
[Hadoop] Hadoop Ecosystem과 구성요소들에 대한 이해(HDFS, MapReduce, Hive, Imapla, Spark, Kudu, Sqoop 등)
업데이트:
개요
![]()
출처: https://1004jonghee.tistory.com/
이번 포스팅에서는 Hadoop이란 무엇인지, 이를 둘러싼 Ecosystem에 포함되는 서브프로젝트들이 어떤 배경에서 만들어졌고 어디에 쓰이게 되는지 전반적으로 정리해보려고 한다. 이후 포스팅들에서는 각 서브 프로젝트에 대해 세부 내용을 정리하는 시간이 있을 것 같다.
BigData
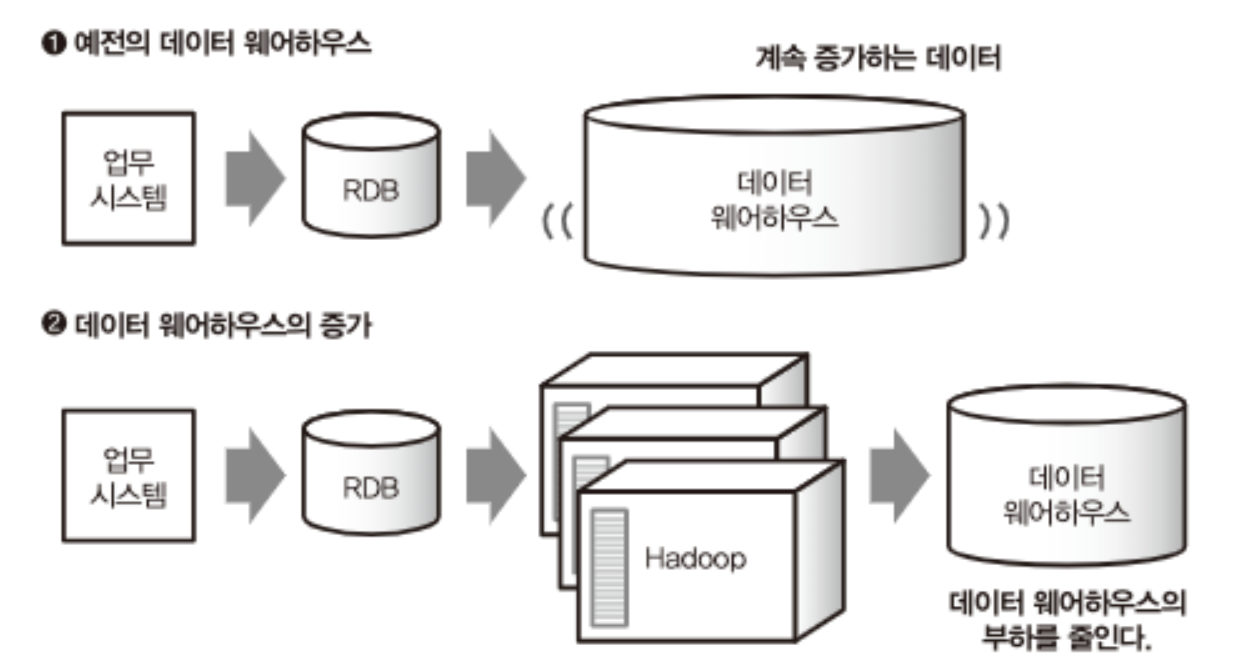
출처: 도서-빅데이터를 지탱하는 기술
먼저 Hadoop이 왜 필요해졌을까? 벌써 20년도 전이긴 하지만 모바일 및 인터넷의 보급으로 전세계적으로 접근 가능한 시스템이 증가함에 따라, 기존 RDB로는 취급할 수 없는 수준으로 대량의 데이터가 쌓이게 된다.
기업들은 꽤 많은 문제에 봉착하게 되는데.
- 기존 RDB Storage 자체가 빅데이터에 비해 작음
- 통합 시스템(Centralized)이기 때문에 확장이 어려움
- RDB에 적합하지 않은 비정형 데이터(이미지, 영상, 텍스트 등)들의 증가
- 빅데이터의 생산 가속도가 월등히 높기 때문에 위 1~3에 대한 대응이 지속가능하지 않음
이를 위해 하나의 통합 시스템의 사양을 계속 업그레이드하기 보다는 여러 대의 컴퓨터에게 작업을 분산시켜(Distributed Prallel Processing) 효율성을 높이고자하는 필요성이 대두되었고, 이게 하둡(Hadoop)의 간단한 개발 배경이 된다고 할 수 있다.
분산 병렬 처리(Distributed Prallel Processing) 기술이란? 다음의 특징을 가진다.
Distributed: 실행 주체가 분산되어 있다.- Hadoop 소프트웨어를 실행하는 각 서버들을 Cluster라고 부른다.
Scale-Out: 확장이 가능하다.Fault-tolerant: 결함(fault), 고장(failure)이 발생해도 정상/부분적으로 기능을 수행할 수 있다.여러 데이터 형태의 처리가 가능해야 하다.
