현된다.
이 예시에서 보는 것처럼 CNN은 주요 가정을 통해 학습해야할 parameter 수를 효과적으로 줄일 수 있는 장점이 있다.
- Input:
32x32x3, Filter:6 1x1x3, stride:1, pad:0- Output size:
(32-1+2*0)/1+1=32x32x6 - Paramter 수:
6x(1x1x3+1)=24
- Output size:
위와 같이 1x1 filter를 사용하는 경우를 가끔 볼 수 있다.
1x1 filter는 sliding을 하면서 spatial하게 주변을 보면서 feature map을 추출하지 않고 channel 간의 dot product만 수행한다.
이를 통해서 size나 주변 pixel을 섞지 않고, 자기 자신의 여러 channel들 간의 특성을 뽑을 수 있다.
마찬가지의 이유로 dimension reduction을 위해서 사용되기도 한다.
Pooling Layer
Pooling layer란, 아래 그림과 같이 spatial하게 downsampling을 수행하는 layer이며 따로 학습은 일어나지 않는다(weight이 없다).
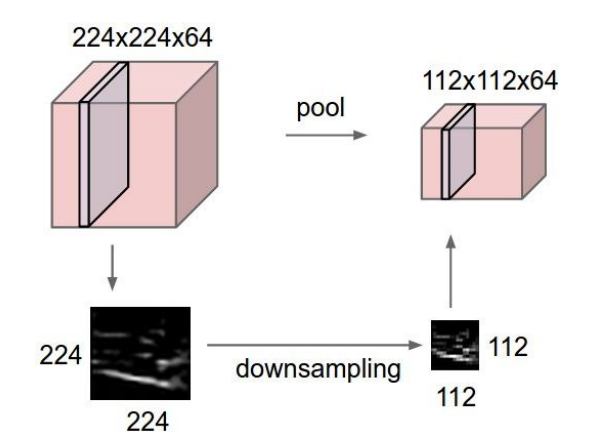
이러한 layer를 추가하는 이유는 아래와 같다.
- more managable: 메모리 부하 방지
- denosing: pixel level에서 너무 민감하게 반응하지 않도록 방지
- controlling overfitting: denoising의 맥락에서 과적합 방지
Pooling layer는 Filter size와 stride라는 2개의 parameter가 존재한다.
아래 그림은 Filter size가 2x2이고, stride가 2일 때, Max와 average pooling의 예시를 보여준다.
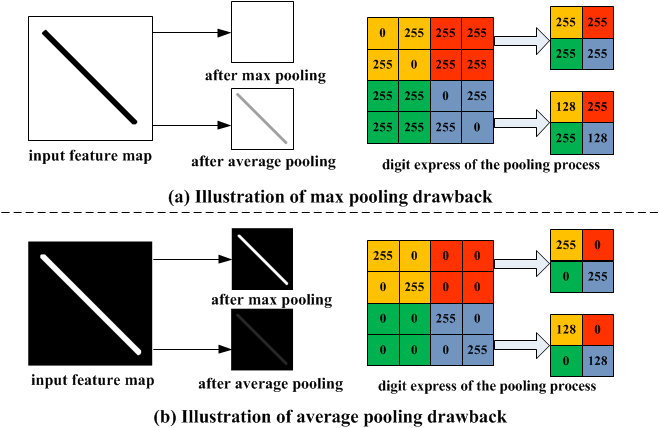
*Source: Introduction To Pooling Layers In CNN
Pooling을 할때 해당 filter 내의 pixel들을 축소시키는 방법에 따라 종류가 나눠진다.
- Max pooling: filter 내 pixel들의 max값 사용
- 가장 두드러지는 feature를 유지시키겠다는 아이디어
- Average Pooling: filter 내 pixel들의 average값 사용
- 평균적인 값으로 smoothing해서 보정하겠다는 아이디어
왼쪽 그림은 검정색(0)과 흰색(255)로 이루어진 이미지를 두 방법으로 pooling 한 예시이다.
이때의 결과를 보면, (a)의 경우에서는 오히려 average가 낫고(min이 제일 낫겠지만), (b)에서는 max가 기존 이미지를 잘 보존하는 것을 알 수 있다.
즉, 연구자의 의도에 맞게 잘 써야한다는 얘기다.
최근에는 Pooling layer를 넣지 않는 추세로 가고 있다.
pooling의 목적인 downsampling은 기존의 convolution layer로도 가능(stride를 크게 주면 됨)하기 때문에, 단순히 convolution layer로만 구성된 아키텍처가 더 학습이 잘된다는 연구들이 나오고 있다.
예를들어, VAE(Variational Autoencoder), GAN(Generative Adversarial Networks)과 같은 generative model에서 pooling layer를 없애는 것이 더 학습이 잘된다는 결론이 도출된바 있다.
따라서 향후에는 거의 사용되지 않을 가능성이 높다.
Reference
이 포스팅은 cs231n 수업(by Prof. Li Fei-Fei at Stanford University)과 Machine Learning for Visual Understanding (by 서울대학교 이준석 교수님) 수업을 듣고 공부하며 작성하였습니다.
https://cs231n.github.io/
http://viplab.snu.ac.kr/viplab/courses/mlvu_2021_2/index.html
https://seongkyun.github.io/study/2019/11/17/cnn/

댓글남기기