
[Handson ML] 배깅(Bagging)과 페이스팅(Pasting) - 앙상블
업데이트:
개요

앞서 포스팅한 투표 기반 분류기에서는 각기 다른 훈련 알고리즘을 조합하여 새로운 분류기를 생성하는 것이였다. 이러한 앙상블 모형을 만드는 다른 방법은 같은 알고리즘을 사용하지만, 훈련 세트의 서브셋을 무작위로 구성하여 분류기를 각기 다르게 학습시키는 방법이 있다.
배강과 페이스팅
훈련세트에서 중복을 허용하여 샘플링하는 방식을 배깅(bagging, bootstrap aggregating), 중복을 허용하지 않고 샘플링하는 방식을 페이스팅(pasting) 이라고 한다. 즉, 배깅은 같은 훈련샘플이 여러 예측기에 사용될 수 있다.
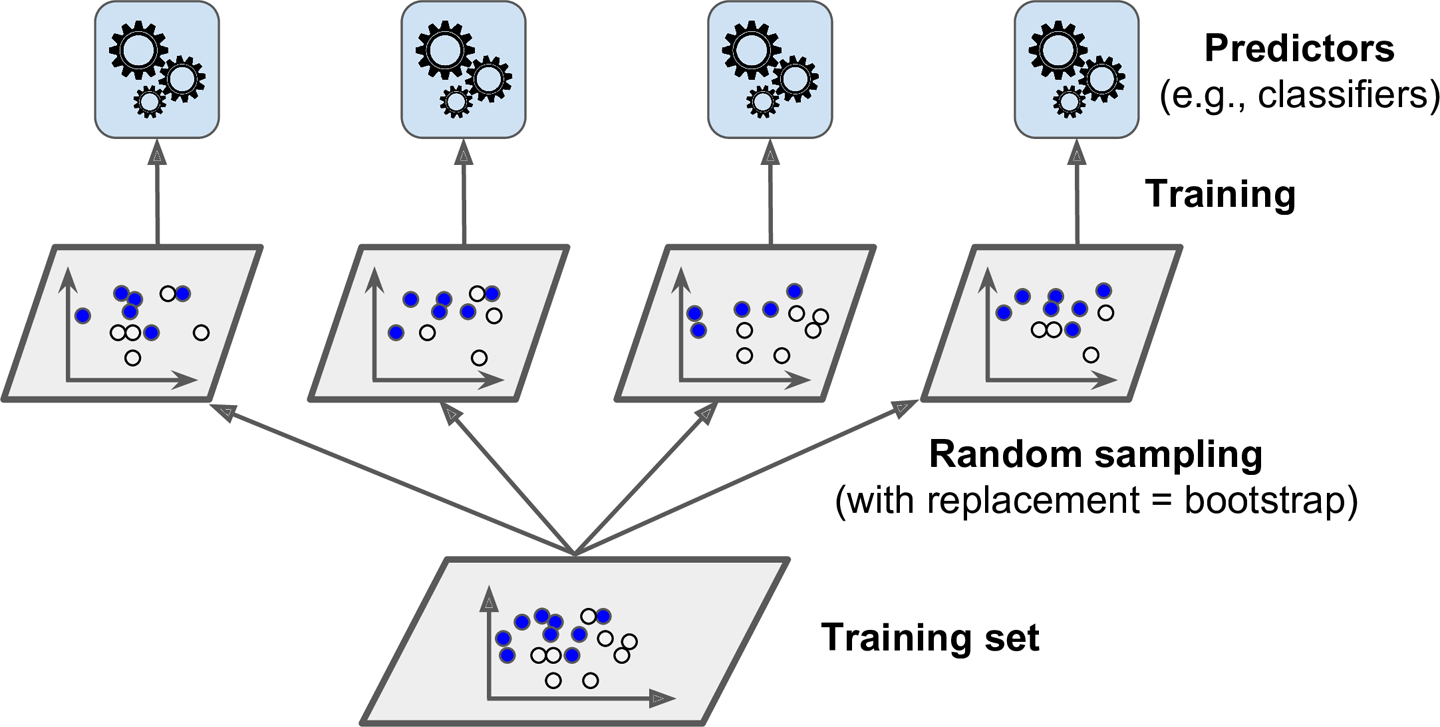
위 그림처럼 모든 예측기들이 훈련을 마치면 앙상블은 예측을 모아 새로움 샘플에 대한 예측을 만든다.
