
[Handson ML] 경사하강법(Gradient Descent) - 모델 훈련
업데이트:
개요

이번 포스팅에서는 경사하강법의 기본개념과 구현하는 여러가지 방법중 배치, 확률적, 미니배치에 대해 알아보자.
경사하강법(GradiD)
경사하강법(Gradient Descent)은 쉽게말해, 비용함수(cost function)를 최소화 하기위해 경사를 반복적으로 하강해가면서 파라미터를 조정해 나가는 것이다.
파라미터 벡터 세타에 대해 비용함수의 현재 gradient를 계산하고, 이를 감소하는 방향으로 0이 될때까지 하강한다. 이는 미분값(기울기)이 0이 되는 지점일 것이다.
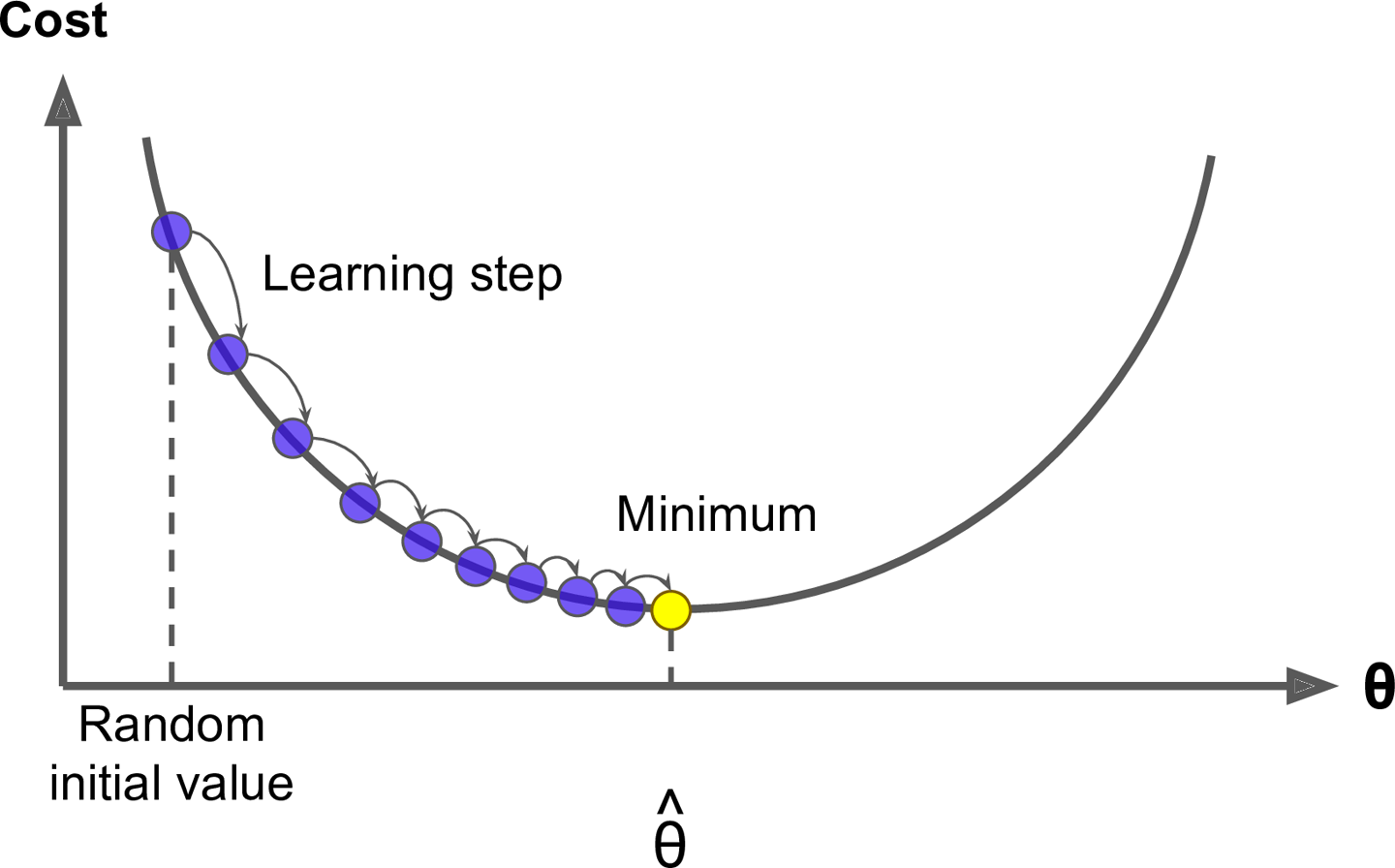
경사하강법에서 가장 중요한 파라미터는 학습률(learning rate) 하이퍼 파라미터로, 하강하는 보폭(step)을 의미한다.
