
[시각화] Matplotlib pyplot을 활용한 데이터 시각화 1
업데이트:
개요
![]()
이번 포스팅에서는 Python 시각화 라이브러리인 matplotlib을 활용해 데이터를 시각화하는 방법에 대해 알아보자. Pandas에 내장된 시각화 기능이나, Seaborn 등 다양한 방식이 존재하지만, 대부분의 라이브러리도 matplotlib을 기반으로 하거나 참조하는 경우가 많다.
1. 기본 설정
시각화에 앞서 기본 설정 등에 대해 알아보자.
1-1. 한글 폰트 깨짐 방지
기본적으로 font는 ‘sans-erif’를 default로 하기 때문에 한글 지원을 하지 않는다.
import matplotlib
matplotlib.rcParams['font.family']
['sans-serif']
따라서 직접 font를 지정해주고 음수(-)값도 깨짐 방지를 위해 아래와 같이 기본 설정을 지정해 준다.
import matplotlib
import matplotlib.font_manager as fm
font_name = fm.FontProperties(fname = 'C:/Windows/Fonts/malgun.ttf').get_name()
matplotlib.rc('font', family = font_name)
matplotlib.rcParams['axes.unicode_minus'] = False
1-2. Style, Color 참조
plotting을 할때 선의 스타일이나 색 등을 다양하게 조절할 필요가 있다. 해당 내용들은 matplotlib 공식 문서에 자세하게 정리가 되어있다. 내가 자주쓰는 스타일 및 색상들만 정리해보면 다음과 같다.
- Line Style
| Parameter | 내용 |
|---|---|
| ’-‘ | 실선 |
| ’–’ | 점선 |
| ’.’ | 포인트 마커 |
| ‘o’ | 원형 마커 |
| ‘D’ | 다이아몬드(대) 마커 |
| ‘d’ | 다이아몬드(소) 마커 |
| ’^’ | 세모(상) 마커 |
| ’>’ | 세모(우) 마커 |
| ’<’ | 세모(좌) 마커 |
Style은 선과 마커로 지정할 수 있으며, '-o'(원형 마커가 있는 실선)와 같이 선과 마커를 연결해서 바로 사용할 수도 있다.
- Color
| Parameter | 내용 |
|---|---|
| ‘b’ | blue |
| ‘g’ | green |
| ‘r’ | red |
| ‘y’ | yellow |
| ‘k’ | black |
| ‘w’ | white |
Color는 단일 축약문자로 옵션을 지정할 수도 있고, blue처럼 풀네임으로 지정해줘도 된다.
- Color map
Color map은 3차원 데이터를 시각화 할때(z값 존재) 활용된다.
(참조 : 공식 문서)
1-3. 그래프 설정
단순히 그래프를 그리는 것으로 끝나는게 아니라, 그래프 제목(title)이나 축, 범례 등 더 가시적인 시각화를 위해 부수적으로 지정해줄 수 있는 것들이 많다. 개인적으로 자주쓰는 것만 써보면 아래와 같다.
plt.figure(figsize=(n,m)): 그래프 크기 조절plt.title("text", fontsize=15): 그래프 제목설정plt.xlim([min, max]): x축 범위 설정plt.ylim([min, max]): y축 범위 설정plt.xlabel("text", fontsize=15): x축 라벨 설정plt.ylabel("text", fontsize=15): y축 라벨 설정plt.grid(): 격자 생성plt.savefig('저장경로'): 그래프 저장plt.legend(): 범례 표시plt.text(x,y, "text"): 텍스트 표시plt.xaxis(rotation = 90, fontsize = '15'): x축 폰트 회전 및 크기 설정plt.yaxis(rotation = 90, fontsize = '15'): y축 폰트 회전 및 크기 설정
2. 히스토그램과 막대그래프
이제 다양한 방식으로 시각화를 해보자. matplotlib를 활용한 방법과 Pandas의 내장된 기능을 활용하는 방법을 동시에 소개한다.