- 분류일때 : 통계적 최빈값(like 직접투표 분류기)
- 회귀일때 : 평균(mean) 계산
개별 예측기들은 원본 훈련 세트(분리되지 않은)로 훈련시킨 것보다 훨씬 편향되어 있지만, 수집함수를 통과하면 편향과 분산이 모두 감소한다.(편향과 분산 관련 내용은 여기를 참고하자)
일반적으로 이러한 앙상블 모형은 원본 데이터셋으로 하나의 예측기를 훈련시킬때보다 편향은 비슷하지만 분산이 감소한다.
사이킷런 모듈
사이킷런은 배깅과 페이스팅을 위해 BaggingClassifier와 BaggingRegressor를 제공한다.
다음 결정트리 분류기 500개의 앙상블 훈련시키는 코드를 보자.
# moon dataset
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=500, noise=0.30, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
bag_clf = BaggingClassifier(DecisionTreeClassifier(),
n_estimators=500,
max_samples=100,
bootstrap=True,
n_jobs=-1)
bag_clf.fit(X_train, y_train)
y_pred = bag_clf.predict(X_test)
print(bag_clf.__class__.__name__,accuracy_score(y_test, y_pred))
# 결정트리 분류기 1개 학습
tree_clf = DecisionTreeClassifier(random_state=42)
tree_clf.fit(X_train, y_train)
y_pred_tree = tree_clf.predict(X_test)
print(tree_clf.__class__.__name__,accuracy_score(y_test, y_pred_tree))
BaggingClassifier 0.912
DecisionTreeClassifier 0.856
분류기에 사용된 매개변수의 의미는 다음과 같다.
n_estimator: 앙상블에 사용할 분류기의 수max_sample: 무작위로 뽑을 샘플의 수(0~1사이의 수로 지정하면 비율이 되어, 훈련세트에 곱한 값만큼 샘플링)boot_strap: True(중복허용, 배깅), False(중복허용 X, 페이스팅)n_jobs: 사용할 CPU 수(-1로 지정하면 가용한 모든코어 사용)
BaggingClassifier는 분류기들이 결정트리처럼 범주에 속할 확률(predict_proba)을 추정할 수 있으면 자동으로 간접 투표 방식을 사용한다.
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
def plot_decision_boundary(clf, X, y, axes=[-1.5, 2.5, -1, 1.5], alpha=0.5, contour=True):
x1s = np.linspace(axes[0], axes[1], 100)
x2s = np.linspace(axes[2], axes[3], 100)
x1, x2 = np.meshgrid(x1s, x2s)
X_new = np.c_[x1.ravel(), x2.ravel()]
y_pred = clf.predict(X_new).reshape(x1.shape)
custom_cmap = ListedColormap(['#fafab0','#9898ff','#a0faa0'])
plt.contourf(x1, x2, y_pred, alpha=0.3, cmap=custom_cmap)
if contour:
custom_cmap2 = ListedColormap(['#7d7d58','#4c4c7f','#507d50'])
plt.contour(x1, x2, y_pred, cmap=custom_cmap2, alpha=0.8)
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "yo", alpha=alpha)
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "bs", alpha=alpha)
plt.axis(axes)
plt.xlabel(r"$x_1$", fontsize=18)
plt.ylabel(r"$x_2$", fontsize=18, rotation=0)
plt.figure(figsize=(11,4))
plt.subplot(121)
plot_decision_boundary(tree_clf, X, y)
plt.title("Decision Tree", fontsize=14)
plt.subplot(122)
plot_decision_boundary(bag_clf, X, y)
plt.title("Decision Trees with Bagging", fontsize=14)
plt.show()
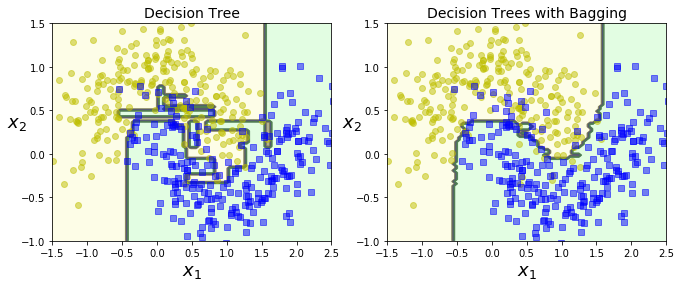
시각적으로 두 분류기(앙상블, 결정트리)의 결정경계를 비교해보니 앙상블의 예측이 더 일반화가 잘 이루어짐을 알 수 있다.