스몰데이터와 빅데이터
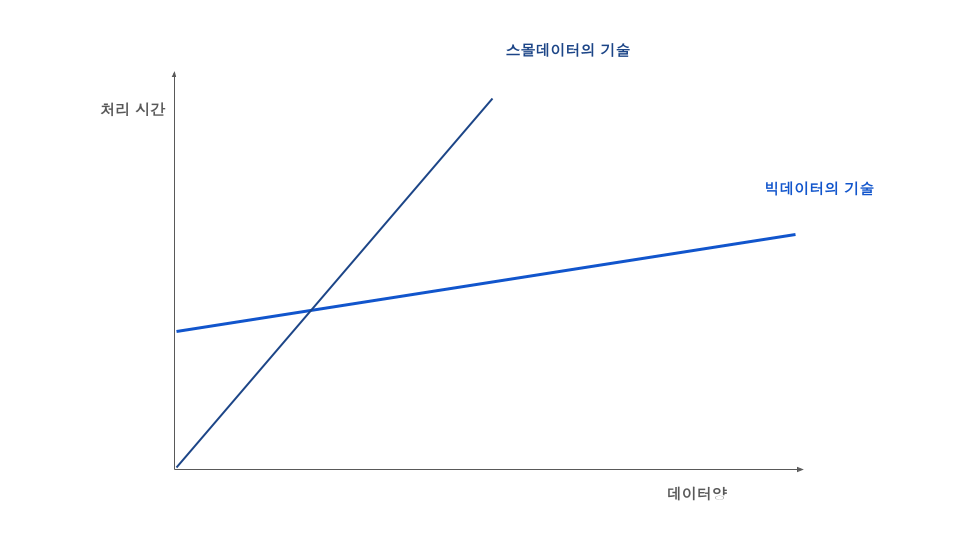
출처: 도서-빅데이터를 지탱하는 기술
그럼 빅데이터 시스템인 Hadoop이 언제나 좋은 것일까?
꼭 그런 것은 아니다.
분산 처리 기술 없이 개인 노트북이나 서버에서 처리할 수 있는 GB 수준의 데이터를 스몰데이터라고 할 때, 위 그림처럼 스몰 데이터에서 빅데이터 기술의 효율은 오히려 떨어진다.
간단하게는 분산 처리 기술에서 최소한의 실행 준비 시간이 필요(ex. 대표기술인 MapReduce 실행을 위해 태스크 스케쥴을 잡고 데이터를 우선 blcok 단위로 나누는 등)하기 때문에, 일정 규모 이상의 빅데이터에서 부터 효율이 발생한다.
그러므로 우리는 필요한 상황에 필요한 기술을 인지하고 적재적소에 활용할 필요가 있다.
Hadoop
먼저 하둡(Hadoop)은 위에서 살펴본 바와 같이 여러 대의 컴퓨터에게 작업을 분산시켜 처리 효율성을 높이고자 하는 목적에서 개발된 분산 처리 오픈소스 프레임워크이다.
Hadoop은 아래 3가지 코어 프로젝트로 구성되어 있다.
- HDFS(Hadoop Distributed File System)
- 데이터를 분산 저장하는 역할(e.g. Data Storage)
- MapReduce
- 분산 저장된 데이터를 처리하는 역할(e.g. Execution Engine)
- YARN
- 리소스 관리자 역할 (Hadoop ver2부터 MapReduce의 역할 일부가 YARN으로 떨어져나옴)
HDFS
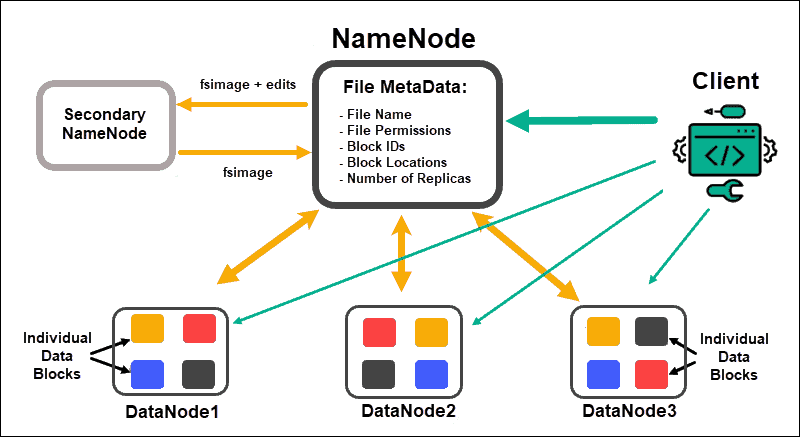
출처: https://phoenixnap.com/kb/apache-hadoop-architecture-explained
HDFS는 위 그림처럼 FIle System의 Metadata(파일명, 파일경로, 권한 등)을 포함하고 있는 NameNode와 실제 데이터들이 Block단위로 분산 및 복제 저장되어 있는 DataNode로 구성되어 있다.
