
[Web] BeautifulSoup의 기초 함수와 트리구조
업데이트:
개요

- 예제 url
- http://www.pythonscraping.com/pages/warandpeace.html
1. find()와 findAll()
크롤링을 통해 데이터를 긁어올때 CSS 코드를 이용하는 방법도 종종 사용될 때가 있다.
CSS는 Cascading Style Sheets의 약자로 “구체적으로 어떤 스타일로 요소가 표시 되는지를 정하는 규격”이라고 할 수 있다.
(예를들면, 긁자 굵기나 색상 같은 것들)
보통 <span class="green"></span>나 style, type과 같이 사용되는 경우가 있다.
(span 태그에 CSS class를 붙인 경우)
위의 예제 url에서 녹색(green)글자를 모두 긁어보자.
from urllib.request import urlopen
from bs4 import BeautifulSoup
html= urlopen('http://www.pythonscraping.com/pages/warandpeace.html')
bs = BeautifulSoup(html, 'html.parser')
nameList = bs.findAll('span',{'class':'green'}) # or find_all
for i in nameList:
print(i.get_text())
Anna
Pavlovna Scherer
Empress Marya
Fedorovna
Prince Vasili Kuragin
Anna Pavlovna
St. Petersburg
the prince
Anna Pavlovna
Anna Pavlovna
the prince
the prince
the prince
Prince Vasili
Anna Pavlovna
...생략
findAll()함수로 페이지의 모든 해당 태그를 찾고, get_text()를 이용해 태그를 제외한 텍스트를 추출한 것이다.
함수에 대해 더 알아보자
findAll(tag, attributes, recursive, text, limit, keywords)find(tag, attributes, recursive, text, keywords)
문서의 모든 헤더 태그 리스트 반환
bs.findAll({'h1','h2','h3','h4','h5','h6'})
[<h1>War and Peace</h1>, <h2>Chapter 1</h2>]
녹색(green)과 빨간색(red) span 태그를 모두 반환
bs.findAll({'span':{'class':{'green','red'}}})
<span class="red">Well, Prince, so Genoa and Lucca are now just family estates of the
Buonapartes. But I warn you, if you don't tell me that this means war,
if you still try to defend the infamies and horrors perpetrated by
that Antichrist- I really believe he is Antichrist- I will have
nothing more to do with you and you are no longer my friend, no longer
my 'faithful slave,' as you call yourself! But how do you do? I see
I have frightened you- sit down and tell me all the news.</span>,
<span class="green">Anna
Pavlovna Scherer</span>,
... 생략
reculsive=True가 default 이며, 재귀적으로 자식의 자식 태그까지 모두 검색하며,
False일 경우 최상위 태그만 검색한다.
text매개변수, 태그에 둘러싸인 ‘the prince’가 몇 번 나타났는지 검색
nameList = bs.findAll(text='the prince')
print(len(nameList))
7
the prince라는 텍스트만이 태그에 둘러싸여 있어야 검색이 된다.
예를들어 ‘the ‘라는 텍스트는 혼자 태그에 둘러싸여 있지 않기때문에 불가능하다.
keyword매개변서, 특정 속성이 포함된 태그를 선택
bs.findAll(id='text')
[<div id="text">
"<span class="red">Well, Prince, so Genoa and Lucca are now just family estates of the
Buonapartes. But I warn you, if you don't tell me that this means war,
if you still try to defend the infamies and horrors perpetrated by
that Antichrist- I really believe he is Antichrist- I will have
nothing more to do with you and you are no longer my friend, no longer
my 'faithful slave,' as you call yourself! But how do you do? I see
I have frightened you- sit down and tell me all the news.</span>"
<p></p>
It was in July, 1805, and the speaker was the well-known <span class="green">Anna
Pavlovna Scherer</span>, maid of honor and favorite of the <span class="green">Empress Marya
Fedorovna</span>. With these words she greeted <span class="green">Prince Vasili Kuragin</span>, a man
of high rank and importance, who was the first to arrive at her
reception. <span class="green">Anna Pavlovna</span> had had a cough for some days. She was, as
she said, suffering from la grippe; grippe being then a new word in
<span class="green">St. Petersburg</span>, used only by the elite.
...생략
아까처럼 녹색글씨를 다른방법으로 찾기
bs.findAll(class_='green')
<span class="green">Anna
Pavlovna Scherer</span>, <span class="green">Empress Marya
Fedorovna</span>, <span class="green">Prince Vasili Kuragin</span>, <span class="green">Anna Pavlovna</span>, <span class="green">St. Petersburg</span>,
... 생략
class는 파이썬 예약어이기 때문에 class_로 사용해야한다.
limit매개변수, 페이지의 처음 부터 검색할 개수
이 매개변수는 페이지의 항목 처음 몇개에만 관심이 있을때 사용한다.
find()함수는 findAll()함수의 limit매개변수를 1로 둔 것을 제외하고는 다른 것이 없다.