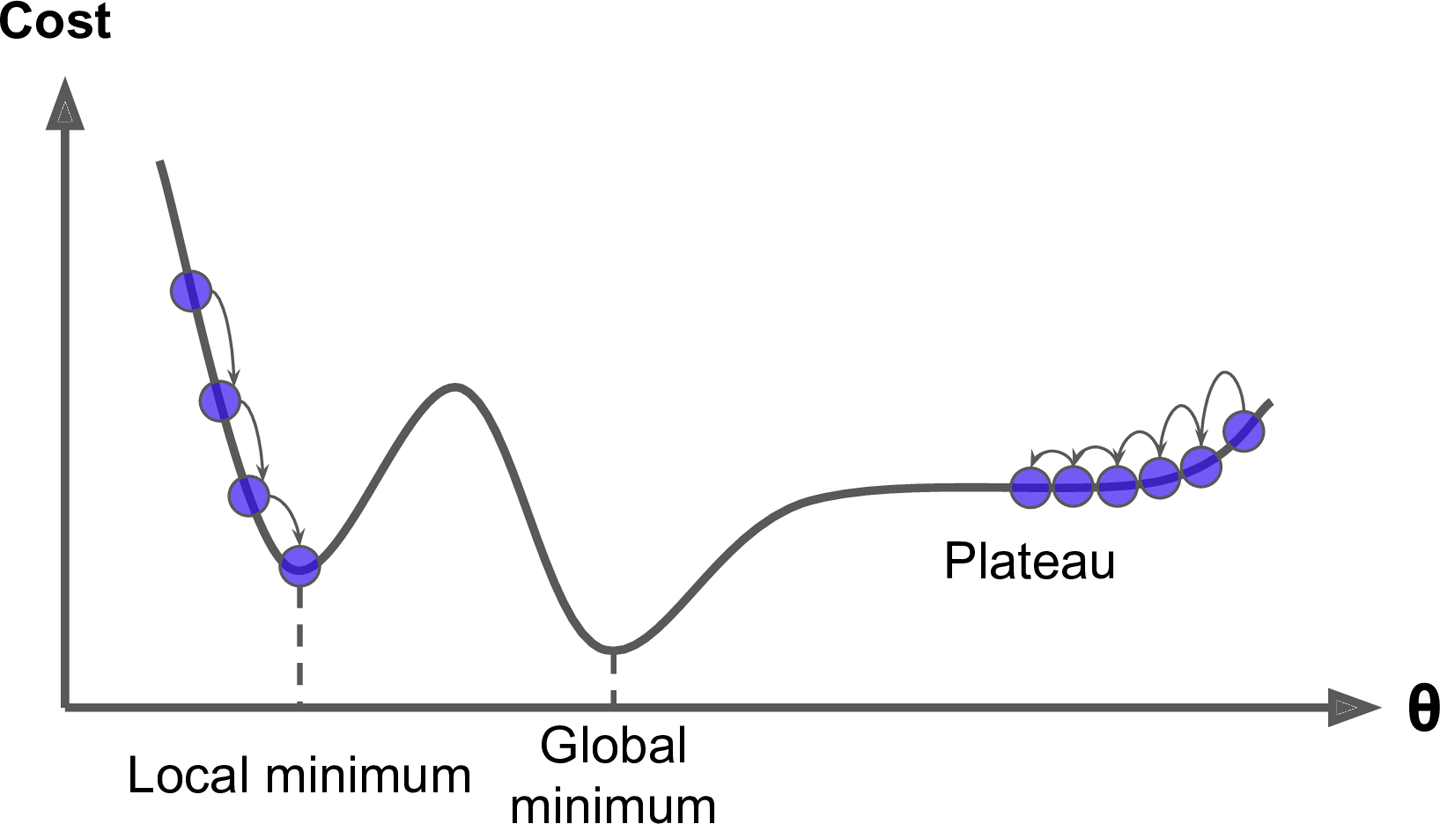
이 learning rate가 너무 작으면, 시간이 오래 걸리고 굴곡이 있는 비용함수(변곡점이 많은)의 경우 min값을 찾지 못할 수도 있다.
