
[SQLD (1-2)] 데이터 모델과 성능
업데이트:
개요
![]()
이번 포스팅은 데이터 자격 검정인 SQL 개발자(SQLD) 시험을 기반으로 공부했던 자료이다.
시험을 위한 공부이긴 했지만, 정리했던 자료가 향후에 도움이 많이 될 것 같다.
1. 성능 데이터 모델링의 개요
성능 데이터 모델링
- 데이터베이스 성능향상을 목적으로 설계단계의 데이터 모델링 때부터 정규화, 반정규화, 테이블통합, 테이블분할, 조인구조, PK, FK 등 여러 가지 성능과 관련된 사항이 데이터 모델링에 반영될 수 있도록 하는 것
수행 시점 (분석/설계 단계부터, 일찍부터 하는게 좋다)
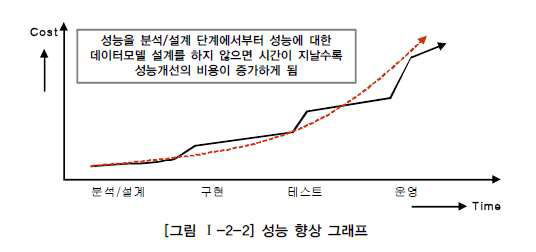
성능 데이터 모델링 고려사항 (정용트반 이성)
① 데이터 모델링을 할 때 정규화를 정확하게 수행한다.
② 데이터베이스 용량산정을 수행한다.
③ 데이터베이스에 발생되는 트랜잭션의 유형을 파악한다.
④ 용량과 트랜잭션의 유형에 따라 반정규화를 수행한다.
⑤ 이력모델의 조정, PK/FK조정, 슈퍼타입/서브타입 조정 등을 수행한다.
⑥ 성능관점에서 데이터 모델을 검증한다.
2. 정규화와 성능
정규화 : 데이터를 결정하는 결정자에 의해 함수적 종속을 가지고 있는 일반속성을 의존자로 하여 입력/수정/삭제 이상을 제거하는 것
정규화와 성능관계 (조회성능은 저하될 수 도 있음)
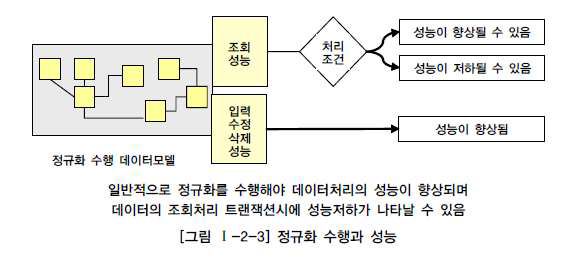
- 반정규화만이 조회성능을 향상시키는 것은 아니라는 4가지 사례가 있음
함수적 종속성 : 데이터들이 어떤 기준값에 의해 종속되는 현상으로 이에 근거하여 정규화가 이루어져야함
- 기준값 : 결정자(Determinant)
- 종속값 : 종속자(Dependent)
정규화 종류
1차 정규화 : 속성이 원자값(Atomic Value)을 갖도록 함. “기본키” 보유.
- 같은 성격과 내용의 속성이 중복될 때,
- 중복 값은 제거
- 새로운 테이블 추가 (PK 추가)
- (기존 테이블과) 1:M 관계 형성
- 예제 : ‘기능분류코드’ 속성 차원에서, 같은 속성인데 칼럼 단위로 반복되고 있다.
