
[Dacon] 제주 퇴근시간 버스 승하차 인원 예측 2 - feature engineering
업데이트:
개요
![]()
이번 포스팅에서는 지난 EDA 포스팅에 이어서 내부데이터와 외부데이터를 이용해서 여러가지 파생변수들을 생성하고, 기계학습이 가능한 형태로 Dataset을 구성해보기로 한다.
Feature engineering
import pandas as pd
import numpy as np
import os
import geopandas as gpd
import sys
from shapely.geometry import *
from shapely.ops import *
import warnings
warnings.filterwarnings(action='ignore')
from fiona.crs import from_string
epsg4326 = from_string("+proj=longlat +ellps=WGS84 +datum=WGS84 +no_defs")
epsg5179 = from_string("+proj=tmerc +lat_0=38 +lon_0=127.5 +k=0.9996 +x_0=1000000 +y_0=2000000 +ellps=GRS80 +units=m +no_defs")
from tqdm import tqdm
from tqdm._tqdm_notebook import tqdm_notebook
tqdm_notebook.pandas()
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib
import matplotlib.font_manager as fm
font_name = fm.FontProperties(fname = 'C:/Windows/Fonts/malgun.ttf').get_name()
matplotlib.rc('font', family = font_name)
import folium
os.chdir(r"D:\Python\dacon_bus_inout\data")
print("path: "+os.getcwd())
print(os.listdir())
path: D:\Python\dacon_bus_inout\data
['bus_bts.csv', 'LSMD_ADM_SECT_UMD_50.dbf', 'LSMD_ADM_SECT_UMD_50.prj', 'LSMD_ADM_SECT_UMD_50.shp', 'LSMD_ADM_SECT_UMD_50.shx', 'LSMD_ADM_SECT_UMD_제주.zip', 'submission_sample.csv', 'test.csv', 'train.csv', 'weather.csv', '제주도_건물정보1.csv', '제주도_건물정보2.csv', '행정_법정동 중심좌표.xlsx']
# dir_ = ""
train = pd.read_csv("train.csv", dtype=str, encoding='utf-8')
test = pd.read_csv("test.csv", dtype=str, encoding='utf-8')
bus_bts = pd.read_csv("bus_bts.csv", dtype=str, encoding='utf-8')
bjd_wgd = pd.read_excel("행정_법정동 중심좌표.xlsx", dtype= str, sheet_name="합본 DB")
sub = pd.read_csv("submission_sample.csv", dtype=str, encoding='utf-8')
print("train :", len(train))
print("test :", len(test))
print("bus_bts :", len(bus_bts))
print("submission_sample :", len(sub))
train : 415423
test : 228170
bus_bts : 2409414
submission_sample : 228170
col_t = [str(j)+"~"+ str(j+1) + "_" + str(i) for i in ("ride","takeoff") for j in range(6,12)]
train['date_dt'] = pd.to_datetime(train['date'])
train[col_t + ['18~20_ride']] = train[col_t + ['18~20_ride']].astype(float)
test['date_dt'] = pd.to_datetime(test['date'])
test[col_t] = test[col_t].astype(float)
bus_bts['geton_datetime'] = pd.to_datetime(bus_bts['geton_date'] + ' ' + bus_bts['geton_time'])
bus_bts['getoff_datetime'] = pd.to_datetime(bus_bts['getoff_date'] + ' ' + bus_bts['getoff_time'])
bus_bts['user_category'] = bus_bts['user_category'].astype(int)
bus_bts['user_count'] = bus_bts['user_count'].astype(float)
파생변수 구성(내부데이터 활용)
1. 시내, 시외 재구분
st_col = ['station_code','station_name','in_out','longitude','latitude']
station_loc = pd.concat([train[st_col], test[st_col]], ignore_index=True).drop_duplicates().reset_index(drop=True)
