
[Algorithm] 정렬 알고리즘 (선택 정렬, 삽입 정렬, 퀵 정렬, 계수 정렬)
업데이트:
개요
![]()
이번 포스팅은 데이터를 특정한 기준에 따라 나열하는 정렬(Sorting) 알고리즘에 대해 알아보자. 예를 들어, 0,5,1,2,8,4,7이라는 배열을 오름차순 정렬을 하려고 할 때 사람은 그냥 작은 수부터 직관적으로 나열할 수 있다. 그러나 컴퓨터는 어떤게 작은 숫자인지, 또 어떤 방식으로 정렬할지 등을 알려줘야하며 시간 복잡도도 계속 달라지므로 다양한 방식이 생겨나게 된다.
이번에 공부할 알고리즘 유형은 선택 정렬(Selection sort), 삽입 정렬(Insertion sort), 퀵 정렬(Quick sort), 계수 정렬(Count sort)이다.
선택 정렬
선택정렬은 원시적인 방법으로 계속 가장 작은 수를 찾아서 앞으로 빼자는 아이디어에서 생겨났다.
아래와 같은 숫자 배열을 예시로 각 단계별로 이해해보자
7 5 9 0 3 1 6 2 4 8
- Step 0: 가장 작은 수(0)를 찾아 맨앞의 7과 바꾼다.
05 9 7 3 1 6 2 4 8
- Step 1: 그 다음 가장 작은 수(1)를 찾아 맨 앞의 5와 바꾼다.
019 7 3 5 6 2 4 8
- Step 2: 그 다음 가장 작은 수(2)를 찾아 맨 앞의 9와 바꾼다.
0127 3 5 6 9 4 8
- ..반복
0123456789
구현 코드
array = [7,5,9,0,3,1,6,2,4,8]
for i in range(len(array)):
# i: 가장 작은 원소를 넣을 인덱스 (맨 앞)
min_index = i
for j in range(i+1, len(array)):
# j: i 다음 인덱스들을 순회하면서 가장 작은 min_index를 도출
if array[min_index] > array[j]:
min_index=j # 바꿀 인덱스
# 맨 앞(i)과 가장 작은 수(min_index) 스와핑
array[i],array[min_index] = array[min_index],array[i]
print(array)
시간 복잡도
선택 정렬의 시간 복잡도는 $O(N^2)$ 이다.
선택 정렬에는 총 두번의 연산이 필요하다.
- $N-1$ 만큼의 가장 작은 수를 찾아서 맨 앞으로 보내는 연산
- 매번 가장 작은 수를 찾기 위한 비교연산
따라서 $N+(N-1)+(N-2)+…+2 = N(N+1)/2$ 정도의 연산 횟수가 필요하므로 간단한 빅오표기법으로 $O(N^2)$가 된다.
삽입 정렬
삽입 정렬은 하나씩 적절한 위치에 삽입하자는 아이디어이다. 이는 항상 모든 원소를 비교하여 가장 작은수를 찾고 위치를 바꾸는 선택 정렬과 달리, 앞쪽의 적절한 위치에 끼워 넣는 방식이다.
따라서 앞 쪽의 숫자들에 대해서만 비교연산을 하면 될 것이며, 이미 정렬이 되어 있을 수록 훨씬 효율적인 특징이 있다.
같은 배열의 예시를 보자.
7 5 9 0 3 1 6 2 4 8
삽입을 해야하기 때문에 맨 앞의 7은 그 자체로 정렬되어 있다고 보고 다음 숫자인 5부터 시작한다.
- Step 0: 다음 숫자(5)를 앞쪽 숫자들(7)과 비교하여 오름차순 삽입
579 0 3 1 6 2 4 8
- Step 1: 다음 숫자(9)를 앞쪽 숫자들(5,7)과 비교하여 오름차순 삽입
5790 3 1 6 2 4 8
- Step 2: 다음 숫자(0)를 앞쪽 숫자들(5,7,9)과 비교하여 오름차순 삽입
05793 1 6 2 4 8
- Step 1: 다음 숫자(3)를 앞쪽 숫자들(0,5,7,9)과 비교하여 오름차순 삽입
035791 6 2 4 8
- …반복…
즉, 앞쪽의 숫자들은 항상 오름차순을 유지한다.
구현 코드
구현이 조금 어려운데, 삽입한다는 느낌보다는 현재 데이터를 앞쪽과 비교해서 연쇄적으로 바꿔나가다가 자기보다 작은 데이터를 만나면 종료하는 식으로 구현된다.
array = [7,5,9,0,3,1,6,2,4,8]
# 삽입할 숫자 loop
for i in range(1, len(array)):
# 삽입될 앞쪽 배열 loop (i부터 1까지 -1씩 감소)
for j in range(i, 0, -1):
# 자기보다 큰 데이터를 만나면 스와핑
if array[j] < array[j-1]:
array[j], array[j-1] = array[j-1], array[j]
# 자기보다 작은 데이터를 만나면 그 위치에서 종료
else:
break
print(array)
시간 복잡도
삽입정렬도 마찬가지로 시간 복잡도는 $O(N^2)$ 이다. 그러나 데이터가 거의 정렬되어 있을 경우 최대 $O(N)$까지 개선될 수 있다.