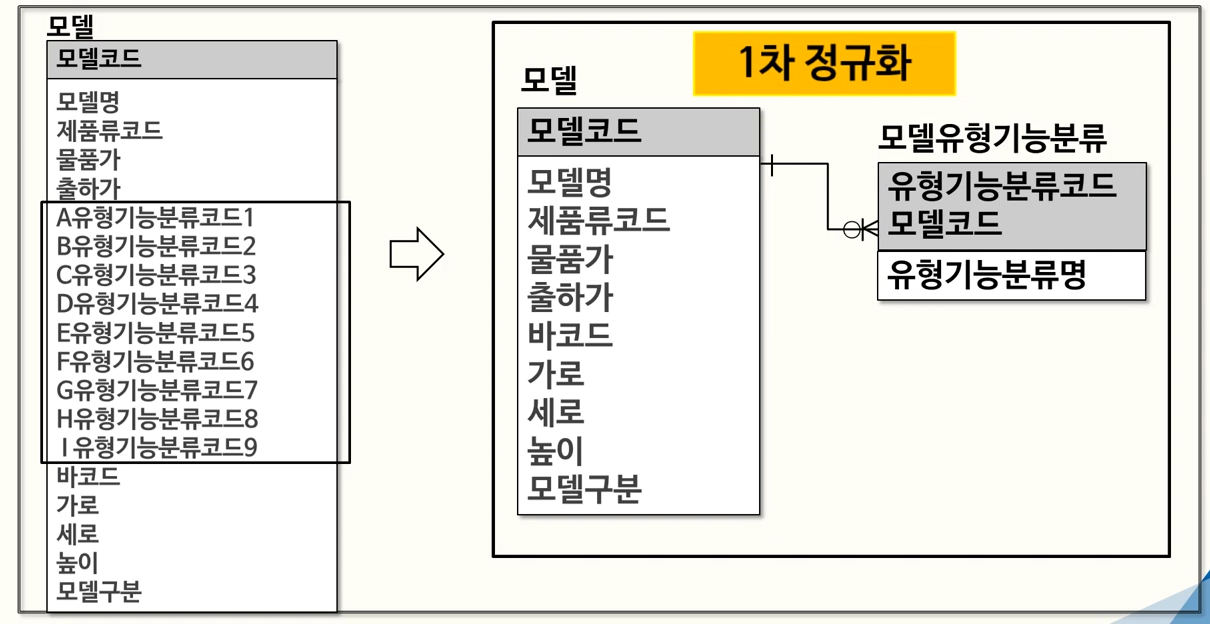
- 1차 정규화 대상으로, 새 테이블을 추가하여 오른쪽과 같이 수정
- (모델, 모델 유형기능분류 테이블은 각각 1:M 관계)
- 예제 :
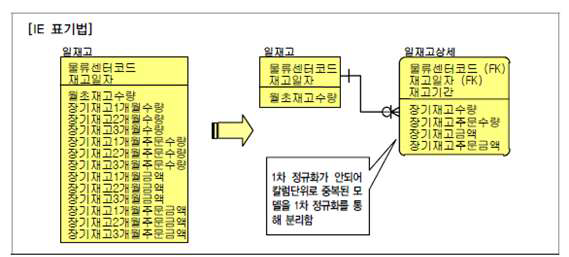
- 일재고와 일재고 상세를 구분함으로써, 일재고에 발생되는 트랜잭션의 성능저하를 예방할 수 있게 되었다.
2차 정규화 : 기본키가 2개 이상의 속성일 때. “부분 함수 종속성 제거”
- PK(Primary Key)가 2개 이상일 때,종속되는 관계가 있다면 분리한다.
- 함수적 종속성(FD) : 데이터들이 어떠한 기준에 의해서 종속되는 것을 의미
- 완전 함수 종속적 : 기본키에 대해서 그 속성이 완전히 종속될 때
- 부분 함수적 종속 : 기본키 전체가 아니라, 일부에 대해 종속될 때
- 예시 : 기본키 ‘관서번호’, ‘납부자번호’가 2개 이상이므로, 이를 복합키라고 한다.복합키 일부분에 종속되는 속성이 있으므로, 이를 구분하여 분리해준다.
