
[Handson ML] 투표기반 분류기(Voting classifiers) - 앙상블
업데이트:
개요

앙상블(ensemble)이란, 가장 좋은 모델 하나만 사용하는게 아니라 이미 만든 괜찮은 일련의 예측기(분류 또는 회귀)를 연결하여 더 좋은 예측기를 만드는 방법이다.
그 종류에는 크게 3가지가 있다.
- 투표기반(Voting)
- 배깅(Boostrap AGGregatING, Bagging)
- 부스팅(Boosting)
이 방식들에 대해서 차례대로 알아볼텐데, 이번 포스팅에서는 투표기반 분류기(Voting classifiers)에 대해 알아보자.
투표 기반 분류기
1-1. 직접 투표
어떤 훈련 데이터셋에 대하여 여러 분류기(로지스틱 회귀, SVM, 랜덤포레스트 등등)를 훈련시켰다고 해보자.
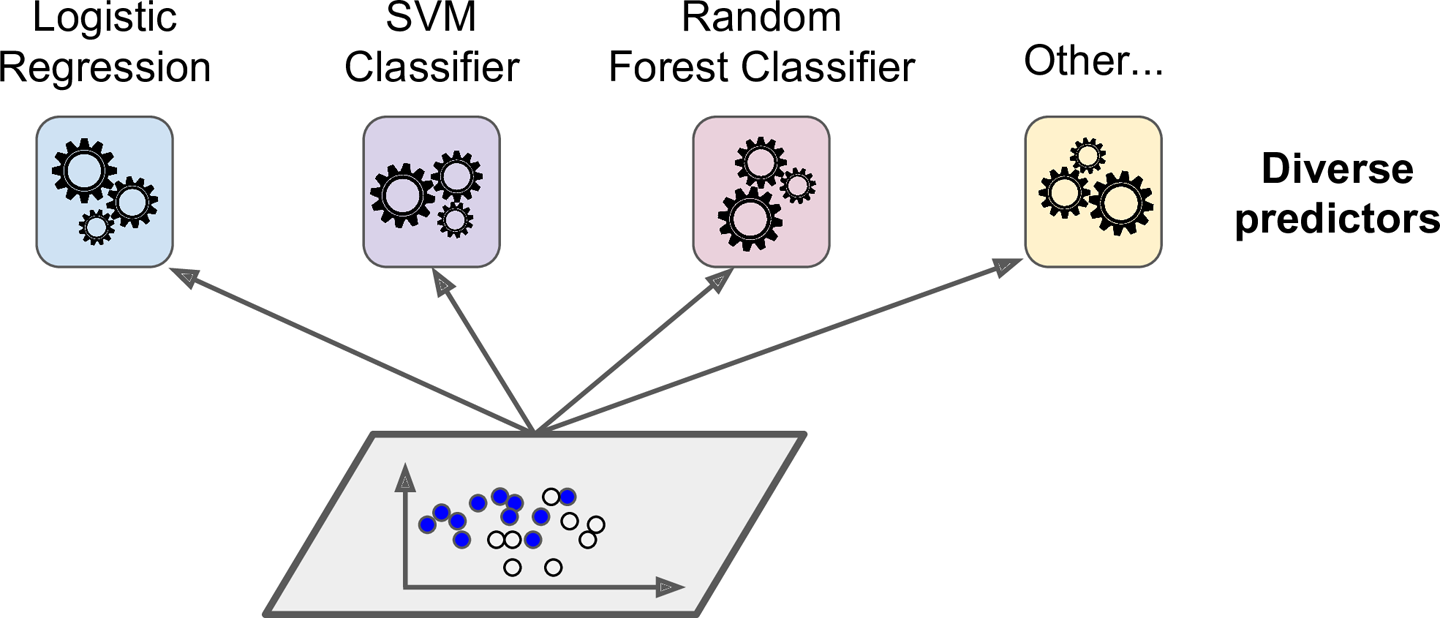
여기서 더 좋은 분류기를 만들기 위해 각 분류기의 예측을 모아 다수결 투표로 정하는 것을 직접 투표(hard voting)분류기라고 한다.