HDFS는 파일을 Block이라는 단위로 나누어 관리하는데, 1개 파일은 여러 block으로 나뉘고 여러 DataNode에 복제(Replication) 저장된다(나눠진 block 파일들은 blk_xxxxxx 라는 명칭으로 저장된다).
위와 같이 데이터를 분산 및 복제 저장에는 아래와 같은 특징이 있다.
- Block Unit
- 대용량 데이터를 효율적이고 병렬처리가 가능하도록 분산 저장
- Block의 기본 Size는 128MB이므로 이보다 작은 데이터를 HDFS에 저장하는것은 비효율적임
- Replication
- 특정 DataNode에 장애(Failure)가 생기더라도 안정성 유지 가능
- DataNode를 추가하면 디스크 용량이 증가하므로 유연한 확장도 가능
- 기본적으로 3개 Node에 복제하므로 데이터의 3배에 해당하는 디스크 용량이 필요
MapReduce
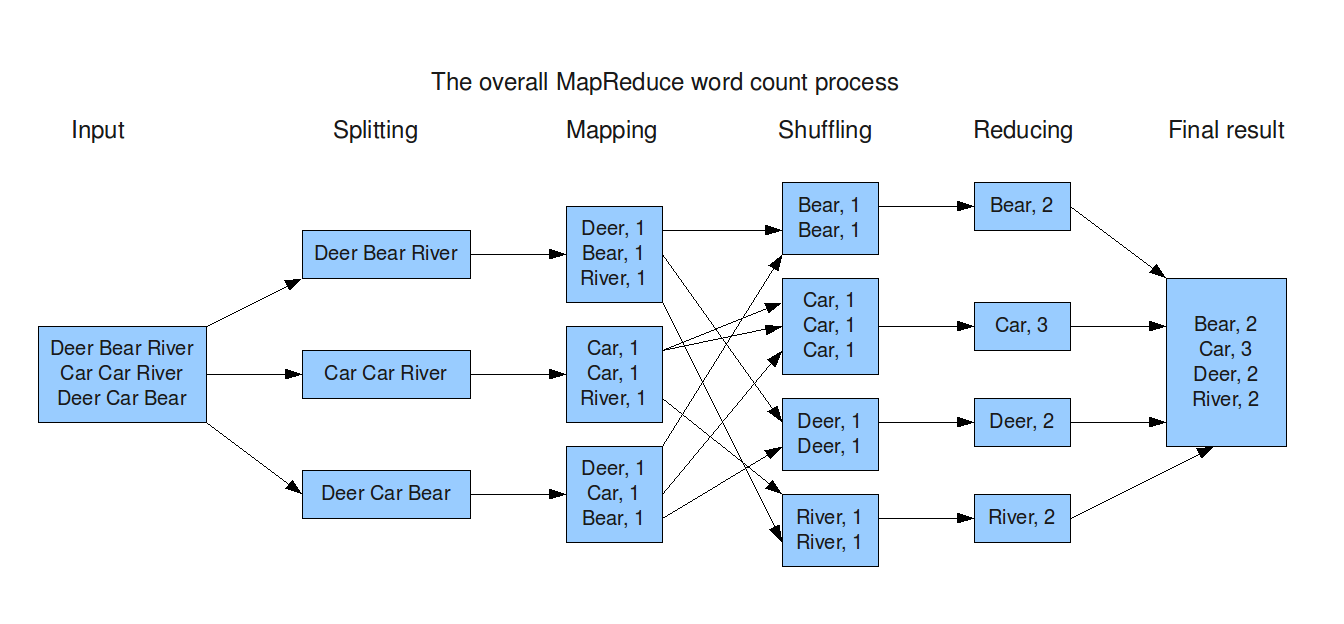
Hadoop은 위와 같이 HDFS에 분산 저장된 데이터를 처리하기 위해 기본적으로 구글에서 발표한 MapReduce 엔진을 사용한다. MapReduce는 병렬 컴퓨팅 환경에서의 데이터 처리 엔진으로, 각 Block에 대해 Map Task와 Reduce Task를 통해 원하는 데이터를 추출하는 작업을 수행한다.
- Map Task-Transformation
- (Input) HDFS에 Block 단위로 저장된 데이터를 Input으로 입력받음
- (Splitting) Block 내의 텍스트 파일을 line별로 분리함
- (Mapping) line의 구분자를 기준으로 (Key, Value)쌍 형태로 맵핑함
- Reduce Task-Aggregation
- (Shuffling) 같은 Key를 가지는 쌍별로 분류 및 정렬
- (Reducing) 최종적으로 분산되어 있는 연산 결과를 병합
이와 같이 Map과 Reduce Task를 수행할 때 각각의 단계마다, 중간 산출물들(ex. Key-value 값 등)을 Disk 공간에 파일을 읽고 쓰는 과정이 반복된다.