2. 트리 구조
- 예제 url
- http://www.pythonscraping.com/pages/page3.html
위 페이지의 대략적인 html구조를 살펴보면 다음과 같다.
- body
- div.wrapper
- h1
- div.content
- table#giftList
- tr
- th
- th
- th
- th
- tr.gift#gift1
- td
- td
- span.excitingNote
- td
- td
- img
- 생략..
- div.footer
이러한 구조가 나뭇가지와 같다고 해서 트리구조라고 한다.
- 자식
children: 항상 부모보다 한 태그 아래에 위치한 태그 - 자손
descendants: 아래에 위치한 모든 태그들
2-1. 자식(children)
giftList가 있는 표(부모)의 자식 태그들을 긁어와보자.
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen('http://www.pythonscraping.com/pages/page3.html')
bs = BeautifulSoup(html, 'html.parser')
for child in bs.find('table',{'id':'giftList'}).children:
print("="*10)
print(child)
==========
==========
<tr><th>
Item Title
</th><th>
Description
</th><th>
Cost
</th><th>
Image
</th></tr>
==========
==========
<tr class="gift" id="gift1"><td>
Vegetable Basket
</td><td>
This vegetable basket is the perfect gift for your health conscious (or overweight) friends!
<span class="excitingNote">Now with super-colorful bell peppers!</span>
</td><td>
$15.00
</td><td>
<img src="../img/gifts/img1.jpg"/>
</td></tr>
==========
==========
<tr class="gift" id="gift2"><td>
Russian Nesting Dolls
</td><td>
Hand-painted by trained monkeys, these exquisite dolls are priceless! And by "priceless," we mean "extremely expensive"! <span class="excitingNote">8 entire dolls per set! Octuple the presents!</span>
</td><td>
$10,000.52
</td><td>
<img src="../img/gifts/img2.jpg"/>
</td></tr>
==========
... 생략
헷갈릴 수 있는 부분은 바로 밑의 자식 태그는 <tr class="gift" id="gift1">이므로 이것만 가져와야한다고 생각했었는데,
이 태그는 이 태그만을 의미하는게 아니라
<tr class="gift" id="gift1"><td>
Vegetable Basket
</td><td>
This vegetable basket is the perfect gift for your health conscious (or overweight) friends!
<span class="excitingNote">Now with super-colorful bell peppers!</span>
</td><td>
$15.00
</td><td>
<img src="../img/gifts/img1.jpg"/>
</td></tr>
여기 까지를 의미하기 때문에, 내용물도 다 가져왔다고 생각할 수 있다.(나만 헷갈렸을 수도..)
2-2. 자손(descendants)
따라서 하지만 출력되는 결과 객체는 1개이다(<tr class="gift" id="gift1">…<tr>만 이 자식 태그이므로)
이 내부에 있는 하위 태그들도 개별적으로 출력하려면 descendants를 사용하여 자손 태그를 가져오면 된다.
for des in bs.find('table',{'id':'giftList'}).descendants:
print("="*10)
print(des)
==========
<tr class="gift" id="gift1"><td>
Vegetable Basket
</td><td>
This vegetable basket is the perfect gift for your health conscious (or overweight) friends!
<span class="excitingNote">Now with super-colorful bell peppers!</span>
</td><td>
$15.00
</td><td>
<img src="../img/gifts/img1.jpg"/>
</td></tr>
==========
<td>
Vegetable Basket
</td>
==========
Vegetable Basket
==========
<td>
This vegetable basket is the perfect gift for your health conscious (or overweight) friends!
<span class="excitingNote">Now with super-colorful bell peppers!</span>
</td>
==========
This vegetable basket is the perfect gift for your health conscious (or overweight) friends!
==========
<span class="excitingNote">Now with super-colorful bell peppers!</span>
==========
Now with super-colorful bell peppers!
==========
==========
<td>
$15.00
</td>
==========
$15.00
==========
<td>
<img src="../img/gifts/img1.jpg"/>
</td>
==========
==========
<img src="../img/gifts/img1.jpg"/>
==========
그러면 이렇게 모든 하위 태그들까지 다 일일이 하나씩 출력하게 된다.
사실상 자식 태그만 긁어와서 필요한 태그나 택스트를 추출하는 방법이 좀더 간단할 수도 있다는 생각은 들지만, 일단 더 공부해보자.
2-3. 형제(next_siblings)
next_siiblings()함수는 웹페이지의 테이블(표)에서 데이터를 쉽게 수집할 수 있고, 특히 타이틀(헤더)가 있을때 유용하다.
for siblings in bs.find('table',{'id':'giftList'}).tr.next_siblings:
print("="*10)
print(siblings)
==========
==========
<tr class="gift" id="gift1"><td>
Vegetable Basket
</td><td>
This vegetable basket is the perfect gift for your health conscious (or overweight) friends!