station_loc[['longitude','latitude']] = station_loc[['longitude','latitude']].astype(float)
station_loc['geometry'] = station_loc.apply(lambda x : Point(x.longitude, x.latitude), axis=1)
station_loc = gpd.GeoDataFrame(station_loc, geometry='geometry', crs=epsg4326)
station_loc = station_loc.to_crs(epsg5179)
print("*버스 정류장 수 :", len(station_loc))
print(station_loc['in_out'].value_counts())
station_loc.head()
*버스 정류장 수 : 3601
시내 3519
시외 82
Name: in_out, dtype: int64
| station_code | station_name | in_out | longitude | latitude | geometry | |
|---|---|---|---|---|---|---|
| 0 | 344 | 제주썬호텔 | 시외 | 126.49373 | 33.48990 | POINT (906519.4860620159 1500237.409276767) |
| 1 | 357 | 한라병원 | 시외 | 126.48508 | 33.48944 | POINT (905715.3864293153 1500194.228393832) |
| 2 | 432 | 정존마을 | 시외 | 126.47352 | 33.48181 | POINT (904633.0709735792 1499358.804023984) |
| 3 | 1579 | 제주국제공항(600번) | 시내 | 126.49252 | 33.50577 | POINT (906424.1528704709 1501998.097362769) |
| 4 | 1646 | 중문관광단지입구 | 시내 | 126.41260 | 33.25579 | POINT (898711.3044004028 1474356.529871264) |
jeju_bjd = gpd.GeoDataFrame.from_file('LSMD_ADM_SECT_UMD_50.shp',encoding='cp949')
if jeju_bjd.crs is None:
jeju_bjd.crs = epsg5179
jeju_main = jeju_bjd.explode().unary_union
jeju_main = jeju_main[np.argmax([i.area for i in jeju_main])].buffer(10).buffer(-10)
#gpd.GeoDataFrame({'geometry':[jeju_main]}, geometry='geometry', crs=epsg5179).to_file("test.shp")
station_loc['in_out_new'] = np.where(station_loc.within(jeju_main),
1,
0)
station_loc['in_out_new'].value_counts()
1 3546
0 55
Name: in_out_new, dtype: int64
- 기본으로 제공되는 시내, 시외 변수가 아닌 제주도 내륙(1)과 이외의 섬들에 위치한 정류장들(0)로 구분
2. 요일 특성(요일별, 주말여부, 공휴일여부)
def get_dayattr(df):
# 0(Monday) ~ 6(Sunday)
df_t = df.copy()
df_t['dayofweek'] = df_t['date_dt'].dt.dayofweek
# 추석, 한글날, 개천절
holiday=['2019-09-12', '2019-09-13', '2019-09-14','2019-10-03','2019-10-09']
df_t['weekends'] = np.where(df_t['dayofweek'] >= 5, 1,0) # 주말여부
df_t['holiday'] = np.where(df_t['date'].isin(holiday), 1,0) # 공휴일여부
return df_t
3. 시간대 통합
def merged_time_col(df, interval=2):
global col_t
df_t = df.copy()
split_n= 6 / interval
n1 = 0
for i in list(map(list,np.array_split(col_t[:6],split_n))):
n1+=1
df_t['ride_' + str(n1)] = df_t[i].sum(axis=1)
n2 = 0
for i in list(map(list,np.array_split(col_t[6:],split_n))):
n2+=1
df_t['takeoff_' + str(n2)] = df_t[i].sum(axis=1)
return df_t
- 기존 1시간 단위 승하차 인원수를 2 또는 3시간 단위로 합쳐서 생성할 수 있도록 구성
4. 버스통행시간(travel time)
delta_ = (bus_bts['getoff_datetime'] - bus_bts['geton_datetime'])
if delta_.dt.days.max() == 0:
bus_bts['travel_time'] = delta_.dt.seconds / 60 # minutes
f_tr_time = bus_bts.groupby(['geton_date','bus_route_id','geton_station_code'])['travel_time'].mean().reset_index()