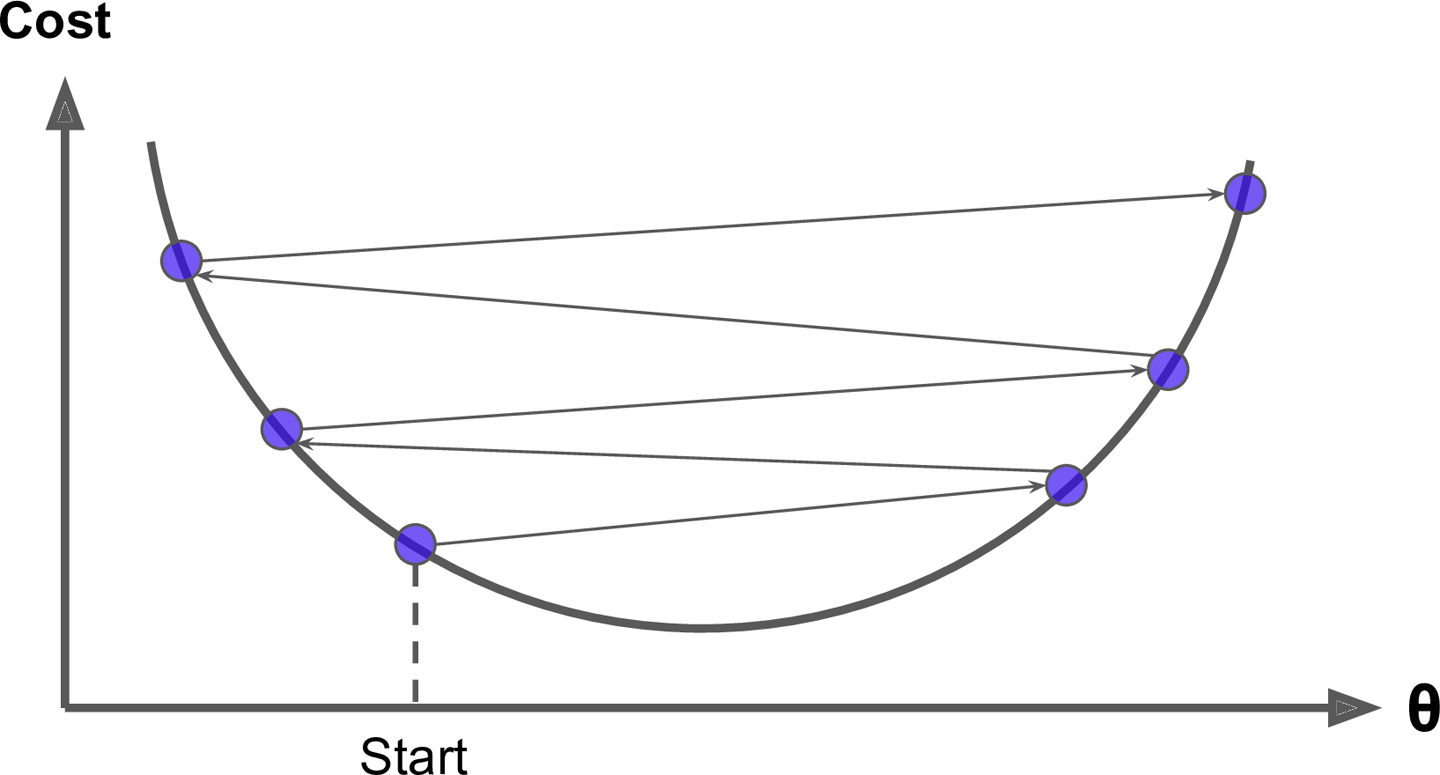
반대로 너무 크게 설정하면, 최솟값을 가로질러 반대 경사로 뛰어넘는 경우가 발생할 수 있다.
또한 알고리즘이 경사의 왼쪽,오른쪽에서 시작하는 경우에도 결과가 다르게 도출될 수 있는 문제점들이 있다.
하지만 선형회귀를 위한 MSE 비용함수는 볼록함수(convex function)형태여서 하나의 전역최솟값이 존재하고, 연속된 함수이며 기울기가 갑자기 변하지 않기 때문에 경사하강법으로 전역최솟값에 접근할 수 있다.
또한 변수들의 스케일이 매우 다를 경우에도 문제가 생긴다.