따라서 제한된 메모리로도 컴퓨터(e.g. 하드 디스크)가 추가됨에 따라 대규모 데이터를 확장가능하게 처리할 수 있다.
(이 특징이 현재는 단점으로 작용하여 개선된 오픈소스들이 나오고 있다)
YARN
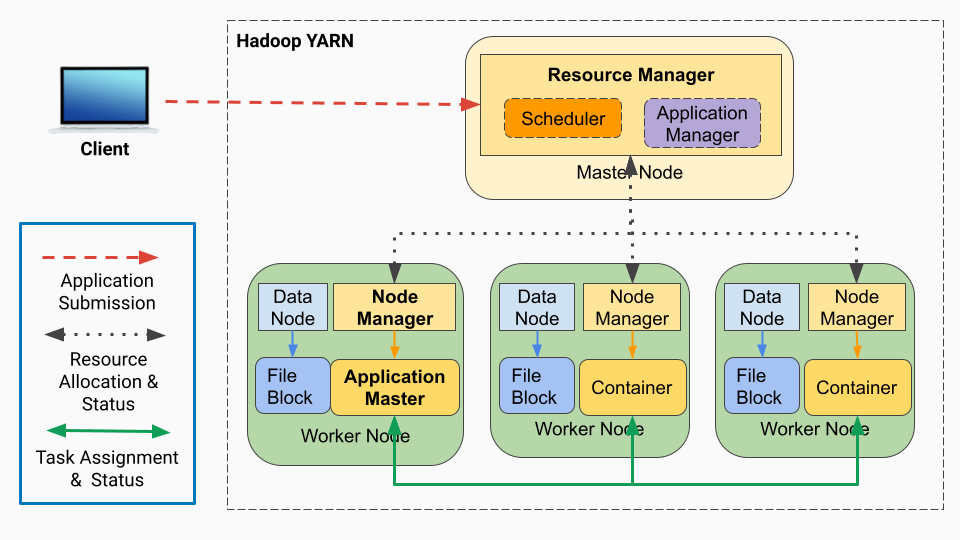
출처: https://medium.com/@chenglong.w1/
YARN은 Yet Another Resource Negotiator의 약자로, Hadoop이 데이터를 저장하고 처리하는 모든 수행들에 대해 리소스(CPU, 메모리 등)를 관리하고 작업 스케쥴링을 도와주는 리소스 매니저이다.
Resurce Manager와 하나 이상의 Node Manager로 구성되어 있으며, Node Manager는 실제 Data Node의 개수 만큼 서버를 구성하는 것이 일반적이다.
Resource Manager: 서버 클러스터에서 돌아가는 모든 application들의 Resource를 관리하고 할당하는 역할Scheduler: 실행될 Application에 Resource를 할당시키는 역할Application Manager: 실행에 앞서 첫번째 DataNode의 Application Master를 실행시킬 수 있는지 검토
Node Manager: 내부 Container의 Resource(CPU, 메모리, 디스크 등)을 모니터링하고 Resource Manager에 알려주는 역할Container: Applications Master에 의해 결정된 만큼의 리소스를 받아 Task를 수행
Hadoop Ecosystem?
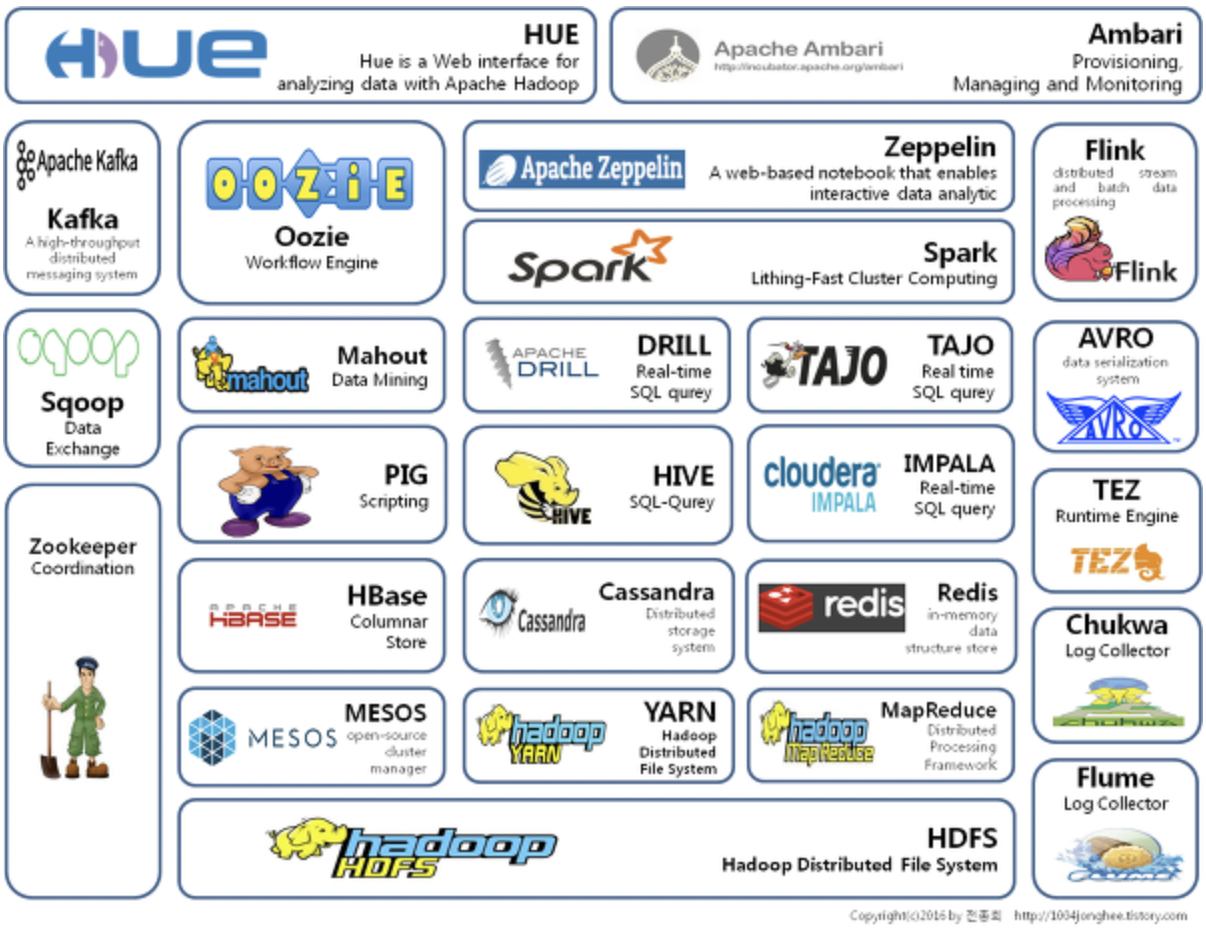