부트스트래핑(중복을 허용한 샘플링)은 각 예측기가 학습하는 서브셋에 다양성을 증가시키므로 배깅이 페이스팅보다 편향이 조금더 높다.
하지만 이는 예측기간의 상관관계를 줄여 앙상블의 분산을 감소시킨다.
일반적으로 배깅이 더 나은 모델을 만들지만, 여유가 된다면 교차검증을 이용해서 배깅과 페이스팅을 모두 평가해보는 것이 좋다.
oob평가
배깅을 사용하면 어떤 샘플은 여러번 샘플링되고, 어떤 것은 전혀 사용되지 않을 수도 있다.
BaggingClassifier는 중복을 허용하여 훈련 세트의 크기 만큼 m개의 샘플을 선택하는데, 이는 평균적으로 각 예측기에 훈렴샘플의 63% 정도만 샘플링 된다는 것을 의미한다(관련 내용은 여기를 참고).
여기서 선택되지 않은 훈련 샘플의 나머지 37% 정도를 oob(out-of-bag)샘플이라고 부른다.
핵심은 예측기가 훈련되는 동안 이 oob샘플을 사용하지 않으므로 검증 세트나 교차검증을 사용하지 않고 이를 이용해 평가할 수 있다.
앙상블의 평가는 각 예측기의 oob평가를 평균하여 얻는다.
사이킷런에서 BaggingClassifier의 oob_score=True로 지정하면 훈련을 마치고 oob평가를 수행한다.
bag_clf = BaggingClassifier(DecisionTreeClassifier(),
n_estimators=500,
bootstrap=True,
n_jobs=-1,
oob_score=True)
bag_clf.fit(X_train, y_train)
bag_clf.oob_score_ # 500개 결정트리 분류기의 oob점수를 평균한 값
0.9013333333333333
약 90%의 정확도를 보여준다.
이는 테스트 데이터셋을 사용하지 않고 훈련데이터에서 사용되지 않은 것을 재활용(?)한 것으로, 실제 테스트 데이터셋과 비교해보자.
from sklearn.metrics import accuracy_score
y_pred = bag_clf.predict(X_test)
accuracy_score(y_test, y_pred)
0.904
실제로 비슷한 정확도를 보여준다.
oob평가를 통해 얻은 결정 함수의 값(범주에 속할 확률)은 oob_decision_function_에서 확인할 수 있다(예측기가 predict_proba()메서드를 가지므로).
# 총 375(훈련 데이터셋 크기)개 중 10개만
bag_clf.oob_decision_function_[:10]
array([[0.359375 , 0.640625 ],
[0.32941176, 0.67058824],
[1. , 0. ],
[0. , 1. ],
[0. , 1. ],
[0.08994709, 0.91005291],
[0.35384615, 0.64615385],
[0.02162162, 0.97837838],
[0.98823529, 0.01176471],
[0.97354497, 0.02645503]])
첫 번째 훈련 샘플이 양성 범주에 속할 확률을 64.06%, 음성 범주에 속할 확률을 35.93%로 추정하고 있다.
랜덤 패치와 랜덤 서브스페이스
BaggingClassifier는 변수 샘플링도 지원한다. max_feature과 bootstrap_features로 조절이 가능한데, 작동방식은 max_samples와 bootstrap과 동일하다(샘플과 변수의 차이).
이는 이미지와 같은 고차원의 데이터셋을 다룰 때 유용하다.
- 랜덤 패치 방식(Random Patches method) : 훈련 변수와 샘플을 모두 샘플링
- 랜덤 서브스페이스 방식(Random Subspaces method) : 훈련 샘플을 모두 사용하고(
bootstrap=False,max_samples=1) 변수는 샘플링(bootstrap_features=True,max_features=0~1값)
변수 샘플링은 더 다양한 예측기를 만들며 편향을 늘리는 대신 분산을 낮춘다.
Reference
도서 [Hands-0n Machine Learning with Scikit-Learn & Tensorflow] 를 공부하며 작성하였습니다.

댓글남기기