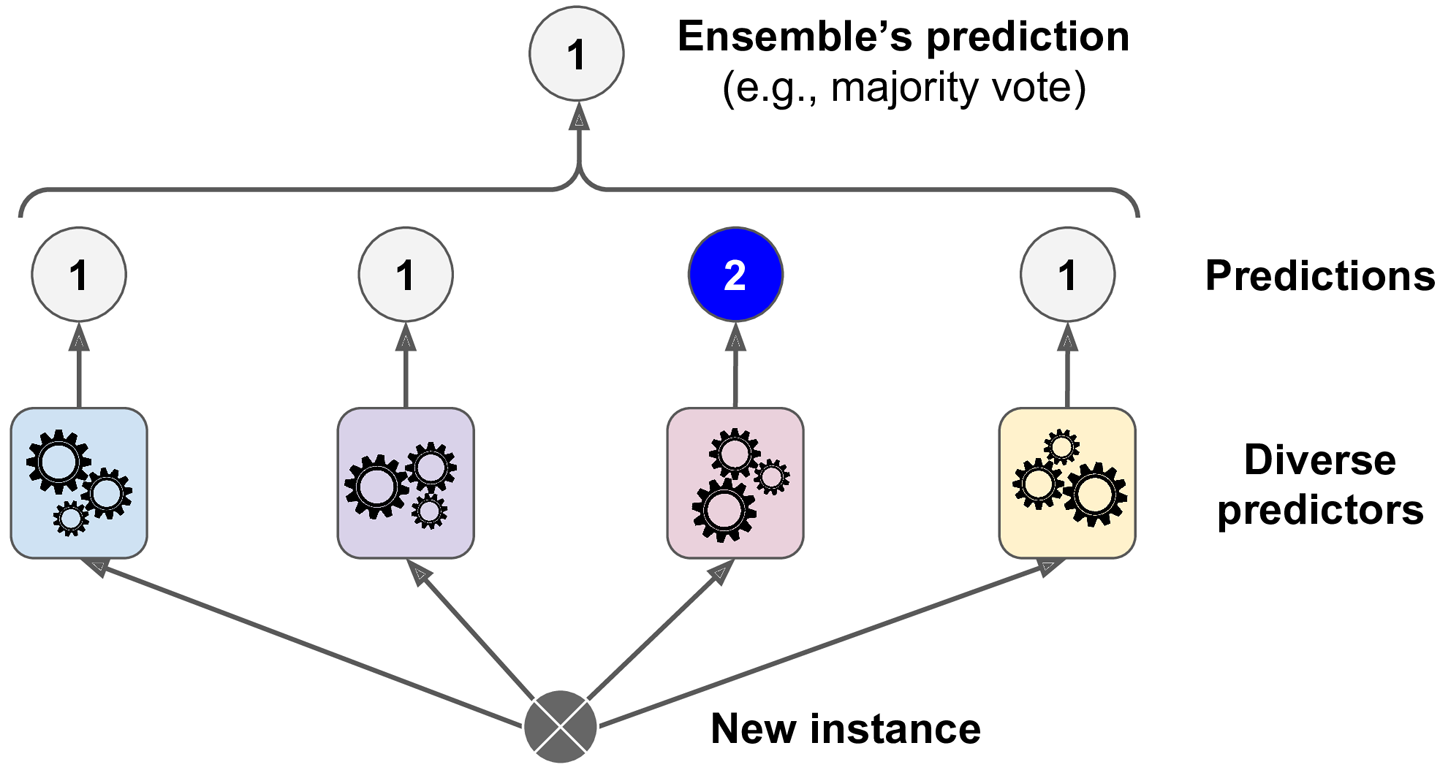
이 다수결 투표 분류기가 앙상블에 포함된 개별 분류기 중 가장 뛰어난 것보다 정확도가 높은 경우가 많다.(훈련데이터가 많고 다양하다면)
이러한 원리가 가능한 이유는 대수의 법칙(law of large numbers)과 관련이 있다.
