
[시각화] 레이더(Radar), 거미줄(spider) 그래프
업데이트:
개요
이번 포스팅에서는 레이더(Radar) 또는 거미줄(Spider) 차트라고 불리는 시각화 방법에 대해 알아보자.
레이더(Radar) 차트는 여러 개일 때 항목 수에 따라 원을 같은 간격으로 나누고, 중심으로부터 각 평가항목 간 균형을 한눈에 볼 수 있도록 해주는 도표이다. 여러 측정 목표를 함께 겹쳐 놓아 비교하기에도 편리하고 비율뿐만 아니라 균형과 경향을 직관적으로 알 수 있어 편리하다(참고).
예제 데이터
사용할 예제 데이터는 타이타닉 데이터 이고 기본 설정에 대한 정보들은 시각화 포스팅을 참고하면 좋을 것 같다.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/yganalyst/data_example/main/titanic/train.csv", dtype=str)
df[["Age","Fare","Pclass"]] = df[["Age","Fare","Pclass"]].astype(float)
df["Age"] = df["Age"].fillna(df["Age"].median())
df.head(5)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3.0 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1.0 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3.0 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1.0 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3.0 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
간단한 클러스터링
이번 포스팅에서는 타이타닉 탑승자들을 간단하게 클러스터링을 하고, 어떤 성향을 가진 사람들로 묶여졌는지를 Radar 차트를 통해 확인해보는 것을 목표로 한다. 클러스터링과 관련한 자세한 이론적 내용들은 추후에 따로 포스팅할 예정이다.
cls_df = df[["Sex","Age"]].copy()
cls_df["Age"] = np.where(cls_df["Age"]<=19, "0~10대",
np.where(cls_df["Age"]<=39, "2~30대",
np.where(cls_df["Age"]<=59, "4~50대","60대 이상")))
from sklearn.cluster import KMeans, AgglomerativeClustering
from sklearn.preprocessing import LabelEncoder
cls_df_ = cls_df.copy()
label_df = pd.DataFrame()
for c_ in cls_df.columns:
encoder = LabelEncoder()
cls_df_[c_] = encoder.fit_transform(cls_df_[c_]).copy()
sr_ = pd.Series(encoder.classes_, name=c_)
label_df = pd.concat([label_df,sr_], axis=1)
kmeans_clusters = KMeans(n_clusters=3, random_state=42).fit(cls_df_) # 초기중심점 지정
cls_df['cluster_id'] = kmeans_clusters.labels_ + 1
cls_df = pd.get_dummies(cls_df, prefix='', prefix_sep='')
cls_df = cls_df.groupby(["cluster_id"]).sum().reset_index()
for c_t in [["female",'male'],['0~10대','2~30대','4~50대','60대 이상']]:
total_ = cls_df[c_t].sum(axis=1).sum().copy()
for c_ in c_t:
cls_df[c_] = cls_df[c_] / total_
cls_df.head()
| cluster_id | female | male | 0~10대 | 2~30대 | 4~50대 | 60대 이상 | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 0.000000 | 0.525253 | 0.099888 | 0.425365 | 0.00000 | 0.000000 |
| 1 | 2 | 0.291807 | 0.000000 | 0.084175 | 0.207632 | 0.00000 | 0.000000 |
| 2 | 3 | 0.060606 | 0.122334 | 0.000000 | 0.000000 | 0.15376 | 0.029181 |
위와 같이 대충 데이터셋을 만들어 봤다..
- 클러스터링할 변수를 선택(성별, 연령대)하고 categorical하게 인코딩
- kmeans(k=3)를 돌리고
- dummy변수로 바꾸고
- 각 범주에 대한 개별 원소의 비율로 표준화
레이더(Radar) 그래프 시각화
이제 위 데이터를 가지고 한번 클러스터별 시각화를 해보자.
다음은 이 포스팅의 핵심인 Radar chart를 그리는 함수이다. 여기를 참고했음
from math import pi
def plot_radar_chart(df, group_id):
# 변수 수
cls_df_sel = df.drop(group_id, axis=1).copy()
categories=list(cls_df_sel)
N = len(categories)
# value 계산
cls_df_sel = cls_df_sel[cls_df_sel.columns.tolist() + [cls_df_sel.columns.tolist()[0]]].copy()
values = cls_df_sel.values
# 변수의 수에 따른 angle 계산
angles = [n / float(N) * 2 * pi for n in range(N)]
angles += angles[:1]
# 그래프 창
plt.figure(figsize=(8,8))
ax = plt.subplot(111, polar=True)
# x축 라벨링
plt.xticks(angles[:-1], categories, color='grey', size=15)
#y축 라벨링
ax.set_rlabel_position(0)
plt.yticks([0, 0.1, 0.2, 0.3, 0.4, 0.5], ["0%","10%","20%","30%","40%","50%"], color="grey", size=12)
plt.ylim(0,0.6)
# 데이터 plotting
color_ = ['b','r','g']
for cl_n in [0,1,2]:
ax.plot(angles, values[cl_n], linewidth=2, linestyle='solid',color= color_[cl_n], label='cluster_'+str(cl_n+1), alpha=0.7)
ax.fill(angles, values[cl_n],color_[cl_n], alpha=0.4)
plt.legend(loc='lower center', fontsize=13)
plt.tight_layout()
plt.show()
그리는 방법의 핵심은 다음과 같다.
plt.subplot(polar=True): Axes를 추가할때 옵션을 줘서 원형의 축을 가지도록 해야한다.angle: 축은 원형이므로 angle을 x값으로 하는데, 원의 지름을 변수의 수로 나눠서 구해준다.fill: 같은 방식으로 plot하고 fill로 내부를 채워준다.
plot_radar_chart(cls_df, "cluster_id")
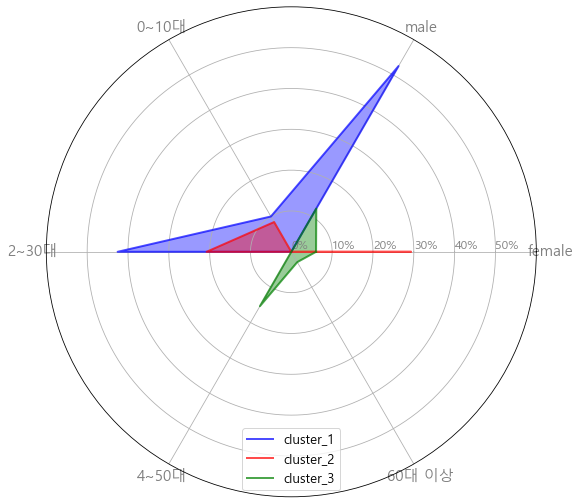
(예시 데이터를 정말 못만들어서… 결과가 너무 안예쁘네 죄송ㅠㅠ)
그래도 나름 평가해 보자면,
- 1번 클러스터 : 0~30대 여성층
- 2번 클러스터 : 2~30대 남성층(가장 많이 포함)
- 3번 클러스터 : 4~50대 남여 골고루
실제로 CRM분석에 이 Radar Chart를 활용한 적이 있다.
현업에서 쓰이는 주관적인 고객 분류 기준과 방식 대신 비지도적으로 군집을 형성한 고객의 특성을 역으로 추적해 나가며 재미있는 분석을 했었다.
다양하게 사용되겠지만, 특히 클러스터별 표준화된 기준을 통해 차이를 비교할때 유용하게 사용할 수 있는 것 같다.

댓글남기기