예제 데이터로는 kaggle의 타이타닉 데이터를 활용한다.(해당 데이터에 대한 자세한 정보는 타이타닉 포스팅을 참고)
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/yganalyst/data_example/main/titanic/train.csv", dtype=str)
df[["Age","Fare","Pclass"]] = df[["Age","Fare","Pclass"]].astype(float)
df["Age"] = df["Age"].fillna(df["Age"].median())
df.head(5)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3.0 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1.0 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3.0 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1.0 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3.0 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
2-1. Histogram
히스토그램은 특정 변수를 구간화(binning)하고 각 구간내에 속하는 데이터를 Count해 빈도를 계산하는 방법이다.
plt.title("Histogram", fontsize=15)
frq, bins, fig = plt.hist(df["Age"], bins=10, alpha=.8, color='grey')
plt.ylabel("빈도", fontsize=13)
plt.xlabel("연령대", fontsize=13)
plt.grid()
plt.show()
print("*빈도 array :", frq)
print("*구간 array :", bins)
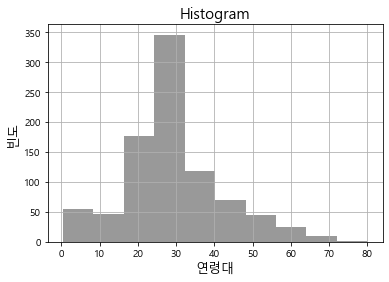
*빈도 array : [ 54. 46. 177. 346. 118. 70. 45. 24. 9. 2.]
*구간 array : [ 0.42 8.378 16.336 24.294 32.252 40.21 48.168 56.126 64.084 72.042
80. ]
위와 같이 bins옵션으로 몇개의 구간으로 나눌지를 결정할 수 있고, 결과로 그래프와 값들을 반환한다.
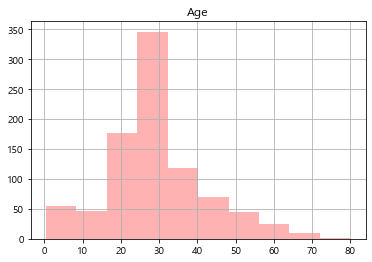
# Pands 내장기능
df[["Age"]].hist(bins=10, alpha=.3, color='r')
plt.show()
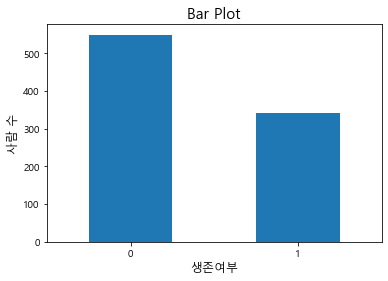
2-2. Bar plot
막대그래프는 특정 범주형 변수(x)와 그 크기(height)를 표현할 때, 주로 활용된다. value_counts를 이용해 생존자를 count하고 이를 막대그래프로 그려보자.
bar_df = df["Survived"].value_counts().reset_index()
plt.title("Bar Plot", fontsize=15)
plt.bar(bar_df["index"], bar_df["Survived"],color='k', alpha=.3)
plt.ylabel("사람 수", fontsize=12)
plt.xlabel("생존여부", fontsize=12)
plt.show()

아래와 같이 x축과 y축을 바꿔서 옆으로 누워있는 막대그래프도 생성할 수 있다.