*대수의 법칙
앞면이 나올 확률이 51%, 뒷면이 49%인 어떤 동전이 있다고 가정해보자.
이 동전을 1000번 던지면 앞면은 510번, 뒷면은 490이 나올 것이다.(이상적인 상황)
이를 수학적으로 계산해보면 1000번을 던진 후 앞면이 다수(뒷면보다 많은)일 확률은 75%에 가깝다는 것을 계산할 수 있고, n이 커질 수록 이 확률은 1에 가까워 진다.
이항확률분포를 보자.
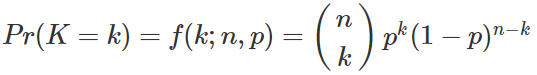
즉, 위 식에서 p=0.51, n=1000이 되며 x를 1부터 499까지 누적한 누적이항확률분포를 구해 1에서 뺀것이 바로 앞면이 절반이상 나올 확률이 된다.
누적이항확률을 계산해주는 scipy모듈로 확인해보자.
from scipy.stats import binom
print(1 - binom.cdf(49,100,0.51))
print(1 - binom.cdf(499,1000,0.51))
print(1 - binom.cdf(4999,10000,0.51))
0.6180787124933089
0.7467502275561786
0.9777976478701533
이처럼 동전을 던지는 횟수가 커질수록(n이 커질수록) 이상적인 상황(앞면이 뒷면보다 많이나오는)에 가까워 지는 것을 알 수 있다.
# jupyter notebook 한글 깨질때
import matplotlib
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
font_name = font_manager.FontProperties(fname="C:/Windows/Fonts/-윤고딕320.ttf").get_name()
rc('font', family=font_name)
matplotlib.rcParams['axes.unicode_minus'] = False
import numpy as np
heads_proba = 0.51
coin_tosses = (np.random.rand(10000, 10) < heads_proba).astype(np.int32)
# 여기서는 0~1사이의 난수 중, 0.51보다 작은 수를 앞면이 나온 것으로 이용했다.
cumulative_heads_ratio = np.cumsum(coin_tosses, axis=0) / np.arange(1, 10001).reshape(-1, 1)
plt.figure(figsize=(8,3.5))
plt.plot(cumulative_heads_ratio)
plt.plot([0, 10000], [0.51, 0.51], "k--", linewidth=2, label="51%")
plt.plot([0, 10000], [0.5, 0.5], "k-", label="50%")
plt.xlabel("동전을 던진 횟수")
plt.ylabel("앞면이 나온 비율")
plt.legend(loc="lower right")
plt.axis([0, 10000, 0.42, 0.58])
plt.show()
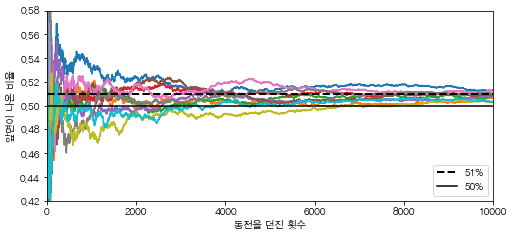
이와 같이 10번의 실험을 한 결과, 각 실험 모두 동전을 던진 횟수가 커질수록 초기 확률(heads_proba)에 가까워 지는 것을 확인할 수 있다.
이제 다시 앙상블 방법으로 돌아와, 해석해보자.
51%의 정확도(앞면이 나올확률)를 가진 1000개(동전을 던진 횟수)의 분류기로 앙상블 모델을 구축한다고 가정해보자.
가장 많은 범주를 분류의 예측으로 삼는다면 약 75%의 정확도를 기대할 수 있고, 분류기가 많아질수록 거의 완벽하게 예측이 가능하다는 말이다.
하지만 이는 모든 분류기가 완벽하게 독립적이고, 오차에 상관관계가 없어야 가능한 얘기다. 분류기들이 같은 종류의 오차를 만들기 쉽기 때문에 잘못된 범주가 더 많은(다수인) 경우에는 앙상블의 정확도도 낮아진다.