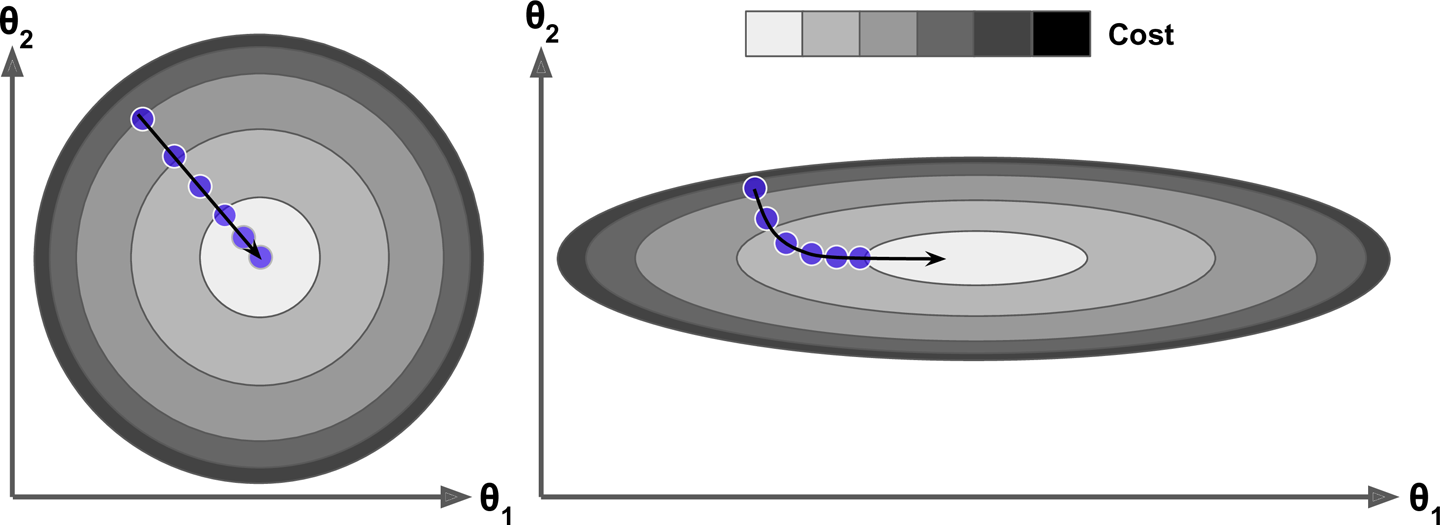
오른쪽 그림은 변수1이 변수2보다 스케일이 작은 훈련데이터인 경우이다.
변수1의 스케일이 훨씬 작기 때문에 비용함수를 변화시키기 위해서는 세타1이 더 크게 바뀌어야 하므로, 좌우로 긴 형태가 된다. 이렇게 되면 최솟값에 도달은 하겠지만 매우 시간이 오래걸리게 된다.
따라서 경사하강법을 이용할때는 반드시 모든 변수들이 같은 스케일을 갖도록 스케일링을 해주어야 한다.
이를 위해 사이킷런의 StandardScaler을 통해 표준화를 할 수 있다.
위 그림은 2차원(변수가 2개)이지만, 파라미터가 많아질수록(변수가 많아질수록) 최적 조합을 찾는게 어려워진다.
선형 회귀의 경우는 쉽게 함수의 맨 바닥에 있겠지만.
1. 배치 경사하강법
경사하강법을 구현하려면 θj가 변함에 따라 비용함수가 변하는 정도를 계산해야 하는데, 이를 편도함수(partial derivative)라고 한다.
즉, 비용함수를 미분해서 미분값(기울기)의 변화를 관찰한다는 것이다.
식은 다음과 같다.
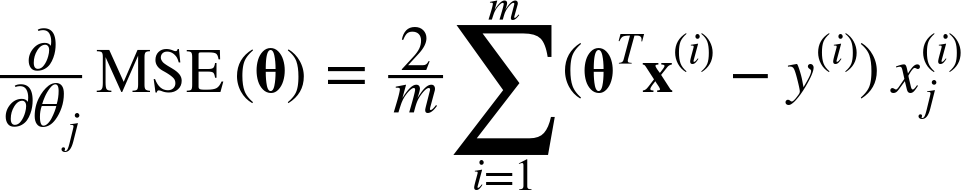
비용함수 MSE(θ)를 θj에 관해 편미분 한 것이다.
모델 파라미터 θ가 많아질 경우 이를 다음과 같이 벡터화를 통해 일괄 계산할 수 있다.
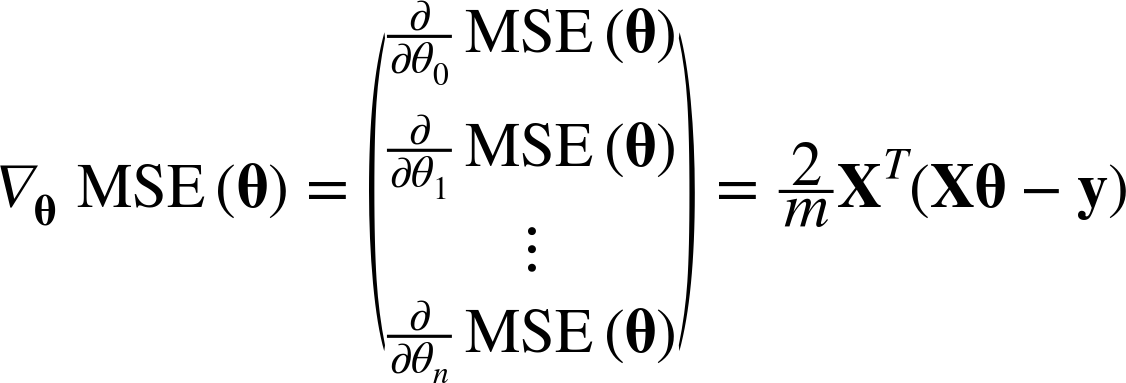
이는 각 모델 파라미터 θ마다의 편도함수를 모두 담고 있다.
