
[Web] Selenium으로 네이버 페이지 다루기
업데이트:
Selenium이란?
Selenium은 webdriver라는 API를 통해 운영체제에 설치된 Chrome등의 브라우저를 제어하는데 활용되는 파이썬 라이브러리이다.
이 라이브러리를 이용하면 코드가 실행되는 동안 실제로 웹브라우저가 동작하기 때문에, 웹 브라우저에 나타나는 컨텐츠라면 모두 수집이 가능하다.
설치는 간단하다.
$ conda install selenium
$ pip install selenium
앞에서 설명했던 webdriver는 브라우저를 제어할 수 있도록 하는데, 여기서는 Chrome을 중심으로 설명한다.
설치 방식은 여기를 참고.
1. Selenium으로 사이트 브라우징
1-1. webdriver
wedriver라는 모듈을 불러와보자.
type(driver)
selenium.webdriver.chrome.webdriver.WebDriver
from selenium import webdriver
print(dir(webdriver), end = ' ')
['ActionChains', 'Android', 'BlackBerry', 'Chrome', 'ChromeOptions', 'DesiredCapabilities', 'Edge', 'Firefox', 'FirefoxOptions', 'FirefoxProfile', 'Ie', 'IeOptions', 'Opera', 'PhantomJS', 'Proxy', 'Remote', 'Safari', 'TouchActions', 'WebKitGTK', 'WebKitGTKOptions', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', '__version__', 'android', 'blackberry', 'chrome', 'common', 'edge', 'firefox', 'ie', 'opera', 'phantomjs', 'remote', 'safari', 'support', 'webkitgtk']
여기서는 Chrome을 사용한다고 했지만 webdriver 객체(모듈)가 가진 속성을 확인해보면, Chrome이외에도 safari, android, phantomjs 등 다양한 웹 드라이버를 사용할 수 있도록 제공한다.
driver = webdriver.Chrome('D:/web_crawling/chromedriver')
driver객체만 생성하면 빈 화면이 켜지는데, 이것을 끄면 driver를 사용할 수 없으므로 놔두어야 한다.
1-2. driver객체의 다양한 메소드
implicitly_wait: 웹 로드 대기시간 설정
Selenium은 기본적으로 웹 자원들이 모두 로드 될때까지 기다리지만, implicitly_wait를 통해 직접 기다리게 하는 시간을 지정해 줄 수 있다.
driver = webdriver.Chrome('D:/web_crawling/chromedriver')
driver.implicitly_wait(3) # 3초간 wait
get: url 접근
이제 get을 이용해 url에 접근해보자.
driver = webdriver.Chrome('D:/web_crawling/chromedriver')
driver.implicitly_wait(3) # 3초간 wait
driver.get('https://google.com')
-
페이지 단일 element 접근
find_element_by_name("HTML_name")
find_element_by_id(‘HTML_id’)
find_element_by_xpath(‘/html/body/some/xpath’) -
페이지의 여러 elements에 접근
find_element_by_css_selector(‘#css > div.selector’)
find_element_by_class_name(‘some_class_name’)
find_element_by_tag_name(‘h1’) -
현재 페이지의 모든 elements
page_source
위 Selenium의 내장함수들을 이용해 브라우저의 HTML을 파싱할 수도 있지만, 보통은 page_source를 이용해 모든 elements를 불러오고 BeautifulSoup라이브러리를 이용하는 경우가 많다.
2. 네이버 로그인하기
우선 앞에서 배운 방법을 바탕으로, 네이버 로그인 페이지로 접근한다.