f_tr_time
| geton_date | bus_route_id | geton_station_code | travel_time | |
|---|---|---|---|---|
| 0 | 2019-09-01 | 17010000 | 6000027 | NaN |
| 1 | 2019-09-01 | 20010000 | 6115000 | NaN |
| 2 | 2019-09-01 | 20010000 | 6115001 | NaN |
| 3 | 2019-09-01 | 20010000 | 6115002 | NaN |
| 4 | 2019-09-01 | 20010000 | 6115003 | NaN |
| ... | ... | ... | ... | ... |
| 484381 | 2019-10-16 | 8180000 | 3074 | 46.716667 |
| 484382 | 2019-10-16 | 8180000 | 3081 | 58.792157 |
| 484383 | 2019-10-16 | 8180000 | 3372 | 53.031667 |
| 484384 | 2019-10-16 | 8180000 | 431 | NaN |
| 484385 | 2019-10-16 | 8880000 | 1579 | 17.371429 |
484386 rows × 4 columns
f_tr_time['travel_time'].isnull().sum()
79775
5. 노선별, 정류소별 배차간격
버스카드 정보 데이터(bus_bts)의 기록을 활용해서, 버스노선별 각 정류장에 도착하는 간격(interval)을 계산하고자 했다.
t_date = "2019-09-02"
test = bus_bts.copy()
test = test[(test['geton_date']==t_date)]
route_ls = test['bus_route_id'].unique().tolist()
import matplotlib.dates as mdates
plot_thresh_hold = 12
row_num = 4
col_num = plot_thresh_hold/row_num
route = route_ls[15]
i=0
plt.figure(figsize=(16,12))
test = test[test['bus_route_id']==route]
for station_ in test['geton_station_code'].unique().tolist():
i+=1
test1 = test[test['geton_station_code']==station_].\
sort_values(by='geton_datetime').\
reset_index(drop=True)
ax = plt.subplot(row_num,col_num,i)
plt.title("route : " + route + " - " + "station : " + str(station_))
ax.plot(range(len(test1)), test1['geton_datetime'], "b.")
ax.yaxis.set_major_formatter(mdates.DateFormatter('%H:%M:%S'))
plt.grid()
if i == plot_thresh_hold:
plt.tight_layout()
plt.show()
break
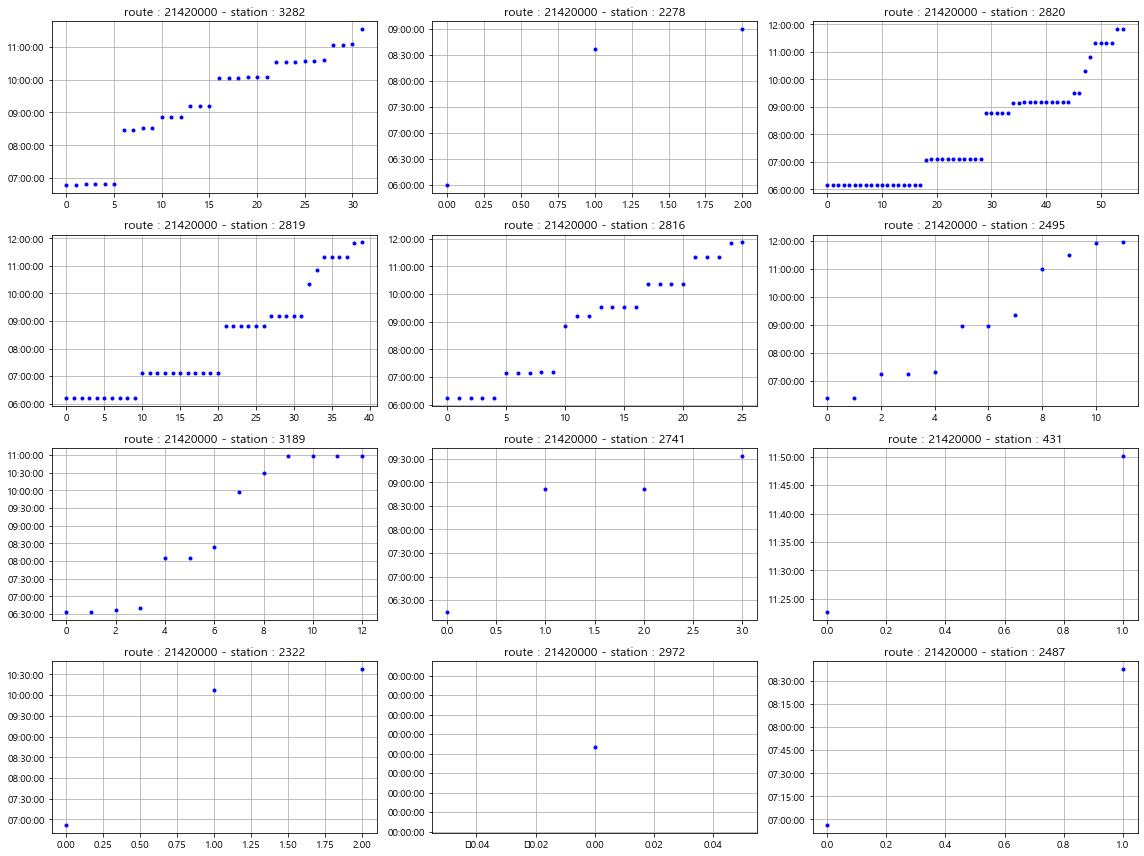
특정 날에 대한 버스 1개노선이 도착한 몇몇 정류장에 승차카드를 태그한 기록들은 위와 같다.
기본 아이디어는 승차태그를 한 시간별로 sorting해서, 바로 이전에 태그한 시간과의 차이를 각각 계산하면 다음번에 버스는 몇분안에 다시 올까? 라는 생각으로 진행했다.
아래는 샘플 test이다.
test1 = test[test['geton_station_code']=='2816'].\
sort_values(by='geton_datetime').\
reset_index(drop=True)
a = test1['geton_datetime'].diff().dt.seconds / 60
a = a.reset_index()
plt.figure(figsize=(9,5))
plt.title("time difference, before geton time", fontsize=15)
plt.plot(a['index'], a['geton_datetime'], "s-")
plt.axhline(y=120, color='r', linewidth=1)
plt.axhline(y=60, color='g', linewidth=1)
plt.axhline(y=3, color='r', linewidth=1)
plt.show()
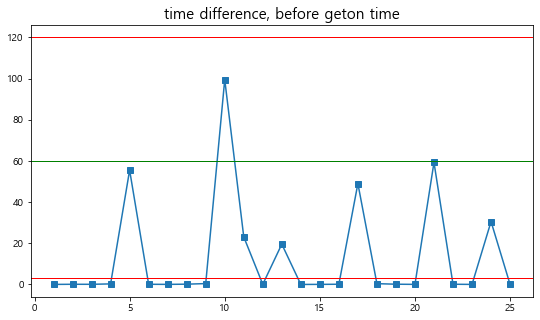
배차간격 계산 방식(rule)
- 일별, 노선별, 정류장별 승차정보에 대하여 승차시간 차이(이전 대비 다음 승차 시간의 차이)의 평균(또는 최소) 값
- 승차시간의 차이가 5분 이상 2시간 이하의 값들에 대해서만 계산(동일버스 승차, 특수한 스케줄을 가진 경우 제외)
- ~결과 값 중 일별 승차정보 count가 가장 많은 날짜로 최종 노선별 정류장별 배차간격 결정~
- 처음에 최대 1시간으로 했는데, 제주도에는 배차간격이 긴 버스(일명 공기수송)가 꽤 있어서 변경
- max 2시간 잡고 결측은 999 표시
즉 위 그래프에서 두 빨간선(0~120) 사이의 데이터의 평균값(또는 최소값) 계산을 통해 일별,버스노선별,정류소별 배차간격을 구하였다.
