
[Python] dataframe의 원소가 리스트인 컬럼을 기반으로 행 복사
업데이트:
개요
![]()
아래 다음과 같은 작업이 필요하다고 가정하자.
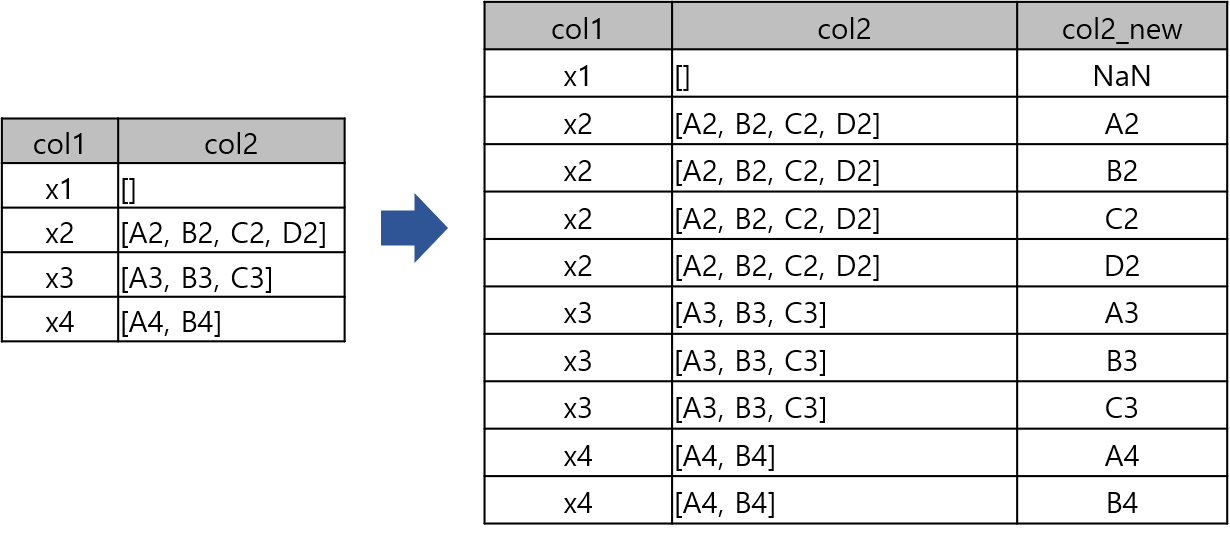
방법
결론부터 얘기하자면 다음과 같이 하면 된다.
import pandas as pd
df = pd.DataFrame({'col1': ['x1','x2','x3','x4'],
'col2': [[],['A2','B2','C2','D2'],['A3','B3','C3'], ['A4','B4']]})
df
| col1 | col2 | |
|---|---|---|
| 0 | x1 | [] |
| 1 | x2 | [A2, B2, C2, D2] |
| 2 | x3 | [A3, B3, C3] |
| 3 | x4 | [A4, B4] |
df2 = df.join(df['col2'].apply(lambda x: pd.Series(x)).stack().reset_index(1,name='col2_new').drop('level_1', axis=1))
df2
| col1 | col2 | col2_new | |
|---|---|---|---|
| 0 | x1 | [] | NaN |
| 1 | x2 | [A2, B2, C2, D2] | A2 |
| 1 | x2 | [A2, B2, C2, D2] | B2 |
| 1 | x2 | [A2, B2, C2, D2] | C2 |
| 1 | x2 | [A2, B2, C2, D2] | D2 |
| 2 | x3 | [A3, B3, C3] | A3 |
| 2 | x3 | [A3, B3, C3] | B3 |
| 2 | x3 | [A3, B3, C3] | C3 |
| 3 | x4 | [A4, B4] | A4 |
| 3 | x4 | [A4, B4] | B4 |
위 작업의 순서는 다음과 같다.
1.
.apply(lambda x : pd.Series(x)): 각 원소(리스트)를 판다스 Series로 변형
df['col2'].apply(lambda x: pd.Series(x))
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | NaN | NaN | NaN | NaN |
| 1 | A2 | B2 | C2 | D2 |
| 2 | A3 | B3 | C3 | NaN |
| 3 | A4 | B4 | NaN | NaN |
2.
.stack(): 각 행을 하나의 열로 쌓음
df['col2'].apply(lambda x: pd.Series(x)).stack()
1 0 A2
1 B2
2 C2
3 D2
2 0 A3
1 B3
2 C3
3 0 A4
1 B4
dtype: object
3.
.reset_index().drop(): stack으로 멀티인덱스가 된 것을 reset하여 상위 인덱스만 남기고 drop
df['col2'].apply(pd.Series).stack().reset_index(1, name='col2_new').drop('level_1', axis=1)
| col2_new | |
|---|---|
| 1 | A2 |
| 1 | B2 |
| 1 | C2 |
| 1 | D2 |
| 2 | A3 |
| 2 | B3 |
| 2 | C3 |
| 3 | A4 |
| 3 | B4 |
4.
.join(): 기존 데이터프레임과 join (index를 기준으로 join됨)
df.join(df['col2'].apply(pd.Series).stack().reset_index(1, name='col2_new').drop('level_1', axis=1))
| col1 | col2 | col2_new | |
|---|---|---|---|
| 0 | x1 | [] | NaN |
| 1 | x2 | [A2, B2, C2, D2] | A2 |
| 1 | x2 | [A2, B2, C2, D2] | B2 |
| 1 | x2 | [A2, B2, C2, D2] | C2 |
| 1 | x2 | [A2, B2, C2, D2] | D2 |
| 2 | x3 | [A3, B3, C3] | A3 |
| 2 | x3 | [A3, B3, C3] | B3 |
| 2 | x3 | [A3, B3, C3] | C3 |
| 3 | x4 | [A4, B4] | A4 |
| 3 | x4 | [A4, B4] | B4 |

댓글남기기