bar_df = df["Survived"].value_counts().reset_index()
plt.title("Bar Plot", fontsize=15)
plt.barh(bar_df["index"], bar_df["Survived"],color='k', alpha=.3)
plt.xlabel("사람 수", fontsize=12)
plt.ylabel("생존여부", fontsize=12)
plt.show()

# Pandas 내장기능
df["Survived"].value_counts().plot(kind='bar')
plt.title("Bar Plot", fontsize=15)
plt.ylabel("사람 수", fontsize=12)
plt.xlabel("생존여부", fontsize=12)
plt.xticks(rotation=0)
plt.show()
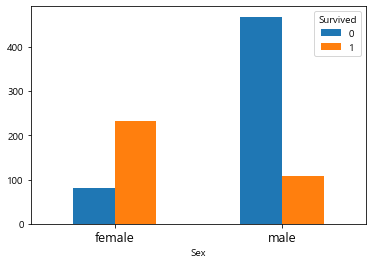
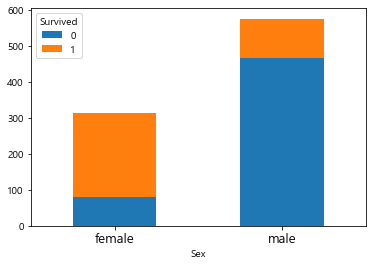
2-3. Stacked Bar Plot
누적막대그래프는 1개의 차원이 더 추가되었을때(예를들면 성별, 생존여부별, 사람 수) 가시적으로 보여주기 좋다. 이는 Pandas 내장기능을 활용하는 것이 훨씬 편리하므로 이 부분만 소개한다.
Pandas 내장기능 활용 시에는 데이터 구조를 알맞게 만들어주는 것이 중요하다.
stacked_bar_df = df.groupby(["Sex","Survived"]).size().unstack()
stacked_bar_df
| Survived | 0 | 1 |
|---|---|---|
| Sex | ||
| female | 81 | 233 |
| male | 468 | 109 |
위와 같은 구조로 만들어졌으면, bar plot을 생성한다.
# 개별적으로 보여주기
stacked_bar_df.plot(kind='bar')
plt.xticks(rotation=0, fontsize=13)
plt.show()
# 쌓아서 보여주기
stacked_bar_df.plot(kind='bar', stacked=True)
plt.xticks(rotation=0, fontsize=13)
plt.show()
3. 산점도(Scatter Plot)
산점도는 말 그대로 데이터를 그래프상에 점(Point)으로 뿌림으로써 어떻게 분포하고 있는지를 확인하기 위한 방법으로 사용된다. 2차원, 3차원, 밀도의 표현 등 산점도의 다양한 시각화 방법에 대해 알아보자.
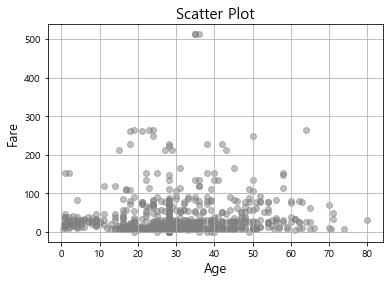
3-1. Scatter Plot(2D)
산점도를 그릴때는 scatter함수를 사용해도 되고 그냥 plot함수에서 marker만 그려도 된다(개인적으로는 plot함수만 씀).
plt.scatter(x,y, s=마커 크기 값(또는 배열), c=마커 색 값(또는 배열))을 통해 다양한 방식으로 시각화가 가능하다.
plt.title("Scatter Plot", fontsize=15)
plt.scatter(df["Age"], df["Fare"], color='grey', alpha=.5)
plt.xlabel("Age", fontsize=13)
plt.ylabel("Fare", fontsize=13)
plt.grid()
plt.show()
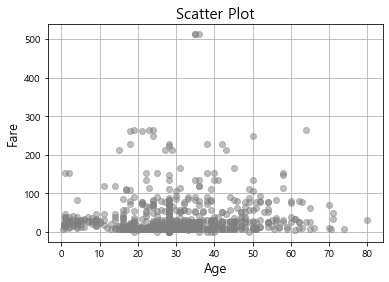
# plot 사용시 marker를 지정해주기
plt.title("Scatter Plot", fontsize=15)
plt.plot(df["Age"], df["Fare"],'o', color='grey', alpha=.5)
plt.xlabel("Age", fontsize=13)
plt.ylabel("Fare", fontsize=13)
plt.grid()
plt.show()
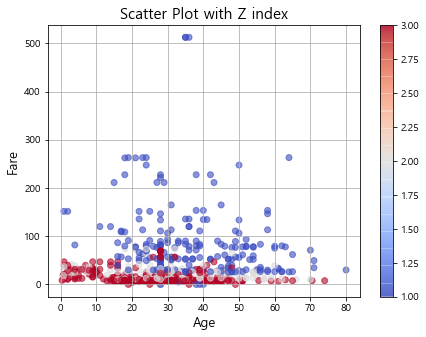
추가적으로 옵션 s(사이즈)와 c(컬러)를 활용해서 z값도 시각화를 할 수 있다.