def get_bus_interval(gr):
stat = gr.sort_values(by='geton_datetime')['geton_datetime'].diff().dt.seconds / 60
stat = stat[(stat >= 5) & (stat <= 120)]
dict_ = {
'all_cnt':len(gr),
'rule_cnt':len(stat),
'min_interval_m' :stat.min(),
'mean_interval_m':stat.mean()
}
return pd.Series(dict_)
result_df = bus_bts.groupby(['geton_date','bus_route_id','geton_station_code']).progress_apply(lambda gr : get_bus_interval(gr))
# result_df.reset_index().to_csv(r'D:\dacon_project1\result\\' + "result_interval_5_120.csv", sep='|', index=False, encoding='cp949')
# result_df = pd.read_csv(r'D:\dacon_project1\result\\' + "result_interval_5_120.csv", sep='|',dtype=str, encoding='cp949')
HBox(children=(IntProgress(value=0, max=484386), HTML(value='')))
result_df[result_df.columns[3:]] = result_df[result_df.columns[3:]].astype(float)
result_df.head()
| all_cnt | rule_cnt | min_interval_m | mean_interval_m | |||
|---|---|---|---|---|---|---|
| geton_date | bus_route_id | geton_station_code | ||||
| 2019-09-01 | 17010000 | 6000027 | 5.0 | 1.0 | 51.066667 | 51.066667 |
| 20010000 | 6115000 | 8.0 | 3.0 | 49.750000 | 57.883333 | |
| 6115001 | 1.0 | 0.0 | NaN | NaN | ||
| 6115002 | 4.0 | 1.0 | 59.816667 | 59.816667 | ||
| 6115003 | 1.0 | 0.0 | NaN | NaN |
result_df.isnull().sum()
all_cnt 0
rule_cnt 0
min_interval_m 288142
mean_interval_m 288142
dtype: int64
result_df = result_df.fillna(999)
6. 시간대별 승차 인원 (bus_bts)
bus_bts['ride_slot'] = bus_bts['geton_datetime'].dt.hour.astype(str) + "~" + (bus_bts['geton_datetime'].dt.hour + 1).astype(str) + "_ride"
ride_slot_pv = pd.pivot_table(bus_bts,
index=['geton_date','bus_route_id', 'geton_station_code'],
columns='ride_slot',
values='user_count',
aggfunc=np.sum).reset_index().fillna(0)
ride_slot_pv = ride_slot_pv[['geton_date','bus_route_id','geton_station_code','6~7_ride','7~8_ride','8~9_ride','9~10_ride','10~11_ride','11~12_ride']]
ride_slot_pv['geton_date'] = pd.to_datetime(ride_slot_pv['geton_date'])
print(str(ride_slot_pv['geton_date'].min().date()) + " ~ " + str(ride_slot_pv['geton_date'].max().date()))
print("%s 건" % len(ride_slot_pv))
ride_slot_pv.head()
2019-09-01 ~ 2019-10-16
484386 건
| ride_slot | geton_date | bus_route_id | geton_station_code | 6~7_ride | 7~8_ride | 8~9_ride | 9~10_ride | 10~11_ride | 11~12_ride |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2019-09-01 | 17010000 | 6000027 | 0.0 | 0.0 | 0.0 | 0.0 | 2.0 | 3.0 |
| 1 | 2019-09-01 | 20010000 | 6115000 | 0.0 | 2.0 | 1.0 | 2.0 | 6.0 | 0.0 |
| 2 | 2019-09-01 | 20010000 | 6115001 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 3 | 2019-09-01 | 20010000 | 6115002 | 0.0 | 0.0 | 1.0 | 4.0 | 0.0 | 0.0 |
| 4 | 2019-09-01 | 20010000 | 6115003 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
- bus_bts 데이터를 피벗해서 train, test셋과 동일하게 구성했을때, 값에 차이가 있음
- train과 test의 버스카드 승차 정보가 전수 존재하는 것은 아닌 것으로 판단됨
- 따라서 일별,버스노선별,정류소를 key로 변수를 구성할때 결측값이 존재
7. 승객 유형별 승차 인원
user_dict_ = {
1:'일반',
2:'어린이',
4:'청소년',
6:'경로',
27:'장애일반',
28:'장애동반',
29:'유공일반',
30:'유공동반'
}
cat_group = bus_bts.groupby(['geton_date','bus_route_id','geton_station_code','user_category'])['user_count'].sum().reset_index(name='sum_cnt')
cat_group_pv = pd.pivot_table(cat_group,
values='sum_cnt',
index=['geton_date','bus_route_id','geton_station_code'],
columns='user_category',fill_value=0).rename(user_dict_, axis=1).\
reset_index()
cat_group_pv.head()
| user_category | geton_date | bus_route_id | geton_station_code | 일반 | 어린이 | 청소년 | 경로 | 장애일반 | 장애동반 | 유공일반 | 유공동반 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2019-09-01 | 17010000 | 6000027 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 2019-09-01 | 20010000 | 6115000 | 6 | 0 | 0 | 4 | 0 | 0 | 1 | 0 |
| 2 | 2019-09-01 | 20010000 | 6115001 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 3 | 2019-09-01 | 20010000 | 6115002 | 1 | 0 | 3 | 1 | 0 | 0 | 0 | 0 |
| 4 | 2019-09-01 | 20010000 | 6115003 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
- 일별, 노선별, 승차 정류소별, 승객 유형별(cols) 승차인원수
외부 데이터(날씨) 활용
기상청 날씨데이터는 제주도의 4개 측정소(제주, 고산, 성산, 서귀포)를 기준으로 기상을 관측한다.
따라서 각 버스정류소와 관측소의 좌표정보를 활용하여, 정류소와 가장 가까운 관측소의 기상정보를 대입시켰다.
그리고 시간대는 오전과 오후로만 구분하여 기상정보의 평균값을 활용했다.