출처: https://1004jonghee.tistory.com/
이후에는 Hadoop의 코어 기술만으로는 활용이 어렵거나 개선이 필요한 부분들을 보완하는 다양한 서브 프로젝트들이 등장하기 시작했다. 이러한 기술들은 Hadoop의 각 기술 도메인 파트에 붙어서 편의성을 향상시키고 있으며, 각 프로젝트들을 통틀어 Hadoop Ecosystem이라고 부른다.
- Data Processing
Hive,Impala,Spark,Pig,MapReduce
- Data Ingestion
Kafka,Flume,Sqoop
- Data Storage
Hbase,Kudu,HDFS
- Resource Management
YARN,Mesos
- Scheduling
Oozie,Airflow
- Visualization & Web UI
Hue,Zeppelin
Hive
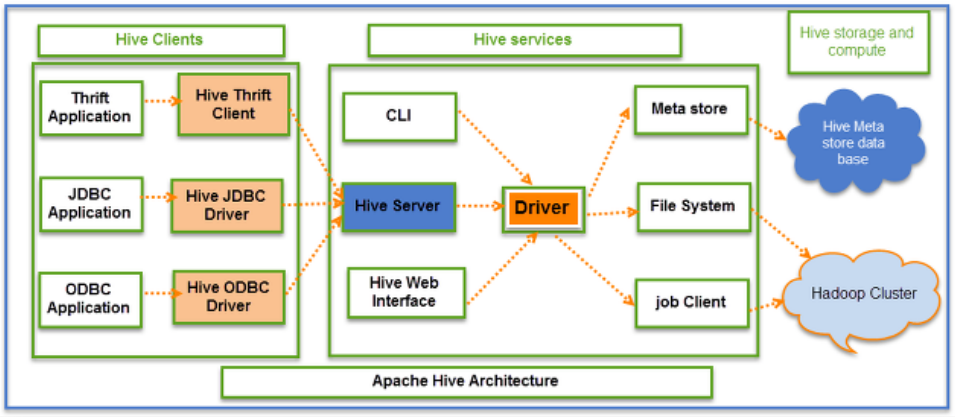
출처: https://datacookbook.kr/88
Hive는 Hadoop을 기반으로 하는 데이터웨어하우징용 오픈소스 솔루션이다.
위에서 설명한 HDFS와 MapReduce 사용을 위해서는 Java나 Python등의 프로그래밍이 필요한데, 기존에 RDB와 SQL만 사용하던 사용자들에게는 진입장벽이 존재했다.
이를 위해 Hadoop에서 SQL로 편하게 질의하고 데이터를 가져올 수 있도록 오픈소스를 개발한 것이다.
이에 따라 Hive에는 FileSystem으로만 구성되어 있는 Hadoop과 RDB의 격차를 줄이기 위한 요소들로 구성되어 있다.
- Meta Store: RDB의 Table schema 정보 역할!