<span class="excitingNote">Now with super-colorful bell peppers!</span>
</td><td>
$15.00
</td><td>
<img src="../img/gifts/img1.jpg"/>
</td></tr>
==========
==========
<tr class="gift" id="gift2"><td>
Russian Nesting Dolls
</td><td>
Hand-painted by trained monkeys, these exquisite dolls are priceless! And by "priceless," we mean "extremely expensive"! <span class="excitingNote">8 entire dolls per set! Octuple the presents!</span>
</td><td>
$10,000.52
</td><td>
<img src="../img/gifts/img2.jpg"/>
</td></tr>
==========
==========
<tr class="gift" id="gift3"><td>
Fish Painting
</td><td>
If something seems fishy about this painting, it's because it's a fish! <span class="excitingNote">Also hand-painted by trained monkeys!</span>
</td><td>
$10,005.00
</td><td>
<img src="../img/gifts/img3.jpg"/>
</td></tr>
==========
==========
<tr class="gift" id="gift4"><td>
Dead Parrot
</td><td>
This is an ex-parrot! <span class="excitingNote">Or maybe he's only resting?</span>
</td><td>
$0.50
</td><td>
<img src="../img/gifts/img4.jpg"/>
</td></tr>
==========
==========
<tr class="gift" id="gift5"><td>
Mystery Box
</td><td>
If you love suprises, this mystery box is for you! Do not place on light-colored surfaces. May cause oil staining. <span class="excitingNote">Keep your friends guessing!</span>
</td><td>
$1.50
</td><td>
<img src="../img/gifts/img6.jpg"/>
</td></tr>
==========
위 예제코드는 테이블의 헤더를 제외한 테이블의 원소들을 긁어온 것이다.
next_siblings()는 말 그대로 선택한 객체를 제외하고 선택한 객체와 형제인 태그(여기서는 tr태그)들을 긁어 온다.
즉, 앞에서 배운 것 처럼
bs.find('table',{'id':'giftList'}).tr
<tr><th>
Item Title
</th><th>
Description
</th><th>
Cost
</th><th>
Image
</th></tr>
이를 이용해 첫번째 tr태그(표의 헤더)를 선택했고, 그 이후에 나오는 tr태그(형제)들을 가져오는 것이다.
비슷한 함수로 previous_siblings함수는 선택한 태그의 이전에 나오는 형제 태그들을 가져온다.
또한 “s”를 뺀 next_sibling, previous_sibling함수는 선택 태그 이전/이후의 하나의 형제 태그만을 가져온다.
헤더처럼 처음 나오는 태그 식별이 쉬울 때,
next_siblings함수를
마지막에 있는 태그 식별이 쉬울 때,previous_siblings함수를 이용하자.
2-4. 부모(parents)
보통은 구조를 이해하고 부모부터 자식으로 긁어나가기 마련이지만, 자식을 통해 부모를 찾아야할 때가 있다.
bs.find('img',{'src':'../img/gifts/img1.jpg'}).parent.previous_sibling.get_text()
'\n$15.00\n'
이는 특정 이미지를 이용해서, 그 이미지가 해당하는 가격을 가져온 것으로 다음과 같은 순서로 진행된다.
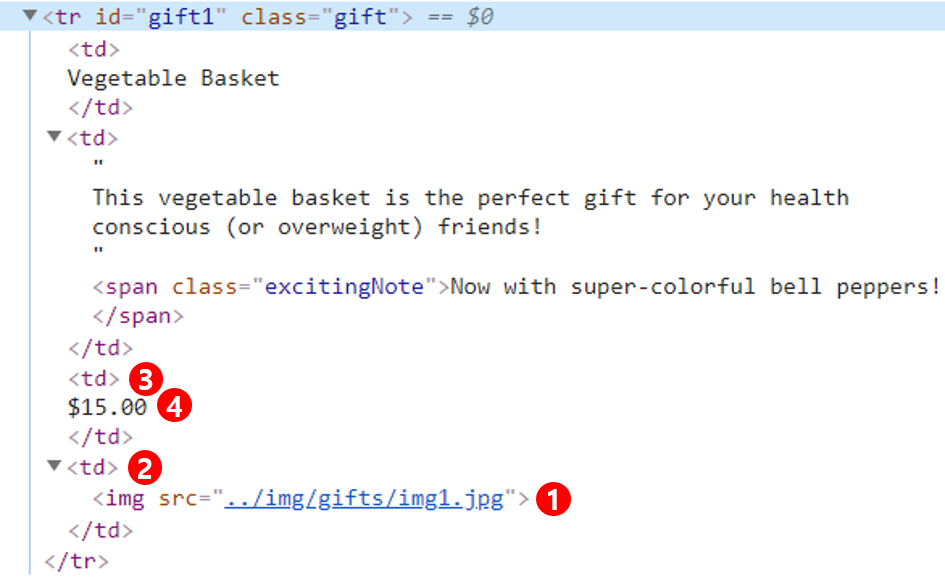
- 특정 이미지를 포함하는 ‘img’태그 선택
- 부모 태그 선택
- 바로 이전의 형제 태그 선택
- 태그 내의 텍스트 추출

댓글남기기