from selenium import webdriver
driver = webdriver.Chrome('D:/web_crawling/chromedriver')
driver.implicitly_wait(3) # 3초간 wait
driver.get('https://nid.naver.com/nidlogin.login')
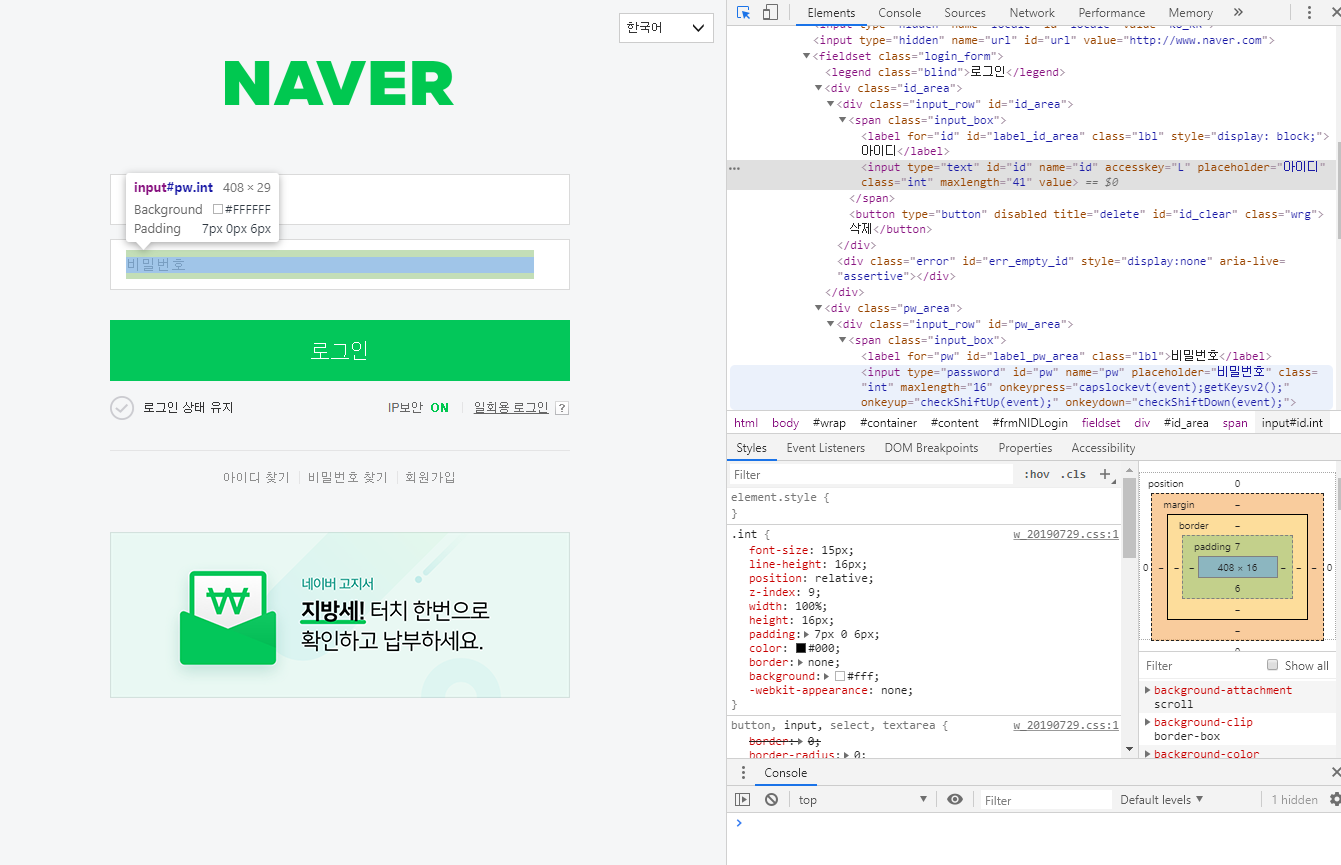
개발자도구로 페이지 소스로 아이디와 비밀번호 입력란의 name을 확인해야 한다.
확인결과 아이디는 name = ‘id’, 비밀번호는 name = ‘pw’이다.
앞에서 말한 selenium 내장함수로 페이지의 단일 element에 접근해 아이디와 비밀번호를 입력한다.
driver.find_element_by_name('id').send_keys('naver_id')
driver.find_element_by_name('pw').send_keys('passward')
코드를 실행하면 자동으로 입력된 것을 확인할 수 있다.