- Hive 실행 시 필요한 테이블 및 Column과 같은 스키마 정보들을 관리 (실데이터는 HDFS에 저장되어 있음)
- 물리적으로는 HDFS와는 별도로 MySQL 등의 DB로 구성됨
- Hive Server: SQL을 입력받는 역할
- Hive에 Query하는 가장 앞단의 서버(HiveQL)
- HiveQL은 SQL과 거의 유사한 Hive의 SQL 언어
- 위 그림과 같이 JDBC, ODBC로 부터 Query를 받아 Driver에 전달
- Hive Server가 아닌 CLI로 바로 질의할 경우 제어 및 권한 없이 접근이 가능
- 보안상의 이유로 운영에서는 사용하지 않음
- Hive에 Query하는 가장 앞단의 서버(HiveQL)
- Driver: SQL을 MapReduce 등의 엔진으로 변환하는 역할
- 입력받은 SQL의 연산방식 계산 및 Optimizing하고 여러 엔진(MapReduce, Spark, Tez)과 연동
즉, Hive는 HDFS의 데이터에 대해서 Meta Store에 저장된 스키마(테이블)를 기준으로, 데이터를 MR(MapReduce), Spark, Tez 엔진 중 하나를 사용하여 처리하고, 이를 정형화된 테이블로 사용자에게 제공하는 SQL Tool이다.
단점도 몇 가지 존재하는데,
- HiveQL이 Map Reduce로 변환되어 실행될 때 응답시간이 매우 길고 대량 데이터의 Full-Scan에 최적화되어 있어서, 대화형 Ad-hoc Query 사용에 부적합함
- 실 데이터는 HDFS에 저장되어 있기 때문에, HDFS의 단점이 그대로 존재
- 데이터의 부분적인 수정/삭제(Record별 Update, Delete)가 불가능
- Transaction 관리 기능이 없어서 롤백 처리가 불가능
Impala
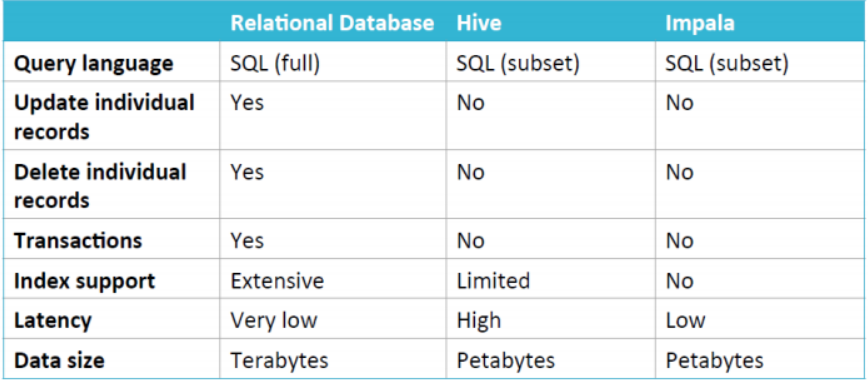
Impala는 Hive와 비슷한 특징을 가지고 있지만, 위에서 얘기한 대화형 Ad-Hoc 분석을 위한 Query 사용에 부적합한 단점을 보완하며 Cloudera에서 개발한 쿼리 엔진이다.
Impala의 몇가지 특징들은 다음과 같다.
- MapReduce 엔진으로 연동하는 것이 아닌 Impala 자체 엔진을 가지고 있기 때문에 응답속도가 빠름
- 빠른 응답을 위한 분석용(Ad-Hoc) Query에 최적화되어 있음
- 전용 Meta Store를 사용할 필요 없이, 기존 Hive Meta Store를 공유함
- Impala도 데이터를 HDFS에 저장하므로, 데이터의 부분적인 수정/삭제(Record별 Update, Delete)가 불가
Spark
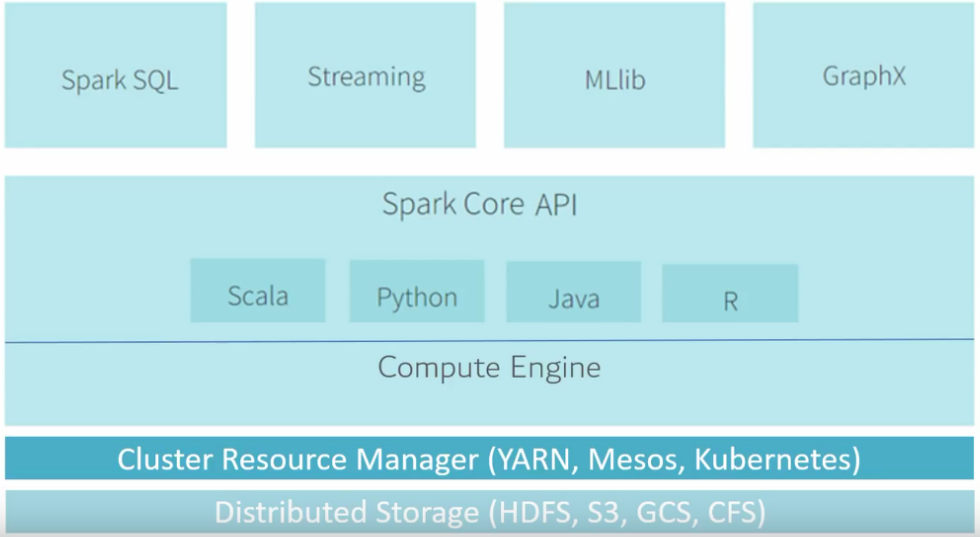
Spark는 인메모리(In-memory)기반의 고속 데이터 처리 엔진으로, 위에서 설명한 MapReduce의 한계를 혁신적으로 개선했다.