퀵 정렬
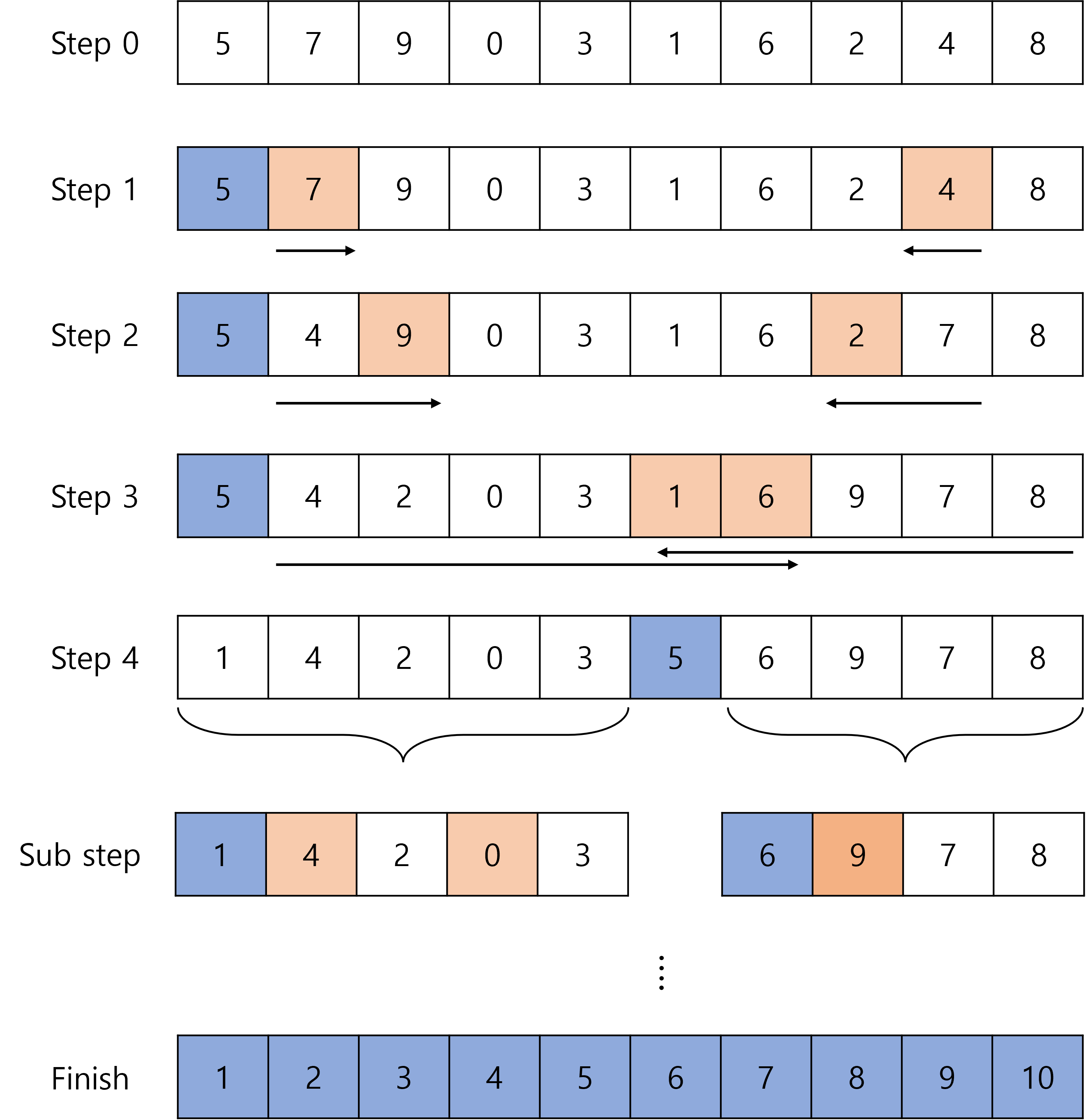
가장 많이 사용되는 알고리즘으로, 기준 데이터를 설정하고 그 기준보다 큰 데이터와 작은데이터를 맞교환하는 방식으로 이루어진다.
구체적인 동작 순서는 아래와 같다.
- 가장 왼쪽의 데이터를 기준 데이터(Pivot)로 설정
- 좌측(기준보다 큰 값)과 우측(기준보다 작은 값)을 동시에 탐색하면서 데이터를 찾고 두 데이터를 맞교환
- 찾은 데이터(좌측, 우측)들이 서로 엇갈리게 될 때, 작은데이터와 기준데이터를 맞교환
- 피벗을 기준으로 나눠진 부분 배열(Sub part)에 대하여, 1~3을 반복한다.