driver.find_element_by_xpath('//*[@id="frmNIDLogin"]/fieldset/input').click()
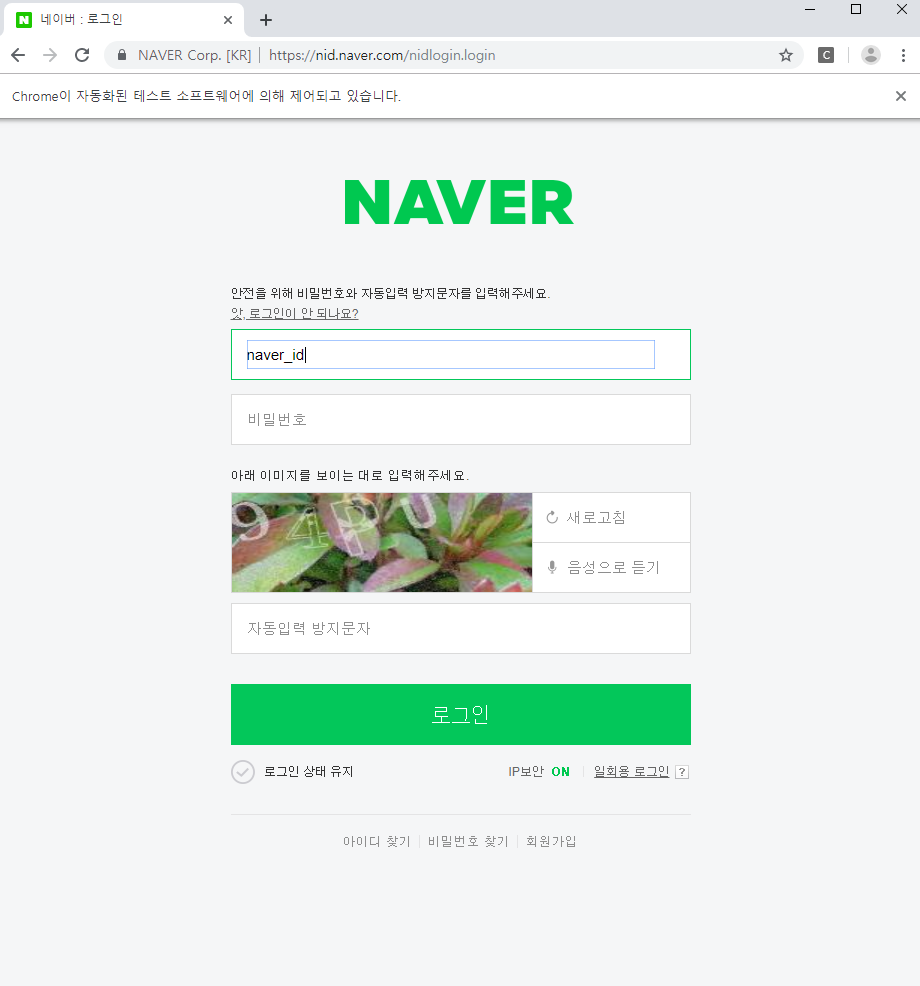
현재는 네이버 캡차(Captcha)가 이를 감지하여 자동로그인이 안되게 막아놓았다.
다른 방법으로 여기의 내용을 참고하면 좋을 것 같다.
2-1. find_element_by_xpath(XML path)
로그인 버튼을 클릭하기 위해 사용한 Selenium 내장함수 find_element_by_xpath에 들어간 ‘//*[@id=”frmNIDLogin”]/fieldset/input’는 약간 생소하다.
이 함수는 XML문서의 일부분을 탐색하고 선택하는데 사용하는 쿼리 언어다.
- 루트 노드 대 루트가 아닌 노드
- /div 는 오직 문서의 루트에 있는 div 노드만 선택한다.
- //div 는 문서의 어디에있든 모든 div노드를 선택한다.
- 속성 선택
- //@href는 href 속성이 있는 모든 노드를 선택한다.
- //a[@href=’http:\/\/google.com’]는 구글을 가리키는 모든 링크를 선택한다.
- 위치에따른 노드 선택
- (//a)[3]는 문서의 세 번째 링크를 선택한다.
- (//table)[last()]는 문서의 마지막 테이블을 선택한다.
- (//a)[position() < 3]는 문서의 처음 두 링크를 선택한다.
- 아스테리스크(*)는 어떤 문자나 노드의 집합이든 선택한다.
- //table/tr/*은 모든 테이블에서 모든 자식 tr태그를 선택한다.
- //div[@*]는 속성이 하나라도 있는 모든 div태그를 선택한다.