plt.figure(figsize=(7,5))
plt.title("Scatter Plot with Z index", fontsize=15)
plt.scatter(df["Age"], df["Fare"], c=df["Pclass"], cmap='coolwarm', alpha=.6)
plt.xlabel("Age", fontsize=13)
plt.ylabel("Fare", fontsize=13)
plt.grid()
plt.colorbar()
plt.show()
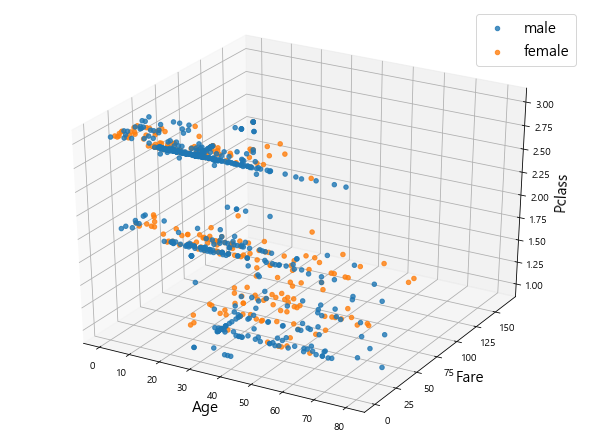
3-2. Scatter Plot(3D)
z축을 포함한 3차원 공간상에 데이터를 시각화할 수도 있다. 여기에 라벨링까지하면 4개의 변수를 시각화하여 많은 정보를 한번에 가시적으로 확인할 수 있는 장점이 있다. 이를 위해서 Axes3D를 활용한다.
df_t = df[df["Fare"]<=200]
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize = (8, 6))
plt.title("K_Clusters")
ax = Axes3D(fig)
for i_ in ["male", "female"]:
tt = df_t[df_t["Sex"]==i_]
ax.scatter(tt["Age"], tt["Fare"], tt["Pclass"], alpha=.8,label=i_,)
ax.set_xlabel('Age', fontsize=15)
ax.set_ylabel('Fare', fontsize=15)
ax.set_zlabel('Pclass', fontsize=15)
ax.legend(fontsize=15)
plt.show()
3-3 Scatter Plot와 도수(hist)
앞서 산점도의 시각화 방법을 소개했는데, 단순히 점을 뿌리기만 한다면 데이터의 분포는 확인할 수 있지만 점들이 어디에 밀집되어 있는 가에 대한 밀도에 대한 식별을 하기는 어렵다.
적당하게 alpha값으로 투명도를 줄 순 있겠지만 격자를 나눠서 빈도(frequency)를 확인하면 더 명확하게 알 수 있다.
plt.hist2d(x,y, (가로 셀 개수, 세로 셀 개수), 이하 옵션 동일)함수를 활용할 수 있다.
plt.figure(figsize=(8,6))
plt.scatter(df["Age"], df["Fare"], edgecolor='')
# 도수의 표현
hist, xbins, ybins, im = plt.hist2d(df["Age"], df["Fare"], (4, 4), alpha=.8, cmap=plt.cm.jet)
# 각 셀의 텍스트 표기
for i in range(len(ybins)-1):
for j in range(len(xbins)-1):
plt.text(xbins[j]+10,ybins[i]+55, str(int(hist.T[i,j])), fontsize=13,
color="w", ha="center", va="center", fontweight="bold")
plt.xticks(fontsize=13)
plt.yticks(fontsize=13)
plt.colorbar()
plt.show()
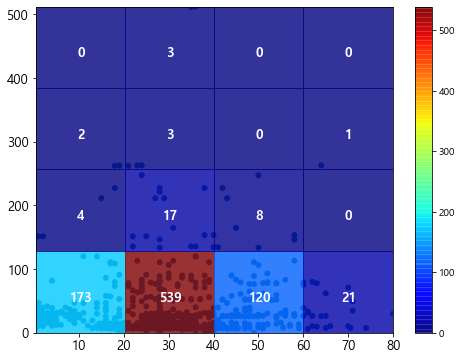
단순히 점들의 분포 뿐만 아니라, 어디에 더 많은 점들이 밀집되어 있는지 명확하게 확인할 수 있다.