따라서 이 알고리즘을 Batch(일괄) Gradient Descent, 배치 경사하강법이라고 한다.
이제 이 gradient vector가 구해지면 다음 step으로 가기 위한 θ를 구해야 하는데, 여기서 학습률(learning rate)이 사용된다.
수식은 다음과 같다.
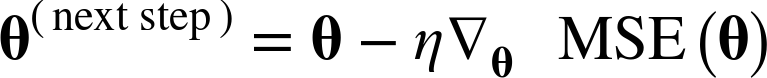
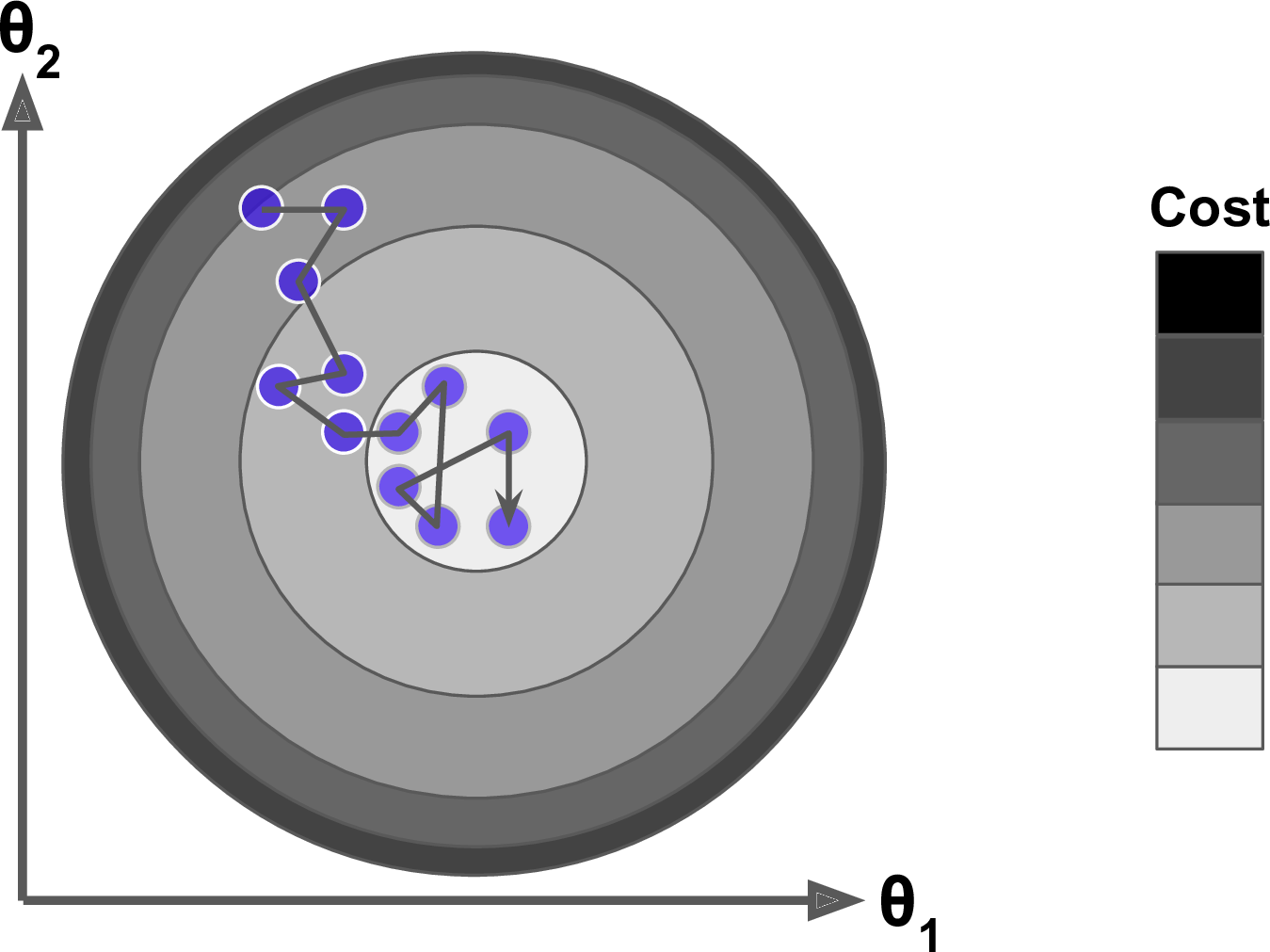
이 개념이 처음에 좀 헷갈려서 헤맸었는데, 어떤 블로그에 좋은 그림이 있어서 첨부한다.