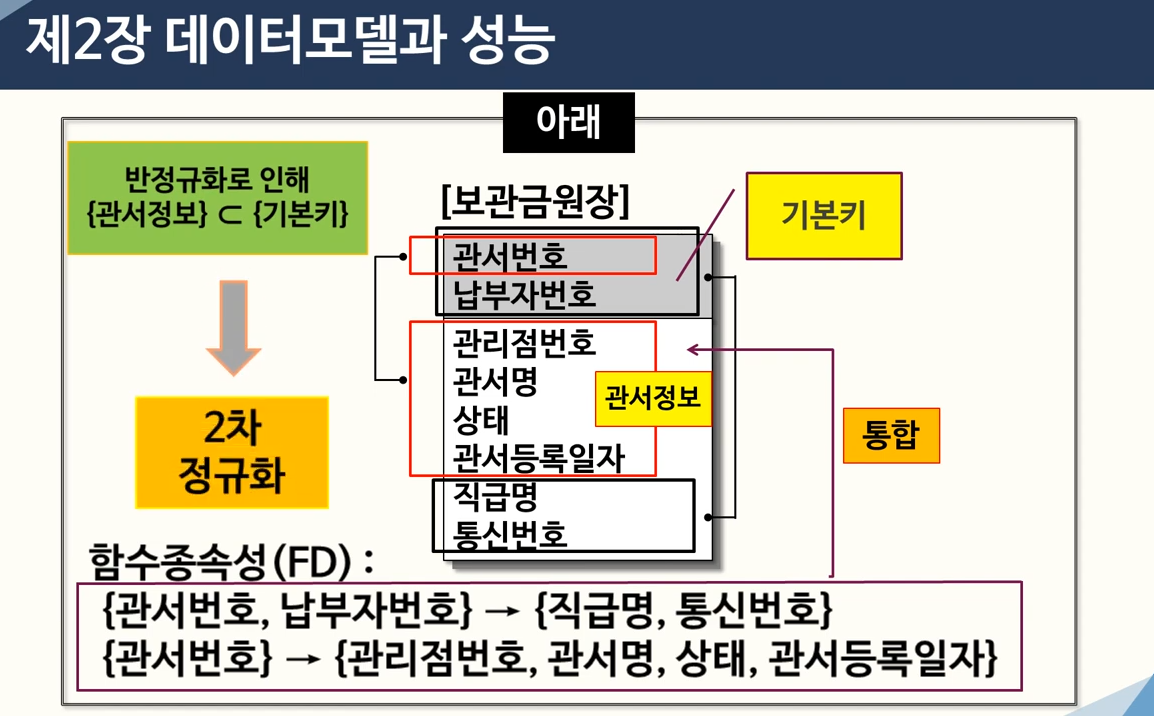
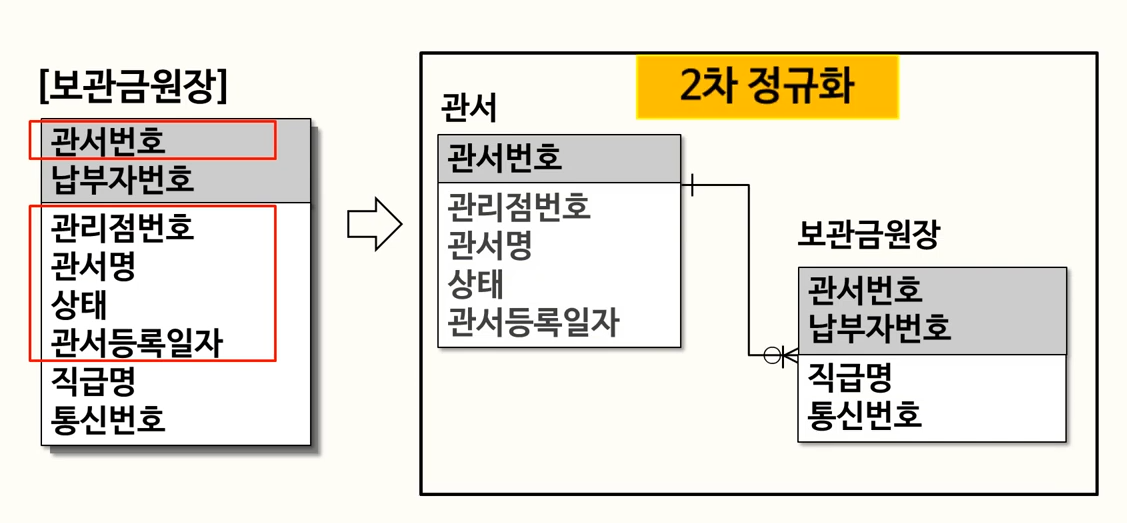
- 관서번호/ 관서번호,납부자번호로 분리하여, “2차 정규화”를 진행해주었다.
- 예시 : 미리 지정된 함수 종속성에 따라, 2차 정규화를 진행하여 분리해주었다.