weather = pd.read_csv('weather.csv', encoding='cp949', dtype=str)
weather_t = weather[['지점','일시','기온(°C)','강수량(mm)','풍속(m/s)','습도(%)','지면온도(°C)']].copy()
weather_t['일시'] = pd.to_datetime(weather_t['일시'])
weather_t[weather_t.columns[2:]] = weather_t[weather_t.columns[2:]].astype(float)
weather_t['지점'].unique()
array(['184', '185', '188', '189'], dtype=object)
loc_df = pd.DataFrame([['184', '제주', 126.52969, 33.51411],
['185', '고산', 126.16283, 33.29382],
['188', '성산' , 126.8802 , 33.38677],
['189', '서귀포', 126.5653, 33.24616]],
columns=['지점','지점명','lng','lat'])
loc_df['geometry'] = loc_df.apply(lambda row : Point(row.lng,row.lat), axis=1)
loc_df = gpd.GeoDataFrame(loc_df, geometry='geometry', crs=epsg4326)
loc_df = loc_df.to_crs(epsg5179)
loc_df
| 지점 | 지점명 | lng | lat | geometry | |
|---|---|---|---|---|---|
| 0 | 184 | 제주 | 126.52969 | 33.51411 | POINT (909885.3220605524 1502889.901162671) |
| 1 | 185 | 고산 | 126.16283 | 33.29382 | POINT (875498.2929588766 1478843.189456649) |
| 2 | 188 | 성산 | 126.88020 | 33.38677 | POINT (942354.3571456469 1488522.195599749) |
| 3 | 189 | 서귀포 | 126.56530 | 33.24616 | POINT (912925.9395493728 1473151.188443196) |
weather_t['지점'] = weather_t['지점'].replace(loc_df.set_index('지점').to_dict()['지점명'])
weather_t['cat'] = np.where(weather_t['일시'].dt.hour <= 12, "오전", "오후")
weather_t['date'] = weather_t['일시'].dt.date.astype(str)
weather_t
| 지점 | 일시 | 기온(°C) | 강수량(mm) | 풍속(m/s) | 습도(%) | 지면온도(°C) | cat | date | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 제주 | 2019-09-01 00:00:00 | 23.7 | NaN | 2.0 | 67.0 | 23.1 | 오전 | 2019-09-01 |
| 1 | 제주 | 2019-09-01 01:00:00 | 23.7 | NaN | 2.1 | 67.0 | 23.0 | 오전 | 2019-09-01 |
| 2 | 제주 | 2019-09-01 02:00:00 | 23.5 | NaN | 1.4 | 70.0 | 22.9 | 오전 | 2019-09-01 |
| 3 | 제주 | 2019-09-01 03:00:00 | 23.4 | NaN | 1.1 | 68.0 | 22.6 | 오전 | 2019-09-01 |
| 4 | 제주 | 2019-09-01 04:00:00 | 23.4 | NaN | 1.6 | 69.0 | 22.6 | 오전 | 2019-09-01 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 5759 | 서귀포 | 2019-10-30 20:00:00 | 16.4 | NaN | 1.5 | 77.0 | 14.1 | 오후 | 2019-10-30 |
| 5760 | 서귀포 | 2019-10-30 21:00:00 | 16.2 | NaN | 1.3 | 80.0 | 13.3 | 오후 | 2019-10-30 |
| 5761 | 서귀포 | 2019-10-30 22:00:00 | 15.6 | NaN | 1.6 | 82.0 | 13.3 | 오후 | 2019-10-30 |
| 5762 | 서귀포 | 2019-10-30 23:00:00 | 15.3 | NaN | 1.3 | 84.0 | 12.6 | 오후 | 2019-10-30 |
| 5763 | 서귀포 | 2019-10-31 00:00:00 | 15.0 | NaN | 1.5 | 84.0 | 12.8 | 오전 | 2019-10-31 |
5764 rows × 9 columns
weather_gr = weather_t.groupby(['지점','date','cat']).mean().reset_index()
weather_pv = pd.pivot_table(weather_gr,
index=['지점','date'],
columns='cat',
values=['기온(°C)','강수량(mm)', '풍속(m/s)', '습도(%)', '지면온도(°C)']).reset_index().fillna(0)
weather_pv.columns = ['지점명','date',
'강수_mn','강수_ev',
'기온_mn','기온_ev',
'습도_mn','습도_ev',
'지면온도_mn','지면온도_ev',
'풍속_mn','풍속_ev']
weather_pv.head()
| 지점명 | date | 강수_mn | 강수_ev | 기온_mn | 기온_ev | 습도_mn | 습도_ev | 지면온도_mn | 지면온도_ev | 풍속_mn | 풍속_ev | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 고산 | 2019-09-01 | 0.000000 | 0.800000 | 23.400000 | 22.018182 | 79.230769 | 90.727273 | 23.915385 | 24.454545 | 2.307692 | 2.972727 |
| 1 | 고산 | 2019-09-02 | 6.600000 | 0.700000 | 23.284615 | 26.145455 | 96.769231 | 95.545455 | 23.900000 | 27.881818 | 3.715385 | 3.745455 |
| 2 | 고산 | 2019-09-03 | 3.462500 | 3.866667 | 24.007692 | 25.254545 | 99.461538 | 98.272727 | 25.023077 | 26.700000 | 3.492308 | 2.736364 |
| 3 | 고산 | 2019-09-04 | 9.585714 | 0.266667 | 24.169231 | 24.463636 | 99.461538 | 91.636364 | 24.346154 | 24.436364 | 4.507692 | 4.936364 |
| 4 | 고산 | 2019-09-05 | 0.000000 | 0.000000 | 25.746154 | 27.136364 | 95.230769 | 91.909091 | 25.092308 | 28.345455 | 4.584615 | 4.690909 |
tt_ = pd.DataFrame()
loc_ = ['제주','고산','성산','서귀포']
for i in range(len(loc_)):
sr = station_loc.distance(loc_df.geometry[i]).T
sr.name = loc_[i]
tt_ = tt_.append(sr)
tt_ = tt_.T
station_loc['지점명'] = tt_.idxmin(axis=1)
station_loc['loc_distance'] = tt_.min(axis=1)
station_loc.head()
| station_code | station_name | in_out | longitude | latitude | geometry | in_out_new | 지점명 | loc_distance | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 344 | 제주썬호텔 | 시외 | 126.49373 | 33.48990 | POINT (906519.4860620159 1500237.409276767) | 1 | 제주 | 4285.389734 |
| 1 | 357 | 한라병원 | 시외 | 126.48508 | 33.48944 | POINT (905715.3864293153 1500194.228393832) | 1 | 제주 | 4965.381641 |
| 2 | 432 | 정존마을 | 시외 | 126.47352 | 33.48181 | POINT (904633.0709735792 1499358.804023984) | 1 | 제주 | 6328.885248 |
| 3 | 1579 | 제주국제공항(600번) | 시내 | 126.49252 | 33.50577 | POINT (906424.1528704709 1501998.097362769) | 1 | 제주 | 3574.214065 |