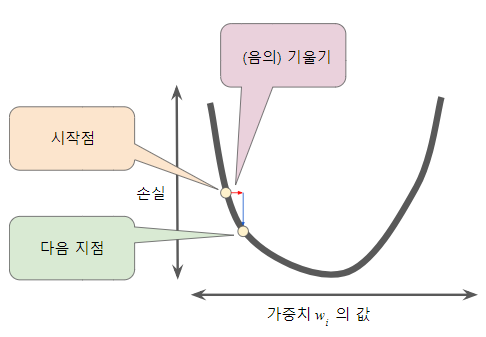
다음 θ에서 학습률을 곱한 gradient vector를 빼는 이유는,
스텝이 전역 최솟값의 좌측에서 시작한 경우 기울기는 음(-)의 값을 가지므로 -와 만나 +가 되어 θ값을 키워 우측으로 이동해야 하기 때문이다.
그 반대의 경우도 마찬가지다.
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
X = 2*np.random.rand(100,1)
y = 4 + 3 * X + np.random.randn(100,1)
X_b = np.c_[np.ones((100,1)), X] # 절편항을 위해 1열에 1값 추가
learning_rate = 0.1 # 학습률 설정
n_iter = 1000 # 반복 횟수 설정
m = 100 # 샘플 수
theta = np.random.randn(2,1) # 무작위 초기값 설정
for iter in range(n_iter):
gradients = 2/m * X_b.T.dot(X_b.dot(theta) - y) # 배치 경사하강법
theta = theta - learning_rate*gradients # next step
theta
array([[4.21509616],
[2.77011339]])
X_new = np.array([[0],[2]])
X_new_b = np.c_[np.ones((2,1)),X_new]
X_new_b.dot(theta)
array([[4.21509616],
[9.75532293]])
선형회귀 포스팅에서 정규방정식으로 구했던 값과 같음을 알 수 있다.
학습률을 변형시키면 어떨까?
theta_path_bgd = []
def plot_gradient_descent(theta, eta, theta_path=None):
m = len(X_b)
plt.plot(X, y, "b.")
n_iterations = 1000
for iteration in range(n_iterations):
if iteration < 10:
y_predict = X_new_b.dot(theta)
style = "b-" if iteration > 0 else "r--"
plt.plot(X_new, y_predict, style)
gradients = 2/m * X_b.T.dot(X_b.dot(theta) - y)
theta = theta - eta * gradients
if theta_path is not None:
theta_path.append(theta)
plt.xlabel("$x_1$", fontsize=18)
plt.axis([0, 2, 0, 15])
plt.title(r"$\eta = {}$".format(eta), fontsize=16)
np.random.seed(42)
theta = np.random.randn(2,1) # 무작위 초기값 설정
plt.figure(figsize=(10,4))
plt.subplot(131); plot_gradient_descent(theta, eta=0.02)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.subplot(132); plot_gradient_descent(theta, eta=0.1, theta_path=theta_path_bgd)
plt.subplot(133); plot_gradient_descent(theta, eta=0.5)
plt.show()
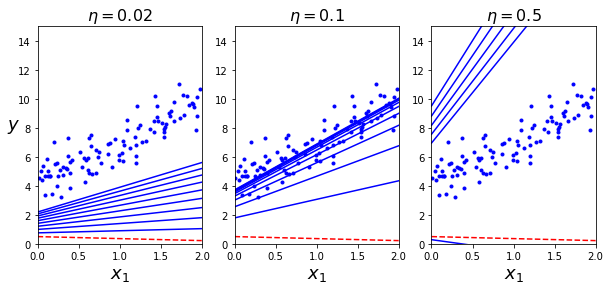
위 그래프에서 빨간 점선은 시작점을 나타내며, 학습 스텝의 첫 10개만 시각화 했다.
앞에서도 설명한 것 처럼, learning rate이 너무 낮으면 시간이 오래걸리고, 너무 높으면 최적점을 넘어가 버린 것을 확인 할 수 있다.
이렇게 적절한 learning rate를 찾기 위한 방법으로 그리드 탐색을 사용할 수 있다.