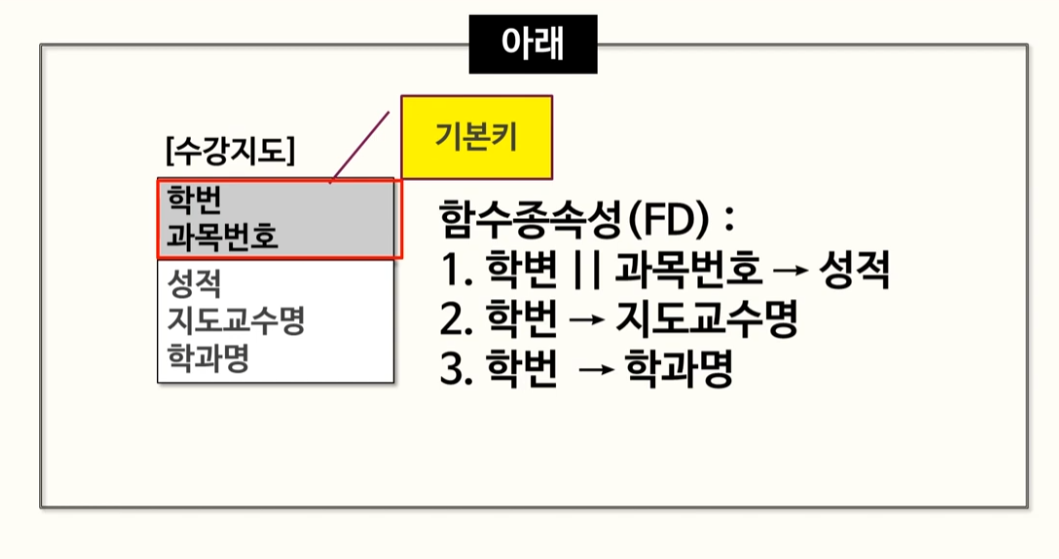
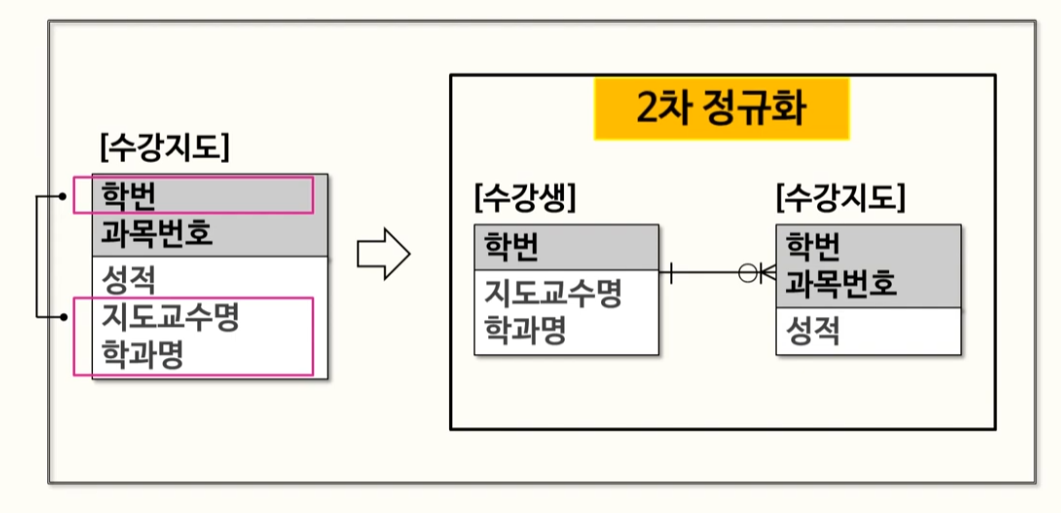
- 예시 : 물건을 매각할 때 매각일자를 정하고 그 일자에 해당하는 매각시간과 매각장소가 결정하는 속성의 성격, 즉, 매각일자가 결정자가 되고 매각시간과 매각장소가 의존자가 되는 함수적 종속관계가 형성되는 관계 (매각일자가 같으면, 매각시간과 장소도 같다는 얘기)
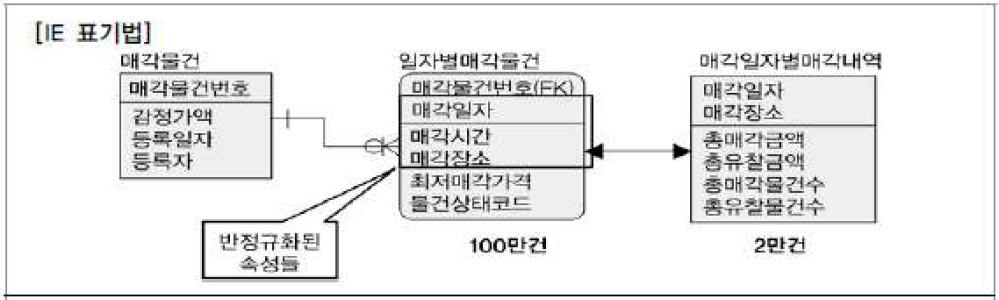
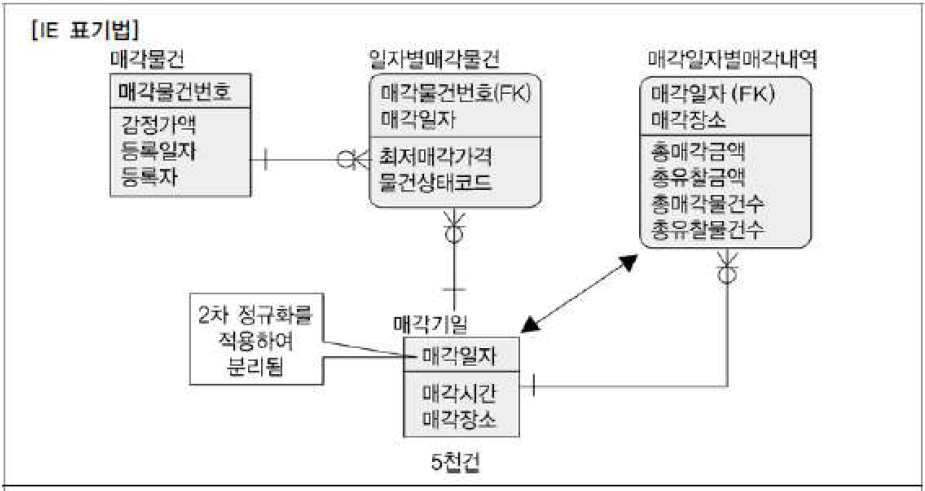