| 4 | 1646 | 중문관광단지입구 | 시내 | 126.41260 | 33.25579 | POINT (898711.3044004028 1474356.529871264) | 1 | 서귀포 | 14265.647562 |
정리
1. 내부데이터
- 시내, 시외 재구분
- 요일특성(요일별, 주말여부, 공휴일 여부)
- 시간대 통합
- 평균 버스통행시간(하차시간 - 승차시간)
- 배차간격
- 승객유형별 승차인원
2. 외부데이터
- 가까운 날씨 측정소 및 거리
- 평균 강수량, 기온, 습도, 지면온도, 풍속 (오전 오후 각각)
View
- 시내, 시외 재구분
- 요일특성(요일별, 주말여부, 공휴일 여부)
- 시간대 통합
train.head()
| id | date | bus_route_id | in_out | station_code | station_name | latitude | longitude | 6~7_ride | 7~8_ride | ... | 10~11_ride | 11~12_ride | 6~7_takeoff | 7~8_takeoff | 8~9_takeoff | 9~10_takeoff | 10~11_takeoff | 11~12_takeoff | 18~20_ride | date_dt | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 2019-09-01 | 4270000 | 시외 | 344 | 제주썬호텔 | 33.4899 | 126.49373 | 0.0 | 1.0 | ... | 2.0 | 6.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 2019-09-01 |
| 1 | 1 | 2019-09-01 | 4270000 | 시외 | 357 | 한라병원 | 33.48944 | 126.48508000000001 | 1.0 | 4.0 | ... | 5.0 | 6.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 5.0 | 2019-09-01 |
| 2 | 2 | 2019-09-01 | 4270000 | 시외 | 432 | 정존마을 | 33.481809999999996 | 126.47352 | 1.0 | 1.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 2.0 | 2019-09-01 |
| 3 | 3 | 2019-09-01 | 4270000 | 시내 | 1579 | 제주국제공항(600번) | 33.50577 | 126.49252 | 0.0 | 17.0 | ... | 14.0 | 16.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 53.0 | 2019-09-01 |
| 4 | 4 | 2019-09-01 | 4270000 | 시내 | 1646 | 중문관광단지입구 | 33.255790000000005 | 126.4126 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 2019-09-01 |
5 rows × 22 columns
- 평균 버스통행시간(하차시간 - 승차시간)
f_tr_time.tail()
| geton_date | bus_route_id | geton_station_code | travel_time | key1 | |
|---|---|---|---|---|---|
| 484381 | 2019-10-16 | 8180000 | 3074 | 46.716667 | 2019-10-16_8180000_3074 |
| 484382 | 2019-10-16 | 8180000 | 3081 | 58.792157 | 2019-10-16_8180000_3081 |
| 484383 | 2019-10-16 | 8180000 | 3372 | 53.031667 | 2019-10-16_8180000_3372 |
| 484384 | 2019-10-16 | 8180000 | 431 | NaN | 2019-10-16_8180000_431 |
| 484385 | 2019-10-16 | 8880000 | 1579 | 17.371429 | 2019-10-16_8880000_1579 |
- 배차간격
result_df.head()
| all_cnt | rule_cnt | min_interval_m | mean_interval_m | |||
|---|---|---|---|---|---|---|
| geton_date | bus_route_id | geton_station_code | ||||
| 2019-09-01 | 17010000 | 6000027 | 5.0 | 1.0 | 51.066667 | 51.066667 |
| 20010000 | 6115000 | 8.0 | 3.0 | 49.750000 | 57.883333 | |
| 6115001 | 1.0 | 0.0 | 999.000000 | 999.000000 | ||
| 6115002 | 4.0 | 1.0 | 59.816667 | 59.816667 | ||
| 6115003 | 1.0 | 0.0 | 999.000000 | 999.000000 |
- 승객유형별 승차인원
cat_group_pv.head()
| user_category | geton_date | bus_route_id | geton_station_code | 일반 | 어린이 | 청소년 | 경로 | 장애일반 | 장애동반 | 유공일반 | 유공동반 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2019-09-01 | 17010000 | 6000027 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 2019-09-01 | 20010000 | 6115000 | 6 | 0 | 0 | 4 | 0 | 0 | 1 | 0 |
| 2 | 2019-09-01 | 20010000 | 6115001 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 3 | 2019-09-01 | 20010000 | 6115002 | 1 | 0 | 3 | 1 | 0 | 0 | 0 | 0 |
| 4 | 2019-09-01 | 20010000 | 6115003 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
- 가까운 날씨 측정소 및 거리
station_loc.head()
| station_code | station_name | in_out | longitude | latitude | geometry | in_out_new | 지점명 | loc_distance | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 344 | 제주썬호텔 | 시외 | 126.49373 | 33.48990 | POINT (906519.4860620159 1500237.409276767) | 1 | 제주 | 4285.389734 |
| 1 | 357 | 한라병원 | 시외 | 126.48508 | 33.48944 | POINT (905715.3864293153 1500194.228393832) | 1 | 제주 | 4965.381641 |
| 2 | 432 | 정존마을 | 시외 | 126.47352 | 33.48181 | POINT (904633.0709735792 1499358.804023984) | 1 | 제주 | 6328.885248 |
| 3 | 1579 | 제주국제공항(600번) | 시내 | 126.49252 | 33.50577 | POINT (906424.1528704709 1501998.097362769) | 1 | 제주 | 3574.214065 |
| 4 | 1646 | 중문관광단지입구 | 시내 | 126.41260 | 33.25579 | POINT (898711.3044004028 1474356.529871264) | 1 | 서귀포 | 14265.647562 |
- 평균 강수량, 기온, 습도, 지면온도, 풍속 (오전 오후 각각)
weather_pv.head()
| 지점명 | date | 강수_mn | 강수_ev | 기온_mn | 기온_ev | 습도_mn | 습도_ev | 지면온도_mn | 지면온도_ev | 풍속_mn | 풍속_ev | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 고산 | 2019-09-01 | 0.000000 | 0.800000 | 23.400000 | 22.018182 | 79.230769 | 90.727273 | 23.915385 | 24.454545 | 2.307692 | 2.972727 |
| 1 | 고산 | 2019-09-02 | 6.600000 | 0.700000 | 23.284615 | 26.145455 | 96.769231 | 95.545455 | 23.900000 | 27.881818 | 3.715385 | 3.745455 |
| 2 | 고산 | 2019-09-03 | 3.462500 | 3.866667 | 24.007692 | 25.254545 | 99.461538 | 98.272727 | 25.023077 | 26.700000 | 3.492308 | 2.736364 |