MapReduce가 데이터를 처리할 때마다 Disk I/O가 대량 발생했었는데 인메모리로 처리함으로써 연산속도가 대폭 개선되었다.
(시대 변화에 따라 메모리 비용이 절감되고 비용구조 자체가 바뀐 영향이 크다)
즉, “디스크에서 읽고 쓰는게 아니라 가능한 많은 데이터를 메모리에 올려두고, 디스크에는 아무것도 기록하지 말자”라는 아이디어
Spark의 특징들은 아래와 같다.
- Spark는 처리엔진을 의미하므로, 비교 대상은 하둡이 아닌 MapReduce임
- MapReduce는 HDFS의 데이터에만 적용되지만, Spark는 더 다양한 데이터 포멧에 적용 가능
- Spark 데이터 구조
RDD(Resilient Distributed Dataset)DataFrameDataset
Spark SQL: SQL로 쿼리를 실행하기 위함Spark Streaming: 실시간 데이터의 스트림 처리를 수행하기 위함MLlib: 머신러닝 알고리즘 제공
Kudu
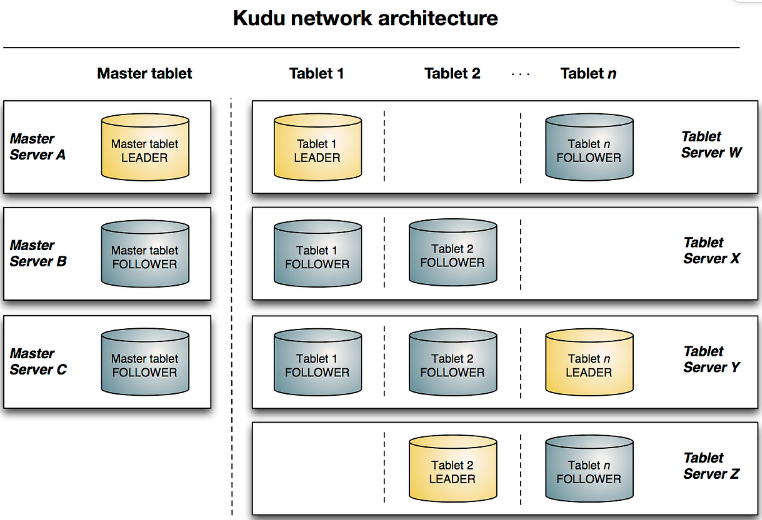
출처: https://kudu.apache.org/docs/
Kudu는 Hadoop 환경에서 사용되는 Column 기반 스토리지(Columnar Storage)이다. 즉, Column별로 파일에 저장한다. Cloudera에서 개발하였으며, 위에서 설명하기도 했지만 데이터의 부분적인 수정/삭제 등이 불가능한 HDFS의 단점과 NoSQL 기반인 Hbase의 단점을 동시에 보완한다.
Kudu의 특징은 아래와 같다.