- 2차 정규화를 적용하여 매각일자를 PK로 하고 매각시간과 매각장소는 일반속성으로 하는 매각기일 테이블 생성
- 매각내역을 조회할때 읽어야 하는 테이블이 항상 100만건에서 5천건으로 변경되어 조회 성능이 빨라짐
- 즉, 매각기일과 일자별매각물건은 1:M 관계
3차 정규화 : 이진적 함수 종속 관계
- 기본 키에 의존하지 않고, 일반 컬럼에 의존하는 컬럼이 있다면 이를 제거한다.
- 예시 :
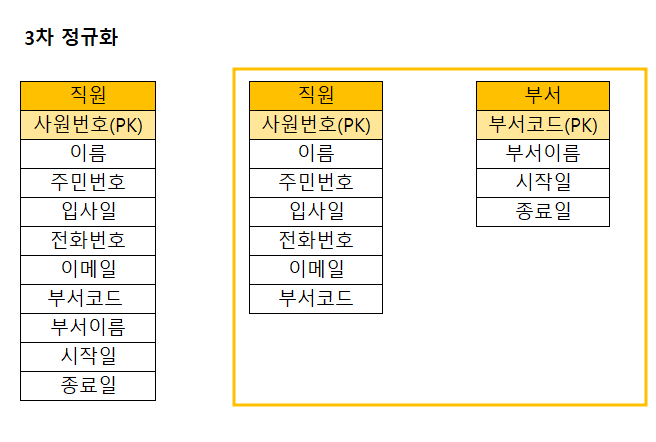
- 직원 테이블에 기본 키인 ‘사원번호’ 외에 의존하는 컬럼이 있다.
- 부서코드와 부서이름은 ‘부서’ 테이블에 속해야 할 사항이다.
- → 데이터가 중복되어, 저장 공간이 낭비되고 있다.