| 3 | 고산 | 2019-09-04 | 9.585714 | 0.266667 | 24.169231 | 24.463636 | 99.461538 | 91.636364 | 24.346154 | 24.436364 | 4.507692 | 4.936364 |
| 4 | 고산 | 2019-09-05 | 0.000000 | 0.000000 | 25.746154 | 27.136364 | 95.230769 | 91.909091 | 25.092308 | 28.345455 | 4.584615 | 4.690909 |
최종 train & test dataset 생성
train = pd.read_csv("train.csv", dtype=str, encoding='utf-8')
test = pd.read_csv("test.csv", dtype=str, encoding='utf-8')
col_t = [str(j)+"~"+ str(j+1) + "_" + str(i) for i in ("ride","takeoff") for j in range(6,12)]
train['date_dt'] = pd.to_datetime(train['date'])
train[col_t + ['18~20_ride']] = train[col_t + ['18~20_ride']].astype(float)
test['date_dt'] = pd.to_datetime(test['date'])
test[col_t] = test[col_t].astype(float)
bus_bts['geton_datetime'] = pd.to_datetime(bus_bts['geton_date'] + ' ' + bus_bts['geton_time'])
bus_bts['getoff_datetime'] = pd.to_datetime(bus_bts['getoff_date'] + ' ' + bus_bts['getoff_time'])
bus_bts['user_category'] = bus_bts['user_category'].astype(int)
bus_bts['user_count'] = bus_bts['user_count'].astype(float)
set_col = ['date','bus_route_id','station_code']
bus_bts_col = ['geton_date','bus_route_id','geton_station_code']
df_dict_ = {'train':train,
'test':test}
f_tr_time['key1'] = f_tr_time[bus_bts_col].apply(lambda row : "_".join(row), axis=1)
result_df['key1'] = result_df[bus_bts_col].apply(lambda row : "_".join(row), axis=1)
cat_group_pv['key1'] = cat_group_pv[bus_bts_col].apply(lambda row : "_".join(row), axis=1)
for k_ in df_dict_:
# 요일
df_dict_[k_] = get_dayattr(df_dict_[k_])
# 시간대 통합
df_dict_[k_] = merged_time_col(df_dict_[k_], interval=3)
# merging key1
df_dict_[k_]['key1'] = df_dict_[k_][set_col].apply(lambda row : "_".join(row), axis=1)
# bus station 정보
df_dict_[k_] = df_dict_[k_].merge(f_tr_time[['key1','travel_time']], how='left', on='key1')
df_dict_[k_] = df_dict_[k_].merge(result_df[['key1','all_cnt','rule_cnt','min_interval_m','mean_interval_m']],
how='left', on='key1')
df_dict_[k_] = df_dict_[k_].merge(cat_group_pv[['key1','일반','어린이','청소년','경로','장애일반','장애동반','유공일반','유공동반']],
how='left', on='key1')
df_dict_[k_] = df_dict_[k_].merge(station_loc[['station_code','in_out_new','지점명','loc_distance']],
how='left', on='station_code')
df_dict_[k_] = df_dict_[k_].merge(weather_pv.rename({'날짜':'date'},axis=1),
how='left', on=['지점명','date'])
# 결측값 대체
replace_method = 'median'
## key2(일별&노선별)
if not all(df_dict_[k_].isnull().sum() == 0):
for nan_col_ in df_dict_[k_].columns[df_dict_[k_].isna().any()].tolist():
replace_nan = df_dict_[k_].groupby(set_col[:2])[nan_col_].transform(replace_method)
df_dict_[k_][nan_col_] = np.where(df_dict_[k_][nan_col_].isnull(), replace_nan, df_dict_[k_][nan_col_])
## key3(일별)
if not all(df_dict_[k_].isnull().sum() == 0):
for nan_col_ in df_dict_[k_].columns[df_dict_[k_].isna().any()].tolist():
replace_nan = df_dict_[k_].groupby(set_col[:1])[nan_col_].transform(replace_method)
df_dict_[k_][nan_col_] = np.where(df_dict_[k_][nan_col_].isnull(), replace_nan, df_dict_[k_][nan_col_])
df_dict_[k_].to_csv("../result/" + k_ + "_r_set.csv", sep='|', encoding='cp949', index=False)
print("** " + k_ + " **" + " : " + str(len(df_dict_[k_])))
print(df_dict_[k_].isnull().sum(), '\n')
** train ** : 415423
id 0
date 0
bus_route_id 0
in_out 0
station_code 0
station_name 0
latitude 0
longitude 0
6~7_ride 0
7~8_ride 0
8~9_ride 0
9~10_ride 0
10~11_ride 0
11~12_ride 0
6~7_takeoff 0
7~8_takeoff 0
8~9_takeoff 0
9~10_takeoff 0
10~11_takeoff 0
11~12_takeoff 0
18~20_ride 0
date_dt 0
dayofweek 0
weekends 0
holiday 0
ride_1 0
ride_2 0
takeoff_1 0
takeoff_2 0
key1 0
travel_time 0
all_cnt 0
rule_cnt 0
min_interval_m 0
mean_interval_m 0
일반 0
어린이 0
청소년 0
경로 0
장애일반 0
장애동반 0
유공일반 0
유공동반 0
in_out_new 0
지점명 0
loc_distance 0
강수_mn 0
강수_ev 0
기온_mn 0
기온_ev 0
습도_mn 0
습도_ev 0
지면온도_mn 0
지면온도_ev 0
풍속_mn 0
풍속_ev 0
dtype: int64
** test ** : 228170
id 0
date 0
bus_route_id 0
in_out 0
station_code 0
station_name 0
latitude 0
longitude 0
6~7_ride 0
7~8_ride 0
8~9_ride 0
9~10_ride 0
10~11_ride 0
11~12_ride 0
6~7_takeoff 0
7~8_takeoff 0
8~9_takeoff 0
9~10_takeoff 0
10~11_takeoff 0
11~12_takeoff 0
date_dt 0
dayofweek 0
weekends 0
holiday 0
ride_1 0
ride_2 0
takeoff_1 0
takeoff_2 0
key1 0
travel_time 0
all_cnt 0
rule_cnt 0
min_interval_m 0
mean_interval_m 0
일반 0
어린이 0
청소년 0
경로 0
장애일반 0
장애동반 0
유공일반 0
유공동반 0
in_out_new 0
지점명 0
loc_distance 0
강수_mn 0
강수_ev 0
기온_mn 0
기온_ev 0
습도_mn 0
습도_ev 0
지면온도_mn 0
지면온도_ev 0
풍속_mn 0
풍속_ev 0
dtype: int64
- 위 소스코드를 보면 생성했던 변수들을 key(일별,버스노선별,정류소별)로 1차적으로 merge하고, 결측치에 대해서는 key2(일별,버스노선별), key3(일별) 순으로 카테고리를 감소시키며 median 값으로 대체해 주었다.