3-4. Scatter Plot과 밀도(Density)
또 다른 방법으로는 격자형으로 나누지 않고 그래프 상의 점들의 밀도를 계산하고, 이를 scatter함수의 속성으로 넣어주는 방법도 있다.
scipy라이브러리의 gaussian_kde를 활용할 수 있다. kde는 커널밀도추정(Kernel density Estimation)의 약자로 bin으로 구간화를 한 뒤 도수를 표현하는 histogram을 smoothing하여 연속적인 밀도의 표현이 가능한 통계적 방법이다. 가우시안(gaussian)은 그 방법중 하나이다.
자세한 내용은 여기를 참고하고 추후 포스팅을 할 예정이다.
from scipy.stats import gaussian_kde
x = df["Age"]
y = df["Fare"]
# gaussian kde 계산
xy = np.vstack([x,y])
z = gaussian_kde(xy)(xy)
idx = z.argsort()
x, y, z = x[idx], y[idx], z[idx]
# 시각화
plt.figure(figsize=(8,5))
plt.scatter(x, y, c=z, s=50, cmap=plt.cm.jet, edgecolor='')
plt.colorbar()
plt.show()
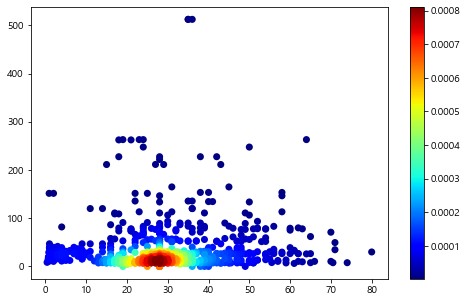
4. Box plot
상자그림은 데이터의 기초통계와 편차를 확인하는 용도로 활용한다. 단순히 시각화만 하는 것이 아니라 통계적인 해석도 중요하기 때문에 관련 설명이 필요하다.
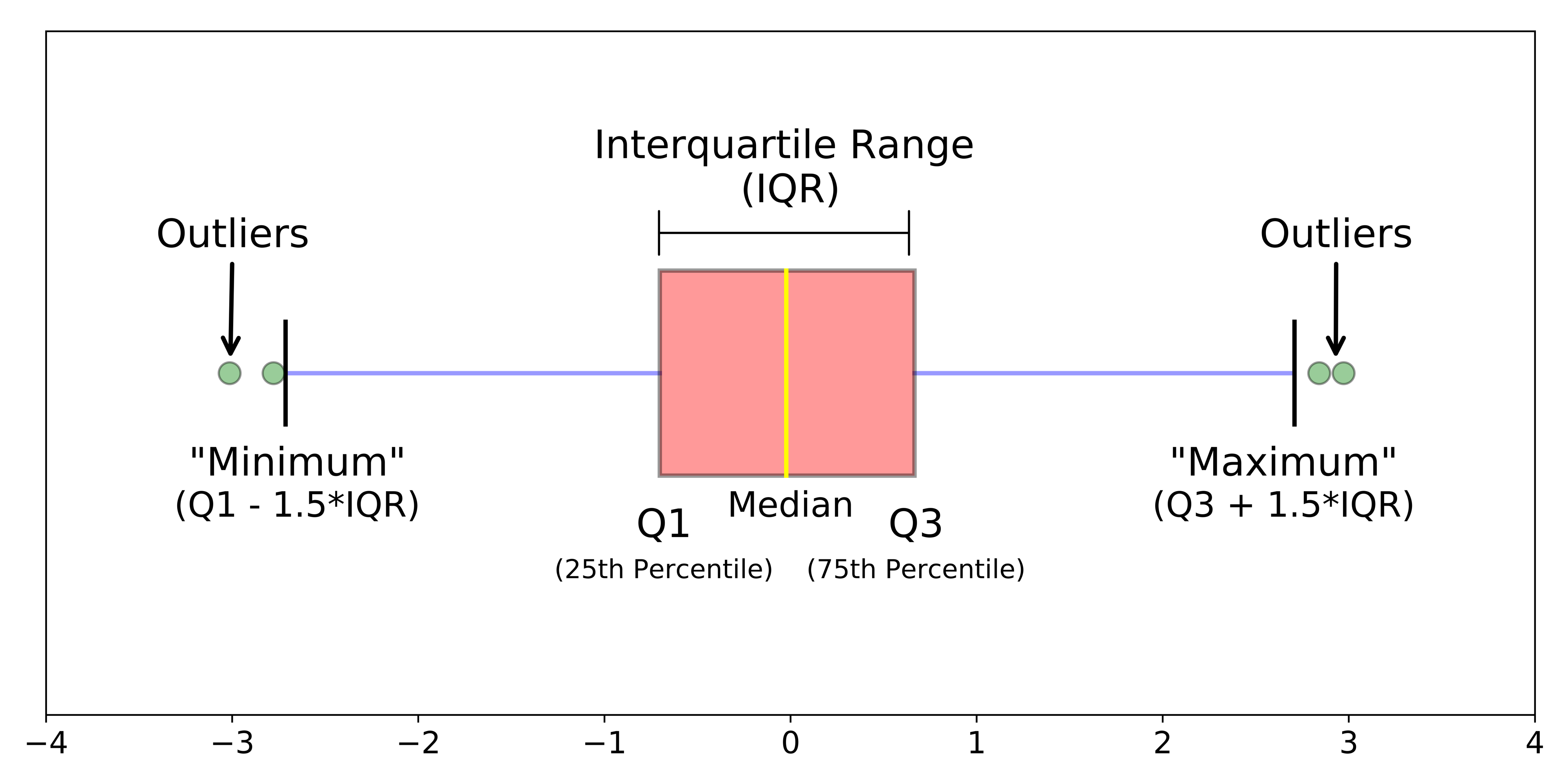
위와 같이 상자그림을 그리면 5개의 수치를 얻을 수 있다.