정규화 vs 정규형
- 정규화 : 데이터 분해 과정, 이상현상 제거
- 정규형 : 정규화로 도출된 데이터 모델이 갖춰야 할 특성
3. 반정규화와 성능
반정규화 : 정규화된 엔터티, 속성, 관계에 대해 시스템의 성능향상과 개발(Development)과 운영(Maintenance)의 단순화를 위해 중복, 통합, 분리 등을 수행하는 데이터 모델링의 기법
- 데이터를 조회할 때 디스크 I/O량이 많아서 성능이 저하되거나 경로가 너무 멀어 조인으로 인한 성능저하가 예상되거나 칼럼을 계산하여 읽을 때 성능이 저하될 것이 예상되는 경우 수행
- ex) 정규화가 되어서 다 분리되있으면, 조회하기 위해 Join하고 해야하는데, 이걸 그냥 중복된 값으로 다시 반정규화해서 조회성능을 올림
- 데이터 무결성이 깨질 가능성이 많음
반정규화 절차
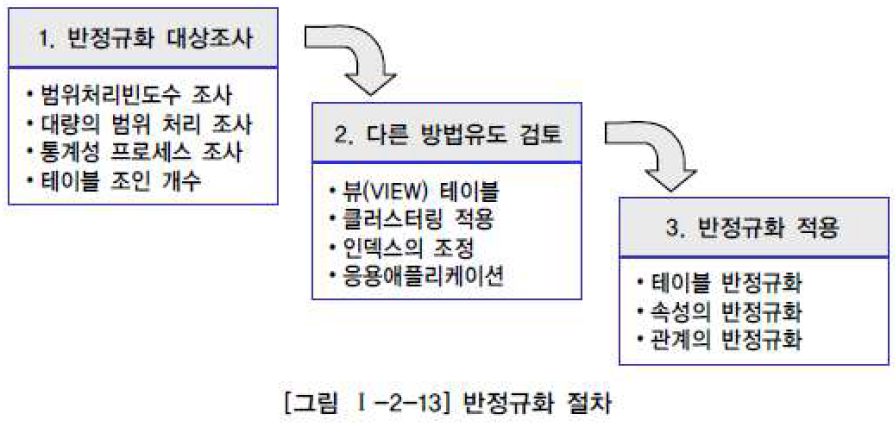
- 반정규화 대상조사
- 자주 사용되는 테이블에 접근(Access)하는 프로세스의 수가 많고 항상 일정한 범위만을 조회하는 경우
- 테이블에 대량의 데이터가 있고 대량의 데이터 범위를 자주 처리하는 경우에 처리범위를 일정하게 줄이지 않으면 성능을 보장할 수 없을 경우
- 통계성 프로세스에 의해 통계 정보를 필요로 할 때 별도의 통계테이블(반정규화 테이블)을 생성
- 테이블에 지나치게 많은 조인(JOIN)이 걸려 데이터를 조회하는 작업이 기술적으로 어려울 경우
- 다른 방법 유도 검토
- 뷰(VIEW) 사용 : 지나치게 많은 조인(JOIN)이 걸려 데이터를 조회하는 작업이 기술적으로 어려울 경우, 조회의 성능을 향상시키진 않음
- 클러스터링 : 대량의 데이터처리나 부분처리에 의해 성능이 저하되는 경우에 클러스터링을 적용하거나 인덱스를 조정함으로써 성능을 향상
- 파티셔닝 : 대량의 데이터는 Primary Key의 성격에 따라 부분적인 테이블로 분리(Partitioning)할 수 있음, 파티셔닝 Key에 의해 물리적인 저장공간이 구분
- 캐쉬 : 응용 애플리케이션에서 로직을 구사하는 방법을 변경
- 반정규화 적용
반정규화 기법
- 테이블 반정규화
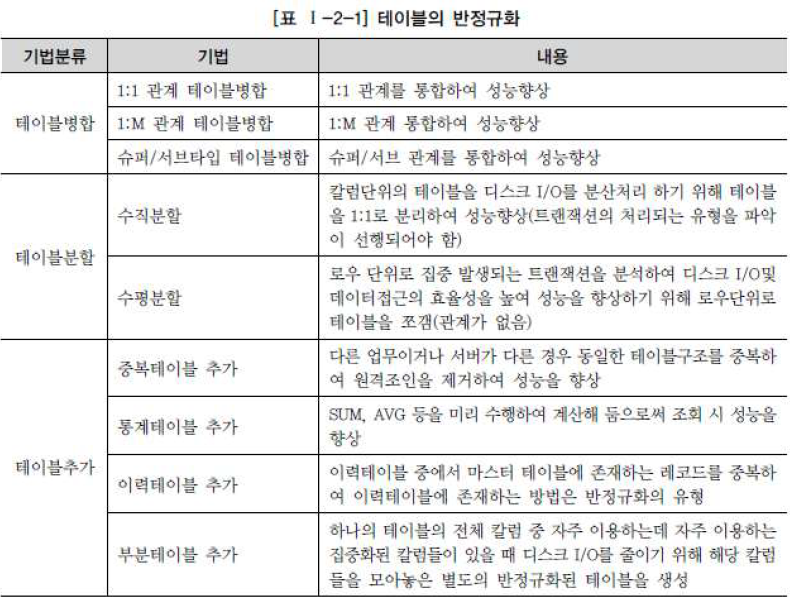
- 컬럼 반정규화

- 관계 반정규화

- 데이터 무결성을 꺠는 문제는 없음
4. 대량 데이터에 따른 성능
컬럼이 많아짐에 따라 성능이 저하되는 유형
- 로우 체이닝(Row Chaining) : 로우 길이가 너무 길어서 데이터 블록 하나에 데이터가 모두 저장되지 않고 두 개 이상 의 블록에 걸쳐 하나의 로우가 저장되어 있는 형태
- 로우 마이그레이션(Row Migration) : 데이터 블록에서 수정이 발생하면 수정된 데이터를 해당 데이터 블록에서 저장하지 못하고 다른 블록의 빈 공간을 찾아 저장하는 방식