구현 코드
위 설명처럼 4번에서 다시 부분 배열에 대해 동일한 동작을 반복하므로, 재귀함수 형태로 간단하게 구현할 수 있다.
위에서 설명한 동작방식대로 직관적으로 구현한 코드이다.
array = [5,7,9,0,3,1,6,2,4,8]
def quick_sort(array, start, end):
# 종료조건 : 부분 배열의 원소가 1개일때
if start >= end:
return
pivot = start
left = start+1
right = end
while left <= right:
# left : pivot보다 큰 데이터를 찾을떄 까지
while left <= end and array[left] <= array[pivot]:
left+=1
# right : pivot보다 작은 데이터를 찾을떄 까지
while right > start and array[right] >= array[pivot]:
right-=1
# 엇갈린 경우 : 피벗과 작은 데이터(right)를 바꾼다.
if left > right:
array[right], array[pivot] = array[pivot], array[right]
# 엇갈리지 않은 경우 : 작은 데이터(right)와 큰 데이터(left)를 교체
else:
array[left], array[right] = array[right], array[left]
quick_sort(array, start, right-1) # 왼쪽 부분 배열 재수행
quick_sort(array, right+1, end) # 우측 부분 배열 재수행
quick_sort(array, 0, len(array)-1)
print(array)
아래는 파이썬으로 더 빠르게 퀵정렬을 구현하는 방법이다. 위 설명 방식처럼 하나씩 바꾸기보다는, 필터링을 통해 한번에 좌측 부분 배열과 우측 부분배열을 나눠버리는 방식이다.
결국 하나씩 바꾸지 않고, 기준 데이터보다 큰 배열과 작은배열을 나누는것만 반복하고 원소 개수가 1이될때까지만 반복해주면 동일한 결과가 된다.
array = [5,7,9,0,3,1,6,2,4,8]
def quick_sort(array):
# 원소가 하나 남을때 종료
if len(array) <= 1:
return array
pivot=array[0] # 기준데이터: 첫번째 원소
tail=array[1:] # 탐색데이터: 나머지 원소들
left_side = [x for x in tail if x <= pivot]
right_side = [x for x in tail if x > pivot]
return quick_sort(left_side)+[pivot]+quick_sort(right_side)
print(quick_sort(array))
시간 복잡도
퀵정렬의 평균적인 시간복잡도는 $O(NlogN)$ 이다. 즉, 선택과 삽입정렬 대비 데이터의 개수가 많아질수록 차이가 극명하다.
계수 정렬
계수 정렬은 정렬이라기 보다는 원소의 최대값에 해당하는 만큼 리스트를 만들어 놓고 각 원소에 대응되는 인덱스를 카운트하는 방식이다.
따라서 최대값이 크지 않을 때 매우빠르게 동작하지만, 한 원소의 값이 터무니 없이크면 그만큼 리스트를 만들어야해서 비효율적이여 진다. 즉, 앞의 선택,삽입,퀵 정렬과 같이 비교기반이 아니다.
이 알고리즘의 사용을 고려해 볼 조건은 두가지 정도이다.
- 최대값이 작은 경우
- 모든 데이터가 양의 정수인 경우
구현 코드
array = [7,5,9,0,3,1,6,2,9,1,4,8,0,5,2]
count = [0]*(max(array)+1)
for i in range(len(array)):
count[array[i]]+=1
for i in range(len(count)):
for j in range(count[i]):
print(i, end=' ')
시간 복잡도
데이터 개수(N)만큼 인덱스를 잡아줘야하고, 리스트의 크기는 원소의 최대값(K)이 되므로 시간복잡도는 $O(N+K)$ 이다.
파이썬 정렬 함수
기존에 포스팅했던 sorted나 sort외에도 key값을 이용하여 리스트를 정렬하는 함수가 있다.
위와 같이 문자열과 숫자값을 가진 튜플을 원소로가진 리스트가 있을 때, 숫자값을 기준으로 리스트를 정렬하는 방식이다.
sorted함수의 key인자에 데이터를 정렬할 함수를 입력한다. 여기에는 데이터의 1번쨰 원소를 지정하는 setting함수를 직접 만들어 사용할 수도 있고 lambda를 이용할 수도 있다.
array = [('바나나',2),('사과',5),('당근',3)]
def setting(data):
return data[1]
result = sorted(array, key=setting)
print(result)
result = sorted(array, key=lambda data: data[1])
print(result)
[('바나나',2),('당근',3),('사과',5)]
[('바나나',2),('당근',3),('사과',5)]
Reference
이것이 취업을 위한 코딩 테스트다 with 파이썬 - 나동빈

댓글남기기