import matplotlib
matplotlib.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(20,20))
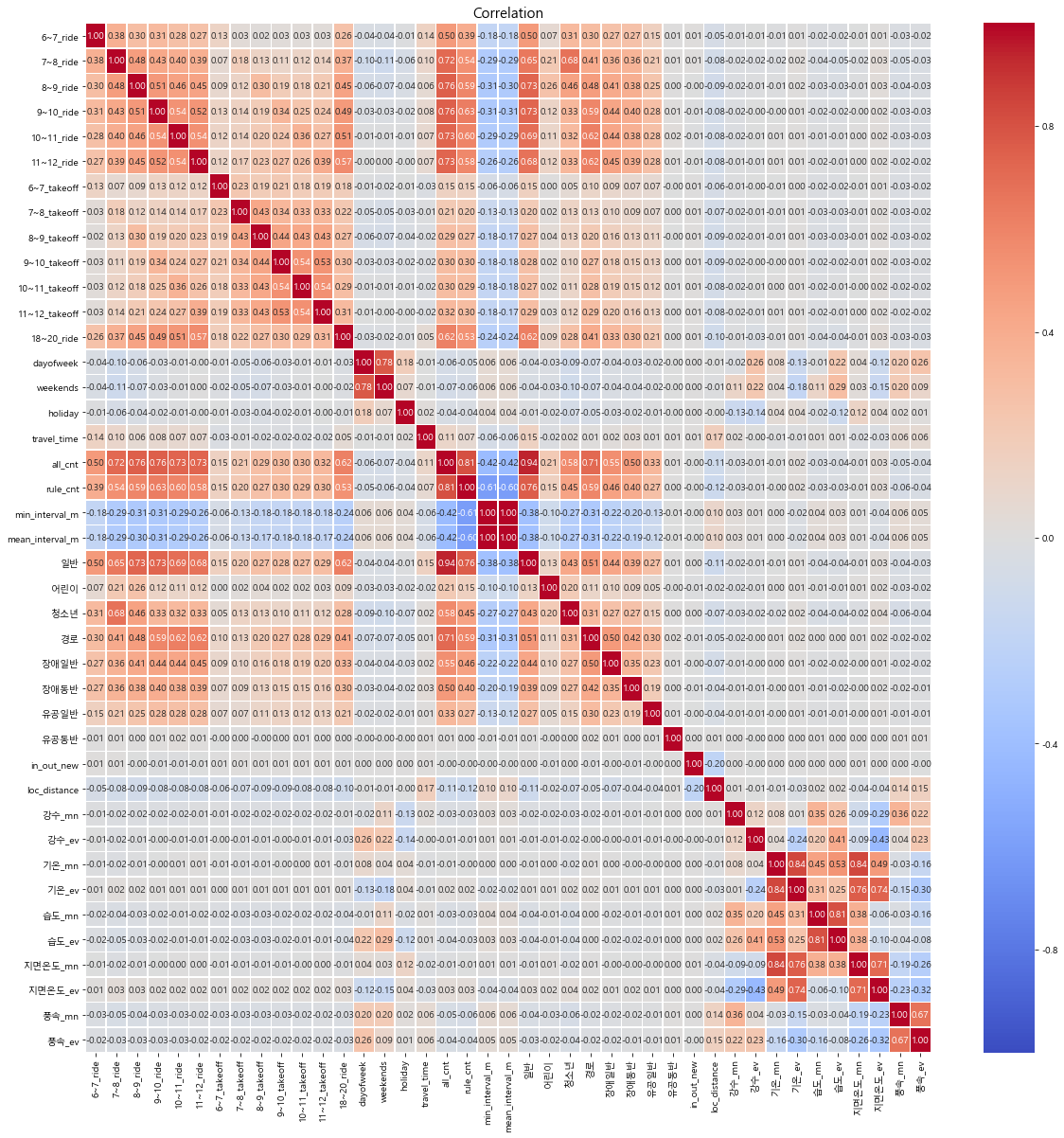
plt.title("Correlation", fontsize=15)
sns.heatmap(data = df_dict_['train'].corr(),
annot=True,
fmt = '.2f', linewidths=.5, cmap='coolwarm',
vmin = -1, vmax = 1, center = 0)
plt.show()

댓글남기기