출처 : Dev-ing블로그
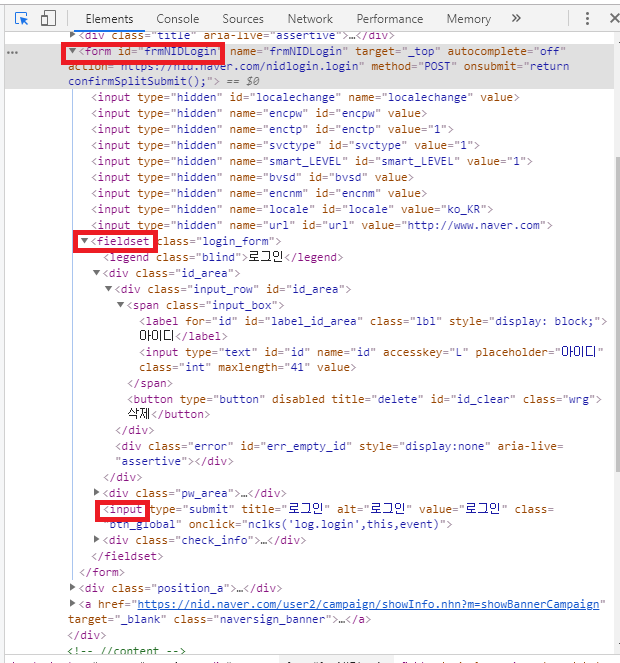
로그인 버튼의 태그 구조를 살펴보면 위와 같다.
이 구조와 XML쿼리 언어를 이해해야한다.
3. 네이버 뉴스 접근해보기
앞서 네이버 로그인을 자동으로 하는 코드를 짠 것을 응용해서, 네이버 뉴스 페이지에 접근해 자료를 가져와보자.
특히 html구조와 버튼 클릭을 위한 xpath에 들어가는 xml쿼리에 익숙해질 필요가 있다.
네이버 뉴스 접근 소스는 다음과 같다.
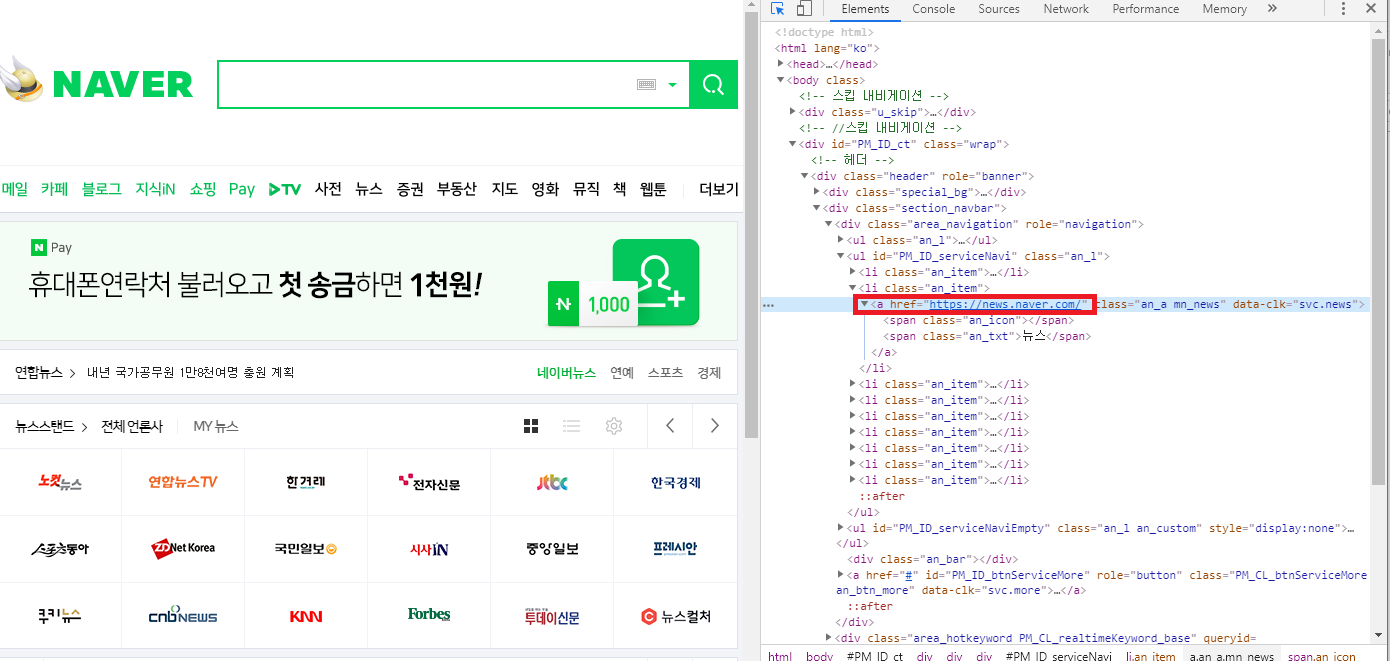
위에서 로그인 버튼 클릭때 썼던 코드를 참고하여, 네이버 뉴스 버튼을 클릭하기 위해서는 다음과 같이 하면 된다.