- 최솟값 : Q1 - 1.5*IQR
- 1사분위(Q1) : 25% 위치의 수
- 2사분위(Q2) : 50% 위치의 수, 중앙값(median)을 의미
- 3사분위(Q3) : 75% 위치의 수
- 최대값 : Q3 + 1.5*IQR
(IQR = Q3 - Q1)
이를 통해 데이터의 전체적인 분포와 극단치가 존재하는지를 확인할 수 있다. 편의를 위해 시각화와 수치를 얻는 함수를 만들어서 시각화해보자.
def plot_box(df, colname):
box_ = plt.boxplot(df[colname], labels=[colname])
plt.show()
dict_ = {}
dict_["label"] = colname
dict_["cap_bottom"] = box_['caps'][0].get_ydata()[0]
dict_["perc_25"] = box_['boxes'][0].get_ydata().min()
dict_["median"] = box_['medians'][0].get_ydata()[1]
dict_["perc_75"] = box_['boxes'][0].get_ydata().max()
dict_["cap_top"] = box_['caps'][1].get_ydata()[0]
return pd.DataFrame([dict_])
plot_box(df, "Age")
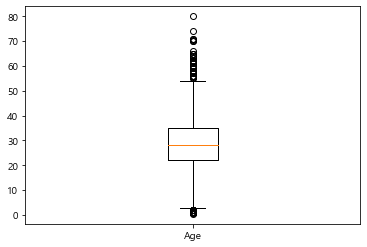
| label | cap_bottom | perc_25 | median | perc_75 | cap_top | |
|---|---|---|---|---|---|---|
| 0 | Age | 3.0 | 22.0 | 28.0 | 35.0 | 54.0 |

댓글남기기