또한 적절한 반복횟수를 찾기 위해서는, 우선 반복 횟수를 크게 지정하고 gradient vector가 매우 작아지면, 알고리즘을 중지하게 하는 방법을 채택하면 된다.
2. 확률적 경사하강법
확률적 경사하강법(SGD, Stochastic Gradient Descent)은 매 스텝(step)에서 딱 1개의 샘플을 무작위로 선택하고 그에 대한 gradient를 계산한다.
매 반복에서 적은 데이터를 처리하므로 속도가 매우 빠르며, 1개 샘플에 대한 메모리만 필요하므로 매우 큰 훈련 데이터 셋도 가능하다.
반대로 앞에서 배운 배치경사하강법은 매 스텝마다 전체 훈련 데이터를 반복해서 사용해 gradient를 계산하므로 느리다.
하지만, 확률적이기 때문에 훨씬 불안정하고, 매끄러운 하강이 아닌 요동치는 것을 볼 수 있을 것이다.
이렇게 요동치는 것은 역설적으로 지역 최솟값을 뛰어넘어 전역 최솟값을 찾게 도와줄 수 있어, 이 가능성이 배치에 비해 높다.
이러한 이슈들을 위해서는 learning rate을 크게 설정하고(지역 최솟값을 뛰어넘고 수렴하도록), 점차 작게 줄여서 전역 최솟값에 도달하게 하는 것이 좋다.
이러한 조절 과정들을 학습 스케줄(learning schedule)이라고 하며, 간단하게 구현해보자.
theta_path_sgd = []
m = len(X_b)
np.random.seed(42)
n_epochs = 50
t0, t1 = 5, 50 # learning schedule hyperparameters
def learning_schedule(t):
return t0 / (t + t1)
theta = np.random.randn(2,1) # 무작위 초기값
for epoch in range(n_epochs):
for i in range(m):
if epoch == 0 and i < 20:
y_predict = X_new_b.dot(theta)
style = "b-" if i > 0 else "r--"
plt.plot(X_new, y_predict, style)
random_index = np.random.randint(m)
xi = X_b[random_index:random_index+1]
yi = y[random_index:random_index+1]
gradients = 2 * xi.T.dot(xi.dot(theta) - yi)
learning_rate = learning_schedule(epoch * m + i)
theta = theta - learning_rate * gradients
theta_path_sgd.append(theta)
plt.plot(X, y, "b.")
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.axis([0, 2, 0, 15])
plt.show()
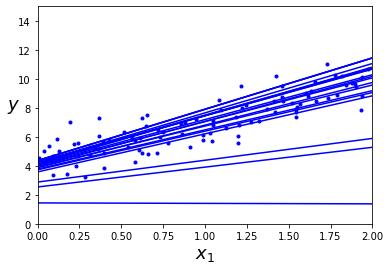
theta
array([[4.18545376],
[2.77900595]])
1개의 샘플로 m(샘플 수)번 반복되고, 이때의 각 반복을 epoch라고 한다. 이 epoch로 학습률을 변경해가면서(스케줄링) 훈련한 것이다.
배치 경사하강법에서 전체 훈련세트를 1000번 반복하는 동안, 이 SGD는 1개의 샘플로 50번만 반복하고도 매우 좋은 값에 도달했다.
샘플을 무작위로 선택하므로 어떤 샘플은 한 epoch에서(m번 반복동안) 여러번 선택 될 수도 있고 아에 안쓰일 수도 있다.
한 epoch마다 다른 샘플을 사용하려면 차례로 하나씩 선택하고, 다시 섞고 하는 방식을 사용할 수 있다.
(이는 사이킷런의 SGDRegressor와 SGDClassifier가 사용하는 방법이다.)
사이킷런에서 SGD방식으로 선형회귀를 사용하려면 default로 MSE(cost function)를 최소화 하는 SGDRegressor를 사용한다.
다음 코드를 보자.
from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(max_iter=1000, tol=1e-3, penalty=None, eta0=0.1, random_state=42)
sgd_reg.fit(X, y.ravel())
SGDRegressor(alpha=0.0001, average=False, early_stopping=False, epsilon=0.1,
eta0=0.1, fit_intercept=True, l1_ratio=0.15,
learning_rate='invscaling', loss='squared_loss', max_iter=1000,
n_iter_no_change=5, penalty=None, power_t=0.25, random_state=42,
shuffle=True, tol=0.001, validation_fraction=0.1, verbose=0,
warm_start=False)
(SGDRegressor의 기본 학습스케쥴은 앞의 수동방식과 다르다.)
sgd_reg.intercept_, sgd_reg.coef_
(array([4.24365286]), array([2.8250878]))
여기에서도 정규방정식의 값과 비슷한 값을 얻었다.