- ⇒ 트랜잭션을 분석하여 적절하게 1:1 관계로 분리함으로써 성능향상이 가능하도록 해야함
PK에 의해 테이블을 분할하는 방법 (파티셔닝)
- Range Partition
- 대상 테이블이 날짜 또는 숫자값으로 분리가 가능하고 각 영역별로 트랜잭션이 분리되는 경우
- ex) 요금 테이블 → 요금_0401, 요금_0402, etc.
- Hash Partition
- 지정된 HASH 조건에 따라 해슁 알고리즘이 적용되어 테이블이 분리됨
- List Partition
- 지점, 사업소, 사업장, 핵심적인 코드값 등으로 PK가 구성되어 있고 대량의 데이터가 있는 테이블이라면 값 각각에 의해 파티셔닝
- ex) 고객 테이블 → 고객_서울, 고객_경기, etc.
테이블에 대한 수평/수직분할의 절차
- 데이터 모델링을 완성
- 데이터베이스 용량산정
- 대량 데이터가 처리되는 테이블에 대해서 트랜잭션 처리 패턴을 분석
- 칼럼 단위로 집중화된 처리가 발생하는지, 로우단위로 집중화된 처리가 발생되는지 분석하여 집중화된 단위로 테이블을 분리하는 것을 검토
5. 데이터베이스 구조와 성능
슈퍼/서브 타입 모델 : 업무를 구성하는 데이터의 특징을 공통과 차이점의 특징을 고려하여 효과적으로 표현
- 슈퍼 타입 : 공통의 부분
- 서브 타입 : 공통으로부터 상속받아 다른 엔터티와 차이가 있는 속성
- 논리적 데이터 모델에서 사용
- 분석단계에서 사용
슈퍼/서브 타입 데이터 모델의 변환 기술 : 물리적 데이터 모델링 단계에서는 변환해서 써야함
- OneToOne Type : 개별로 발생되는 트랜잭션에 대해서는 개별 테이블로 구성
- Plus Type : 슈퍼타입+서브타입에 대해 발생되는 트랜잭션에 대해서는 슈퍼타입+서브타입 테이블로 구성
- Single Type, All in one : 전체를 하나로 묶어 트랜잭션이 발생할 때는 하나의 테이블로 구성
인덱스 특성을 고려한 PK/FK 데이터 베이스 성능 향상
- 인덱스의 특징은 여러 개의 속성이 하나의 인덱스로 구성되어 있을 때, 앞쪽에 위치한 속성의 값이 비교자로 있어야 효율성이 좋음
- 앞쪽에 위치한 속성 값이 가급적
=아니면 최소한 범위BETWEEN< >가 들어와야 함=조건이 가장 앞으로,BETWEEN이 그 다음에 오도록 하는 것이 인덱스 액세스 범위를 좁힐 수 있는 팁
- PK순서를 조정하지 않은 경우의 오류 및 성능 저하 사례에 대해 제시함
- 데이터모델에서는 관계를 연결하고 데이터베이스에 FK제약조건 생성을 생략하는 경우에도 데이터의 조인관계가 필요하므로, 학사기준번호에 대한 인덱스를 생성할 필요가 있다.
6. 분산 데이터베이스와 성능
- 분산 데이터베이스
- 여러 곳으로 분산되어있는 데이터베이스를 하나의 가상 시스템으로 사용할 수 있도록 한 데이터베이스
- 논리적으로 동일한 시스템에 속하지만, 컴퓨터 네트워크를 통해 물리적으로 분산되어 있는 데이터들의 모임.
