
[ML] kNN Classifier, Numpy로 구현하기
업데이트:
개요
이번 포스팅에서는 kNN classifier을 python으로 직접 구현한다. scikit-learn에서도 제공하긴 하지만, numpy로 작성하였다.
이전에 k=1이라는 가정 하에 Nearest Neighbor에 대해서는 구현했었고, 이번에는 k값에 대해 일반화된 코드를 구현한다. 자세한 내용들은 여기를 참고하자.
kNN Implementation
Dataset
데이터 셋은 scikit-learn에서 제공하는 iris 데이터를 사용하였다.
쉬운 예시를 위해 feature는 ‘Petal length’,‘Petal width’ 만을 사용하였다.
아래 코드는 데이터를 불러와서 random sampling을 통해 train, test data로 나누는 작업이다.
- numpy의 난수생성을 통해 중복없이 sample을 추출한다.
- array기반 indexing을 위해 마스킹을 이용한다.
- 총 150개의 데이터를 train 120개, test 30개로 간단하게 분리한다.
import numpy as np
from sklearn import datasets
def random_sampling(high,n_size):
result=[]
rand_num=np.random.randint(high)
for _ in range(n_size):
while rand_num in result:
rand_num = np.random.randint(high)
result.append(rand_num)
return np.array(result)
def accuracy(y_pred, y_true):
return np.sum(y_pred==y_true) / len(y_true)
# Data 로딩
iris = datasets.load_iris()
X = iris.data[:,2:]
y = iris.target
# Random sampling & array 기반 인덱싱
test_idx = random_sampling(150, 30)
train_idx = np.ones(len(X), dtype=bool)
train_idx[test_idx]=False
# Learning data 추출
X_train = X[train_idx]
y_train = y[train_idx]
X_test = X[test_idx]
y_test = y[test_idx]
print("X_train: %s y_train: %s X_test: %s y_test: %s" % (len(X_train),len(y_train),len(X_test),len(y_test)))
X_train: 120 y_train: 120 X_test: 30 y_test: 30
Model
다음은 kNN 알고리즘의 본체이다. class로 구성되어 4개의 function을 담는다.
distance matrix를 생성하기 위해, 2차원 데이터 기반의 행렬 연산이 필요하다.
알고가면 numpy 함수들은 아래와 같다.
np.tile: array를 통으로 쌓을 때 사용np.repeat: array의 row 또는 col 단위로 쌓을 때 사용np.argsort(): array에 대해 크기순 index를 추출(정렬할때 사용)
predict()의 다수결 투표는 train에서 저장된 데이터들과의 distance matrix에서 가장 가까운 k개의 point들을 뽑은 뒤, 가장 많은 label로 추정한다.
distance는 현재 L2 방식만 포함하였으나, 여러가지로 확장할 수 있다.
class kNN():
# 초기에 k 값을 지정
def __init__(self,k=3):
self.k=k
# Train: Train데이터 모두 memory에 저장
def train(self,X,y):
self.X=X
self.y=y
# train data와의 distance 계산
# - X_test: (N, D)
# - X_train: (M, D)
# - dists: (N, M) / test point별로 train point간의 거리행렬
def get_distance(self, X_test, method="L2"):
N = len(X_test)
M = len(self.X)
X_train_t = np.tile(self.X, (N,1))
X_test_t = np.repeat(X_test, M, axis=0)
if method=="L2":
distance = np.sqrt(np.sum((X_train_t-X_test_t)**2,axis=1)).reshape(N,M)
return distance
# 다수결 투표를 통한 label 도출
def predict(self, X_test):
N = len(X_test)
y_hat = np.zeros(N)
distance = self.get_distance(X_test, method="L2")
arg_dist = distance.argsort()
for i in range(N):
row = arg_dist[i]
k_neighbor = self.y[row[:self.k]]
target, cnt = np.unique(k_neighbor, return_counts=True)
y_hat[i] = target[np.argmax(cnt)]
return y_hat
Test
kNN(k=3)을 테스트해본 결과 정확도는 약 93%로 나왔다.
model = kNN(k=3)
model.train(X_train, y_train)
y_pred = model.predict(X_test)
acc = accuracy(y_pred, y_test)
print("Accuracy: ", acc)
Accuracy: 0.9333333333333333
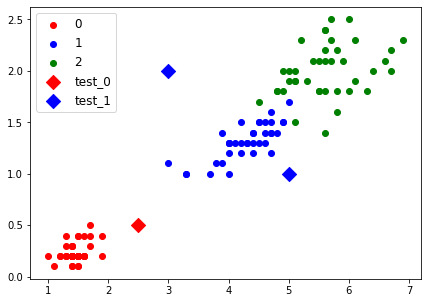
쉬운 이해를 위해 inference용 test point 3개를 만들고, 아래와 같이 결과를 시각화 보았다.
결정경계에 따라 data가 분류되는 것을 확인할 수 있다(시각화 관련 내용은 여기를 참고).
import matplotlib.pyplot as plt
test_point = np.array([[2.5, 0.5],
[5, 1],
[3, 2],
])
test_pred = model.predict(test_point)
test_pred = list(map(int,test_pred))
cdict = {0: 'red', 1: 'blue', 2: 'green'}
fig, ax = plt.subplots()
for g in np.unique(y_train):
ix = np.where(y_train == g)
ax.scatter(X_train[:,0][ix], X_train[:,1][ix], c = cdict[g], label = g)
for g in np.unique(test_pred):
ix = np.where(test_pred == g)
ax.scatter(test_point[:,0][ix], test_point[:,1][ix], c = cdict[g], label = 'test_'+str(g), marker="D",s=100)
ax.legend()
plt.show()
Reference
https://stackoverflow.com/questions/47006268/matplotlib-scatter-plot-with-color-label-and-legend-specified-by-c-option

댓글남기기