from selenium import webdriver
from bs4 import BeautifulSoup
driver = webdriver.Chrome('D:/web_crawling/chromedriver')
driver.implicitly_wait(3) # 3초간 wait
driver.get('https://www.naver.com')
driver.find_element_by_xpath('//a[@href="https://news.naver.com/"]').click()
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
highlight = soup.select("strong.ht_title")
highlight
[<strong class="ht_title">소비자물가 54년만에 첫 ‘마이너스'…임박한 ...</strong>,
<strong class="ht_title">아시아나항공 인수戰, 예비입찰에 5곳 격돌</strong>,
<strong class="ht_title">文대통령, 조국 임명 수순 돌입… 검찰은 아내...</strong>,
<strong class="ht_title">청, 조국 임명 강행 수순… 야, 격앙</strong>,
<strong class="ht_title">President Moon to request Cho Kuk’s Assembly ...</strong>,
<strong class="ht_title">초유의 마이너스 물가…`D의 공포` 엄습</strong>,
<strong class="ht_title">조국 셀프 면죄부에… 檢, 단국대 교수·처남 ...</strong>,
<strong class="ht_title">분양가 상한제 아파트 55%가 강남</strong>,
<strong class="ht_title">물가상승률 바닥 깨졌다</strong>,
<strong class="ht_title">“대학 채점공개로 ‘깜깜이 학종’ 고치고 균형...</strong>,
<strong class="ht_title">"배터리 전쟁 확전 막자" 정부, SK-LG ...</strong>,
<strong class="ht_title">[단독] 조국 딸 받은 '동양대 총장상'···...</strong>,
<strong class="ht_title">D의 공포…사상 첫 마이너스 물가</strong>,
<strong class="ht_title">[알립니다]LG와 함께하는 '동아 다문화賞' ...</strong>,
<strong class="ht_title">문 대통령의 직진… 이르면 주말 조국 임명</strong>,
<strong class="ht_title">실적 악화에 좁아진 취업문..긴장하는 취준생</strong>,
<strong class="ht_title">3중 족쇄에...연말 가계대출 기근 온다</strong>,
<strong class="ht_title">[단독] "조국 펀드 핵심 인물들 필리핀에 함...</strong>,
<strong class="ht_title">'불화수소' 일본산 대체 스타트...일부 반도...</strong>]
간단하게 신문 헤드라인의 굵은글씨(high light)만 BeautifulSoup를 이용해 긁어와 보았다.
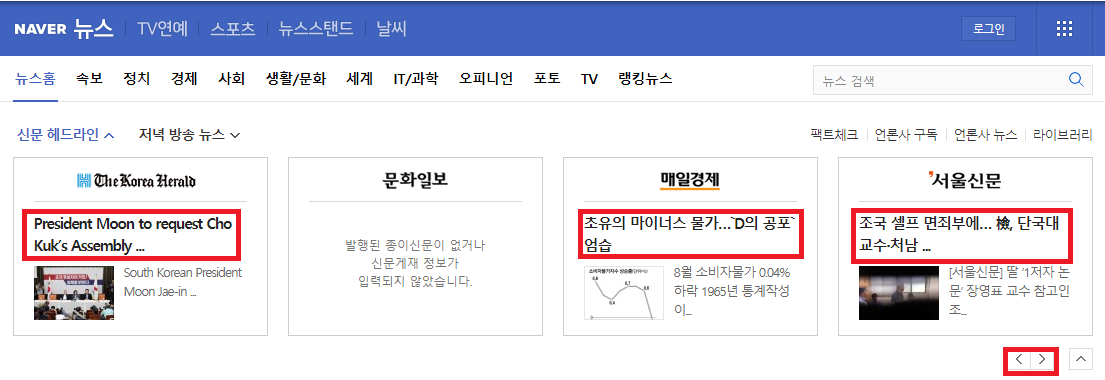
이렇게 긁어오고 싶은 텍스트들이 어떤 html구조로 형성되어 있는지 먼저 파악하는 시간을 갖는게 중요하다.
다음 포스팅에서는 html을 parsing해서 원하는 텍스트를 가져올 수 있도록 BeautifulSoup라이브러리에 대해 자세하게 공부해 볼 것이다.

댓글남기기