- 분산 데이터베이스가 되기 위한 6가지 투명성
- 위치 투명성 : 사용하려는 데이터의 저장 장소 명시 불필요. 위치정보가 System Catalog에 유지되어야 함
- 중복 투명성 : DB 객체가 여러 site에 중복 되어 있는지 알 필요가 없는 성질
- 병행 투명성 : 다수 Transaction 동시 수행시 결과의 일관성 유지, Time Stamp, 분산 2단계 Locking을 이용 구현
- 분할 투명성(단편화) : 하나의 논리적 Relation이 여러 단편으로 분할되어 각 단편의 사본이 여러 site에 저장
- 장애 투명성 : 구성요소(DBMS, Computer)의 장애에 무관한 Transaction의 원자성 유지
- 지역사상 투명성 : 지역DBMS와 물리적 DB사이의 Mapping 보장. 각 지역시스템 이름과 무관한 이름 사용 가능
- 분산 데이터 베이스의 장단점
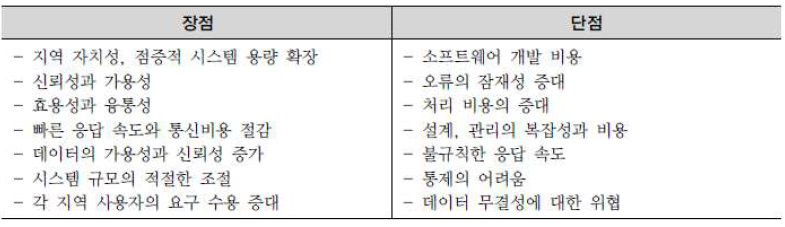
- 빠른 성능을 제공한다는 것이 가장 큰 가치
- 분산 데이터 베이스의 적용 기법
- 테이블 위치 분산
- 설계된 테이블 자체의 위치를 각각 다르게 위치시키는 것
- 위치를 파악할 수 있는 도식화된 위치별 데이터베이스 문서가 필요
- 테이블 분할 분산
- 각각의 테이블을 쪼개어 분산하는 방법
- 수평 분할 : 특정 컬럼 값을 기준으로 로우를 분리, 중복 x, 지사별로 사용 로우가 다를 때
- 수직 분할 : 칼럼을 기준으로 분리, 각 테이블에 동일한 PK가 있어야함
- 테이블 복제 분산
- 동일한 테이블을 다른 지역이나 서버에서 동시에 생성하여 관리하는 유형
- 부분복제(Segment Replication) : 마스터 데이터베이스에서 테이블의 일부의 내용만 다른 지역이나 서버에 위치시킴
- 광역복제(Broadcast Replication) : 마스터 데이터베이스의 테이블의 내용을 각 지역이나 서버에 존재시킴
- 테이블 요약 분산
- 지역간에 또는 서버 간에 데이터가 비슷하지만 서로 다른 유형으로 존재하는 경우
- 분석 요약 : 동일한 테이블 구조를 가지고 있으면서 분산되어 있는 동일한 내용의 데이터를 이용하여 통합된 데이터를 산출하는 방식 ex) 판매실적 : 지사A, 지사B
- 통합 요약 : 분산되어 있는 다른 내용의 데이터를 이용하여 통합된 데이터를 산출하는 방식 ex) 판매실적 : 지사A의 C제품, 지사B의 D제품
- 테이블 위치 분산
- 분산 데이터 베이스 설계를 적용하면 좋은 경우
- 성능이 중요한 사이트
- (테이블 복제 분산) 공통코드, 기준정보, 마스터 데이터 등에 대해 분산환경을 구성하면 성능이 좋아짐
- 실시간 동기화가 요구되지 않는 경우
- 거의 실시간(Near Real Time)의 업무적인 특징을 가지고 있는 경우
- 특정 서버에 부하가 집중이 되는 경우
- 백업 사이트(Disaster Recovery Site)를 구성하는 경우
- Global Single Instance (GSI)는 통합된 한 개의 인스턴스 즉, 통합 데이터베이스 구조를 의미하므로, 분산 데이터베이스와 대치되는 개념임
Reference
https://yurimac.tistory.com/40
https://dewworld27.tistory.com/m/entry/SQL-1차-2차-3차-정규화-개념-및-사례-정리

댓글남기기