3. 미니배치 경사하강법
미니배치 경사하강법(Mini-batch Gradient Descent)은 각 스텝에서 전체 훈련세트(like batch)나 하나의 샘플(like SGD)을 기반으로 하지 않고, 미니 배치라고 부르는 임의의 작은 샘플 집합에 대해 계산한다.
주요 장점은 GPU를 사용해 얻는 성능 향상이라고 할 수 있다.
특히, 미니배치를 어느 정도 크게 하면 파라미터 공간에서 SGD보다 덜 불규칙적으로 움직인다.
결국 미니배치 경사하강법이 SGD보다 최솟값에 더 가까이 도달할 수 있지만 동시에 지역 최솟값에서 빠져나오기는 조금 더 힘들수도 있다(convex가 아닌경우).
앞의 세가지 알고리즘이 훈련 과정동안 파라미터 공간에서 움직인 경로를 구현해보자.
theta_path_mgd = []
n_iterations = 50
minibatch_size = 20
np.random.seed(42)
theta = np.random.randn(2,1) # random initialization
t0, t1 = 200, 1000
def learning_schedule(t):
return t0 / (t + t1)
t = 0
for epoch in range(n_iterations):
shuffled_indices = np.random.permutation(m)
X_b_shuffled = X_b[shuffled_indices]
y_shuffled = y[shuffled_indices]
for i in range(0, m, minibatch_size):
t += 1
xi = X_b_shuffled[i:i+minibatch_size]
yi = y_shuffled[i:i+minibatch_size]
gradients = 2/minibatch_size * xi.T.dot(xi.dot(theta) - yi)
eta = learning_schedule(t)
theta = theta - eta * gradients
theta_path_mgd.append(theta)
theta
array([[4.25214635],
[2.7896408 ]])
theta_path_bgd = np.array(theta_path_bgd)
theta_path_sgd = np.array(theta_path_sgd)
theta_path_mgd = np.array(theta_path_mgd)
plt.figure(figsize=(7,4))
plt.plot(theta_path_sgd[:, 0], theta_path_sgd[:, 1], "r-s", linewidth=1, label="Stochastic")
plt.plot(theta_path_mgd[:, 0], theta_path_mgd[:, 1], "g-+", linewidth=2, label="Mini-batch")
plt.plot(theta_path_bgd[:, 0], theta_path_bgd[:, 1], "b-o", linewidth=3, label="Batch")
plt.legend(loc="upper left", fontsize=16)
plt.xlabel(r"$\theta_0$", fontsize=20)
plt.ylabel(r"$\theta_1$ ", fontsize=20, rotation=0)
plt.axis([2.5, 4.5, 2.3, 3.9])
plt.show()
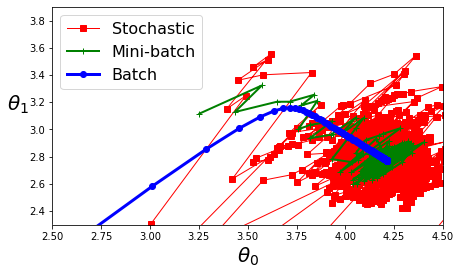
배치 경사하강법은 최솟값에서 멈춘 반면, SGD와 미니배치 경사하강법은 맴돌고 있음을 볼 수 있다.
하지만, 앞에서 언급한 바와 같이 적절한 학습 스케줄(learning schedule)을 사용하면 최솟값 도달이 가능하다는 점을 잊지말자.
마지막으로 지금까지 논의한 알고리즘을 선형회귀를 사용해 비교해보자(m:샘플 수, n:변수 수)
| 항목 | normal | Batch | SGD | Mini- batch |
|---|---|---|---|---|
| m이 클때 | 빠름 | 느림 | 빠름 | 빠름 |
| n이 클때 | 느림 | 빠름 | 빠름 | 빠름 |
| 외부 학습메모리 지원 | X | X | O | O |
| 하이퍼파라미터 수 | 0 | 2 | >=2 | >=2 |
| 스케일 조정 필요 | X | O | O | O |
| 사이킷런 | LinearRegression | SGDRegressor | SGDRegressor | SGDRegressor |
미니배치는 사이킷런의 SGDRegressor SGRClassifier에서 partial_fit메서드를 이용해 모델 파라미터를 초기화하지 않고, 미니배치 학습을 위해 반복적으로 호출할 수 있다.
Reference
도서 [Hands-0n Machine Learning with Scikit-Learn & Tensorflow] 를 공부하며 작성하였습니다.
하지만 partial_fit으로 샘플을 뽑고 그 샘플을 하나씩 매치(SGD)하므로 엄밀히 말하면 미니배치는 아니다.

댓글남기기