- Kudu 자체는 Storage이므로 Query 엔진을 같이 사용해야함 (일반적으로 Impala를 사용)
- Impala에서 CRUD가 가능하도록 설계
- hive나 impala에서 얘기하는 Metastore 기반의 Table과는 위계가 다름 (Storage임)
- Kudu Architecture
Tablet- 특정 column을 기준으로 데이터를 분할 저장할 때 분할된 데이터를 의미
- Leader(Read, Write 요청)와 Follower(Read 요청)로 구성
Tablet Server- Tablet을 가지고 있는 서버로, 여러 Tablet을 가짐
- Master, Tablet 서버로 나눠지며, HDFS의 Name, Data노드와 유사한 원리
- Hive vs Kudu
- Hive는 수정이 발생되지 않는 대용량 데이터 저장소에 적합
- Kudu는 빈번한 변경이 발생되는 데이터 저장소에 적합
- Partition 기반 작업이 필요할 땐 Hive를 사용
- Key기반 작업이 필요할 땐 Kudu를 사용
Sqoop
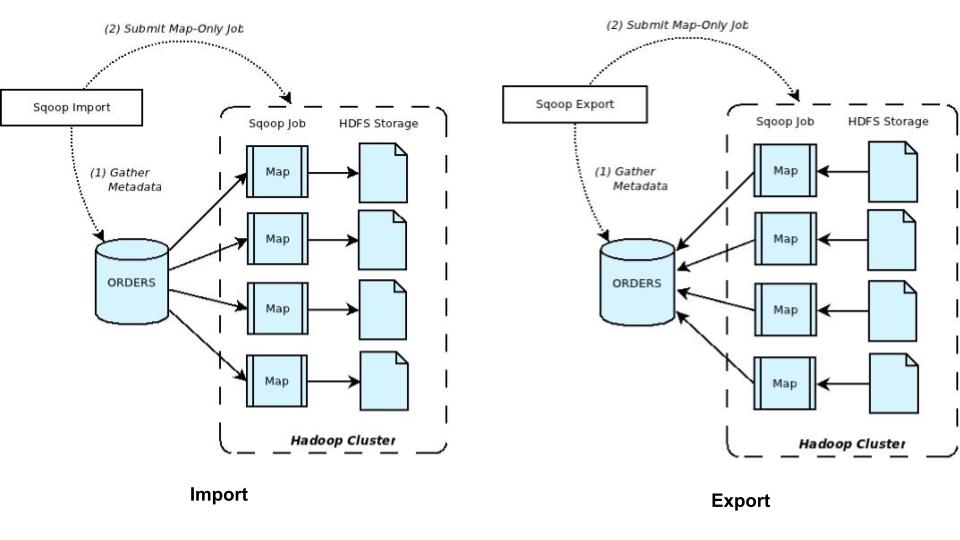
출처: http://sqoop.apache.org/index.html
Sqoop은 SQL-to-Hadoop의 약자로 HDFS와 RDBMS(Oracle, MySQL 등) 간의 대량 데이터 전송 목적으로 만들어진 툴이다.
import(RDBMS -> HDFS), export(HDFS -> RDBMS) 명령어로 수행되며, MapReduce의 Map task를 기반으로 수행된다.
Sqoop의 특징은 아래와 같다.
Import의 동작 방식 예시- import 실행 시 RDBMS에서 MetaData(컬럼, 타입 등)를 가지고 온다.
- Map Task로만 이루어진 Job(Map-Only Job)을 실행하여 Hadoop Cluster로 전송
- 원하는 데이터만 전송하는 것이지 가공은 하지 않기 때문에 Reduce Task는 필요없음
- Default 옵션
Where?: HDFS Home directoryHow?: plain (txt File)- File Delimeted
, - File Distributed 4 (4개 파일로 분산 저장이 기본값)
- File Delimeted
- 기타 옵션
-Dorg.apache.sqoop.splitter.allow_text_splitter=true: 가져올 Table의 Primary Key가 문자열일 경우--split-by order_id: 가져올 table의 Primary Key가 없는 경우
- CLI 예시 (Sqoop으로 MySQL의 employees 테이블 가져오기)
sqoop import \
--connect jdbc:mysql://mysql_server/my_db \
--username jdoe --password bigsecret \
--table customers
기타
Oozie
Oozie는 Hadoop에서 다양한 작업들을 스케쥴링하기 위한 툴로, Batch나 순차적인 실행이 필요한 Job들의 일정을 잡거나 자동화하기 위해 사용한다.
- XML 파일로 정의된 작업을 제출
- Action으로 실행 단위를 구성하고, Action을 모아 워크플로우를 구성
- 다양한 형태의 Action을 제공(Shell, Hive, Sqoop, Spark 등)
- DAG(Directed Acyclic Graph)를 작성하여 작업을 진행
Airflow
Airflow는 Airbnb에서 만든 작업 스케쥴링 툴로, Python 코드를 기반으로 WorkFlow를 작성하고 파이프라인을 구축할 수 있는 것이 가장 큰 장점이다.
실제 데이터 처리 작업을 수행하지는 않고, 이를 위한 구성 요소를 DAG 기반으로 작성하고 관리하기 위한 파이썬 프레임워크로 이해할 수 있다.
HUE
HUE는 Hadoop User Experience의 약자로, 사용자가 Hadoop에 쉽게 접근할 수 있도록 만든 Web UI 기반 프로그램이다.
지금까지 살펴본 바와 같이 Hadoop Ecosystem의 구성요소들은 굉장히 많기 때문에, 개별적으로 사용하고 연동하기 어려운 부분이 있다.
따라서 Web 환경에서 HDFS와 같은 Storage를 직접 조회하거나 Hive, Impala, Spark의 Query 실행, Oozie를 활용한 스케쥴링 등을 한 화면에서 동작하도록 구성하고 편의성을 높여준다.
Reference
- https://inkkim.github.io/hadoop/Hadoop-Ecosystem%EC%9D%B4%EB%9E%80/
- https://mangkyu.tistory.com/129
- https://pyromaniac.me/entry/Hadoop%EC%9D%98-3%EC%9A%94%EC%86%8C-HDFS-MapReduce-Yarn
- https://langho.tistory.com/9
- https://artist-developer.tistory.com/21#google_vignette
- https://geonyeongkim-development.tistory.com/75

댓글남기기