다음 moon 데이터 셋을 이용한 예제를 하나더 보자.
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=500, noise=0.30, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
log_clf = LogisticRegression(solver = 'liblinear')
rnd_clf = RandomForestClassifier(n_estimators=10)
svm_clf = SVC(gamma='auto')
voting_clf = VotingClassifier(estimators=[('lr',log_clf),
('rf',rnd_clf),
('svc',svm_clf)],
voting='hard')
voting_clf.fit(X_train, y_train)
from sklearn.metrics import accuracy_score
for clf in (log_clf, rnd_clf, svm_clf, voting_clf):
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(clf.__class__.__name__, accuracy_score(y_test,y_pred))
LogisticRegression 0.864
RandomForestClassifier 0.888
SVC 0.888
VotingClassifier 0.896
결과, 투표기반 앙상블 분류기(VotingClassifier)가 다른 개별 분류기보다 성능이 조금 더 높다.
1-2. 간접 투표
모든 분류기가 범주마다의 예측확률을 예측할 수 있으면(predict_proba()메서드가 있으면) 개별 분류기의 예측을 평균해서 확률이 가장 높은 범주를 예측할 수 있다.
이를 간접 투표(soft voting) 방식이라고 한다.
앞의 직접 투표(hard voting)방식은 개별 분류기마다 다수인 범주가 무엇이냐에 따라 투표로 앙상블의 예측을 결정했다면, 간접 투표(soft voting) 는 각 분류기마다 해당 범주에 속할 확률(0~1값)을 평균을 내어, 이 평균이 가장 높은 범주로 분류한다.
즉, 이와 같은 방식은 단순히 개별 분류기마다의 예측결과만을 고려하지 않고 높은 확률값을 반환하는 모델의 비중을 고려할 수 있기 때문에 성능이 더 좋다.
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
log_clf = LogisticRegression(solver = 'liblinear')
rnd_clf = RandomForestClassifier(n_estimators=10)
svm_clf = SVC(gamma='auto', probability=True)
voting_clf = VotingClassifier(estimators=[('lr',log_clf),
('rf',rnd_clf),
('svc',svm_clf)],
voting='soft')
voting_clf.fit(X_train, y_train)
VotingClassifier(estimators=[('lr',
LogisticRegression(C=1.0, class_weight=None,
dual=False, fit_intercept=True,
intercept_scaling=1,
l1_ratio=None, max_iter=100,
multi_class='warn',
n_jobs=None, penalty='l2',
random_state=None,
solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)),
('rf',
RandomForestClassifier(bootstrap=True,
class_weight=None,
criterion='g...
n_jobs=None,
oob_score=False,
random_state=None,
verbose=0,
warm_start=False)),
('svc',
SVC(C=1.0, cache_size=200, class_weight=None,
coef0=0.0, decision_function_shape='ovr',
degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=True,
random_state=None, shrinking=True, tol=0.001,
verbose=False))],
flatten_transform=True, n_jobs=None, voting='soft',
weights=None)
from sklearn.metrics import accuracy_score
for clf in (log_clf, rnd_clf, svm_clf, voting_clf):
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(clf.__class__.__name__, accuracy_score(y_test,y_pred))
LogisticRegression 0.864
RandomForestClassifier 0.888
SVC 0.888
VotingClassifier 0.912
위에서 구현한 코드에서 간접 투표(soft voting) 방식을 적용하려면 VotingClassifier의 voting = 'soft'옵션을 주고, SVC모델은 기본값으로 범주에 속할 확률을 제공하지 않으므로 probability=True옵션을 주어야 한다.
실제로 간접 투표 방식의 앙상블 모형 정확도가 약 91%로 더 높게 나온 것을 알 수 있다.
Reference
도서 [Hands-0n Machine Learning with Scikit-Learn & Tensorflow] 를 공부하며 작성하였습니다.

댓글남기기